
Recursion strikes back

The recursion topic has been actively developing over the past year. It feels like it’s becoming a trend that should yield a lot of useful output. Even YCombinator just dropped a video “Recursion Is The Next Scaling Law In AI“ the other day, where they break down HRM (Hierarchical Reasoning Model) and TRM (Tiny Recursive Model) (which we covered half a year ago, here and here respectively) — we’re ahead of YC on important things by half a year! 💪😁
But seriously, I’d like to add a bit to this topic. The video is good if you want to understand the ideas behind HRM/TRM and haven’t gotten around to it yet. And kudos to them for even showing some code to explain things. But the video could have been much better if the authors had given a bit more context.
Historical Context
What’s good is that they start with RNNs, which is valuable, since in the modern world many people think nothing exists beyond transformers. We covered the historical context of HRM here, where, beyond RNNs as a class, there was a lot of important additions about Clockwork RNN and fast-slow weights.
What’s bad is that the video talks about HRM/TRM while completely ignoring important predecessor works.
UT
First, as you might guess, this is my beloved Universal Transformer (2018), which I’ve already talked your ear off about here (and it’s funny they’ve just being patented this year, three years after the application). It’s just plain weird to say nothing about this work when it was one of the first important milestones with recursion in the transformer era.
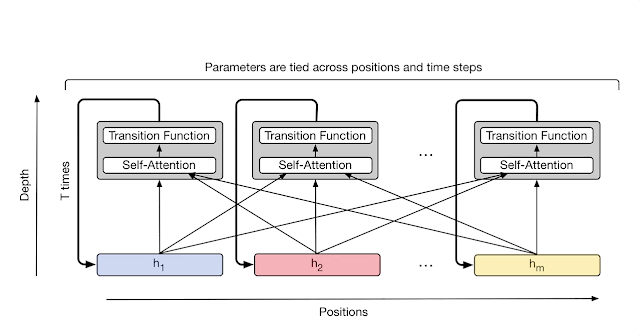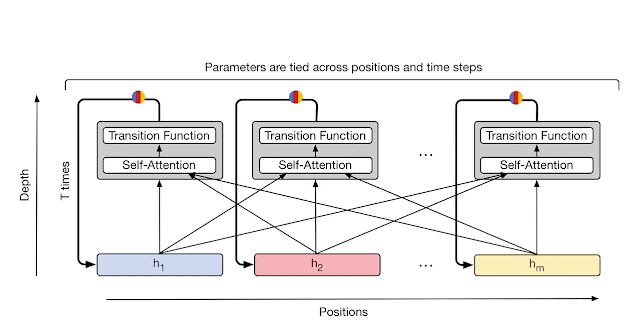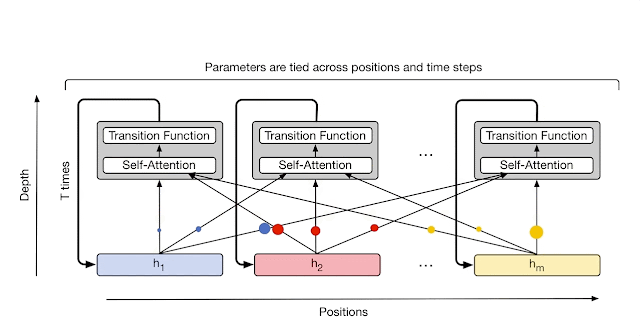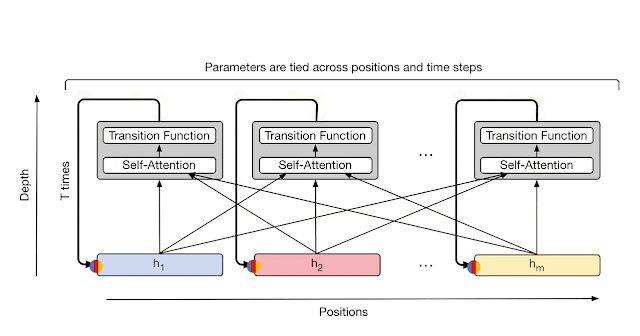
There were also, of course, Transformer-XL (2019) and Compressive Transformer (2019), but for the latter two recursion was over the sequence (which is good for processing long sequences, especially when you have a small context window, as was the case in those years), whereas in UT recursion is over depth, using shared weights of a layer common to all, which is different. That is, for XL it’s more like memory, while for UT it’s computation.
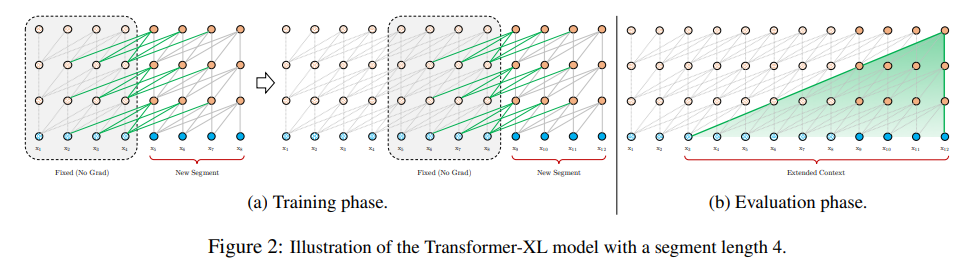
Also in 2019 there was ALBERT aka A Lite BERT, which I see as UT-Lite — also shared weights, meaning the same layer is applied, but there’s no adaptive halting mechanism, the number of recursions (=depth of the transformer) is fixed externally, it just always runs L iterations. UT, in contrast, could decide for each token how long it needed to be processed — simple ones can be quickly run through a few layers and called done, while complex ones can be simmered longer if needed.
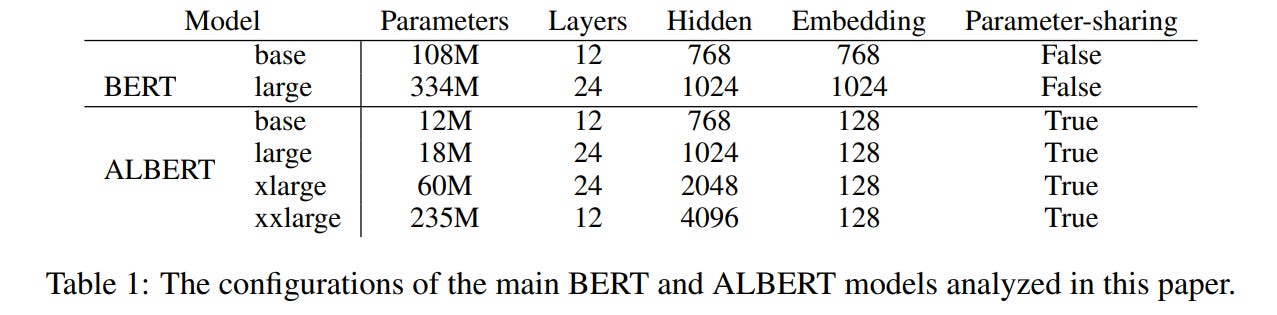
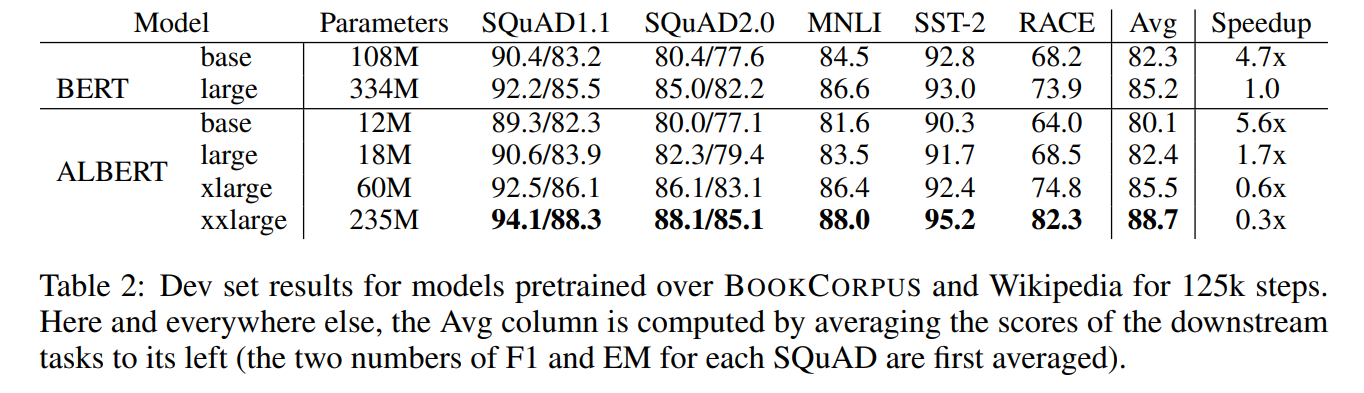
In 2020 I’ve written a post about adaptive computation time in transformers, it covers both UT and ALBERT plus some more.
The HRM paper does cite UT, it’s sort of one of the predecessors, but the TRM paper stays completely silent about it, even though TRM is much more similar to UT than HRM is.

URM
The second big point — at the end of 2025, the URM (Universal Reasoning Model), paper appeared, which we immediately covered then. URM is practically already UT, and of course they couldn’t help but cite it.
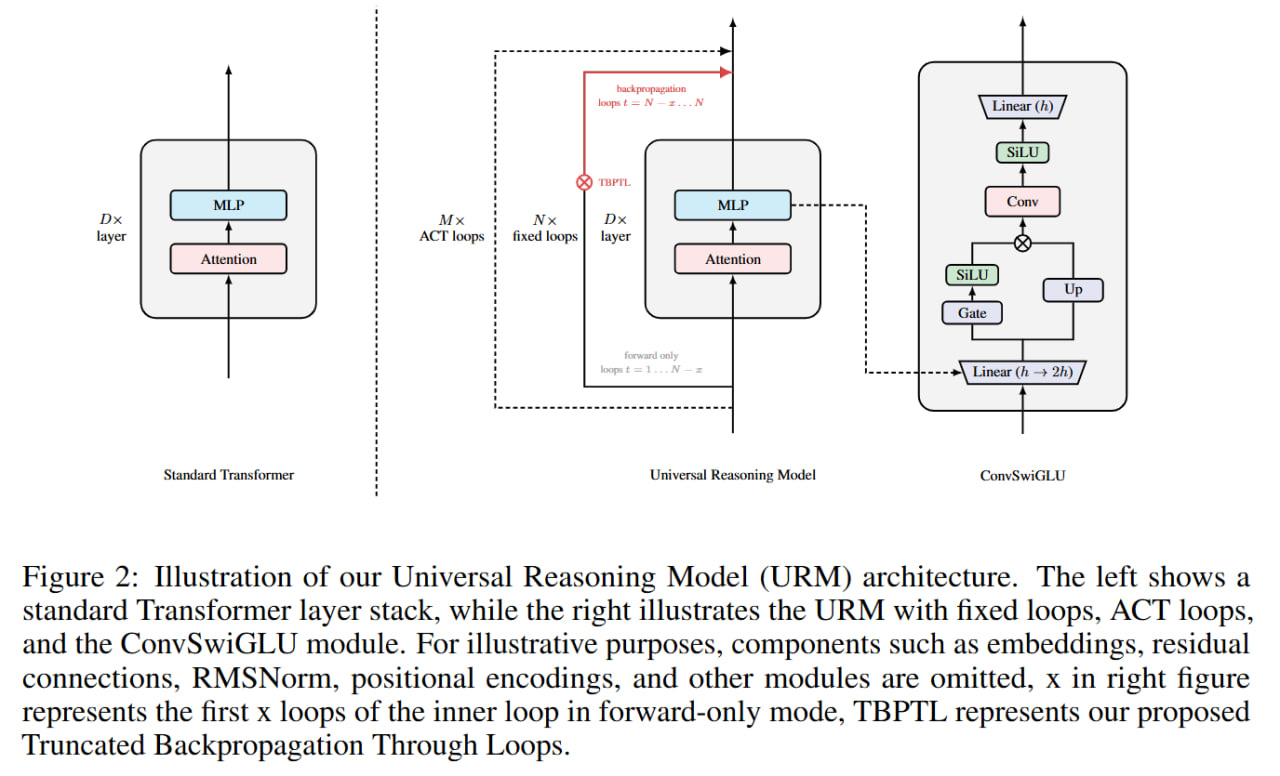
The YC video should have included it, after all almost five months have passed, and the results are arguably better than HRM/TRM. I tried to leave them a comment on YouTube, but all my comments with links got quietly killed by YouTube, I don’t see them 😿
Looped Transformers
And then all the stories about Looped Transformers (which are essentially synonymous with UT) were completely ignored too, and these are already showing up at the scale of small LLMs — the most well-known being Huginn and Ouro.
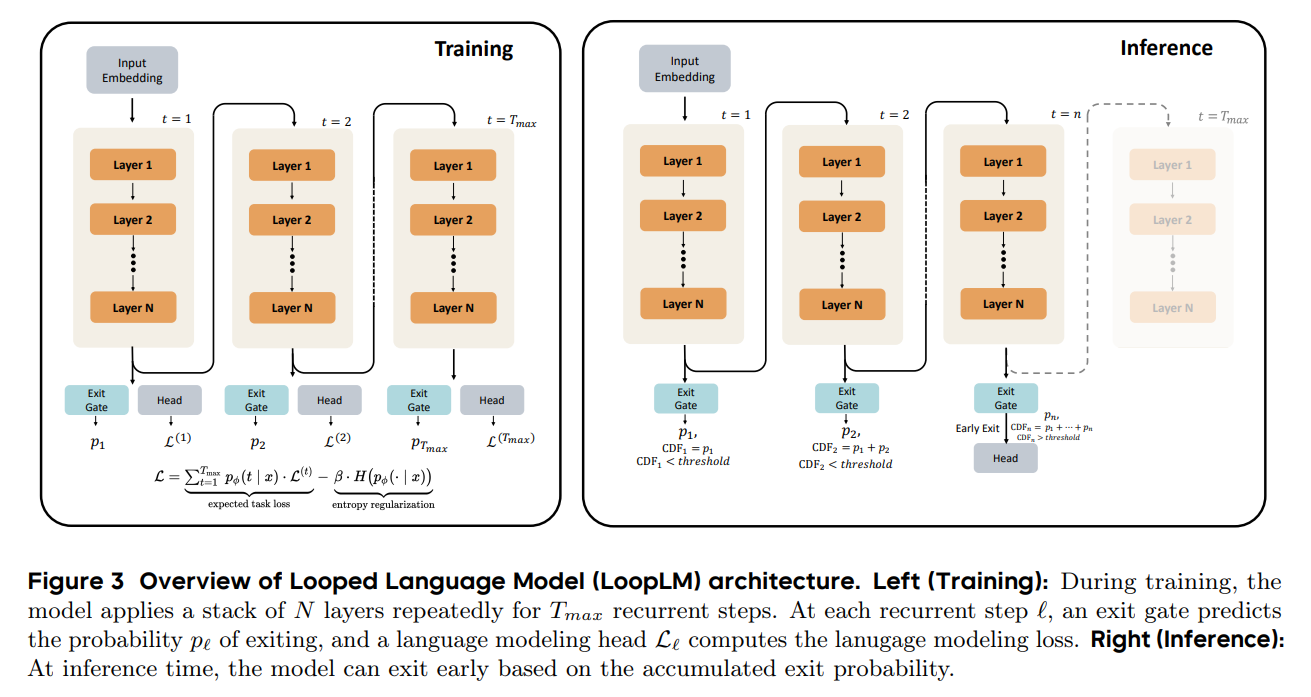
Looped LMs typically repeat not a single layer but a block of layers. In this sense the UT/ALBERT were rather minimal setups with a single shared layer, and LoopLMs are move advanced setups with a shared block of multiple layers.
A few other developments from the last month related to looped models: “Loop, Think, & Generalize”, “ELT: Elastic Looped Transformers for Visual Generation” and “Hyperloop Transformers”. The field is thriving.
To better highlight the difference between all these models, in the new version of my paper on UT+memory I even put together a table (see Table 9 here).

Back to recurrence
Coming back to the recurrence topic — yeah, I also think this is a big deal.
“Iteration is from man. Recursion is from God.” 😁
From the theoretical side, it gets us closer to universal computation. From the more practical side, there are two awesome properties:
Low memory footprint — instead of a model requiring memory for, say, 24 layers, we get a model 24 times smaller (okay, in reality not 24x, since there are also embeddings, but still). For edge and especially wearable devices, it’s a big deal. Especially with the current memory prices 😁

Average retail price of DDR5-5200 16GB x 2 RAM kits between July 2024 and December 2025 [Wikipedia] And as a consequence, we also get rid of constantly loading weights from HBM (or even worse, regular memory, or absolute worst — from disk) into the accelerator’s SRAM, which speeds everything up further. Less data shuffling — more computation, accelerator utilization goes up. Always keep in mind this logarithmic plot.
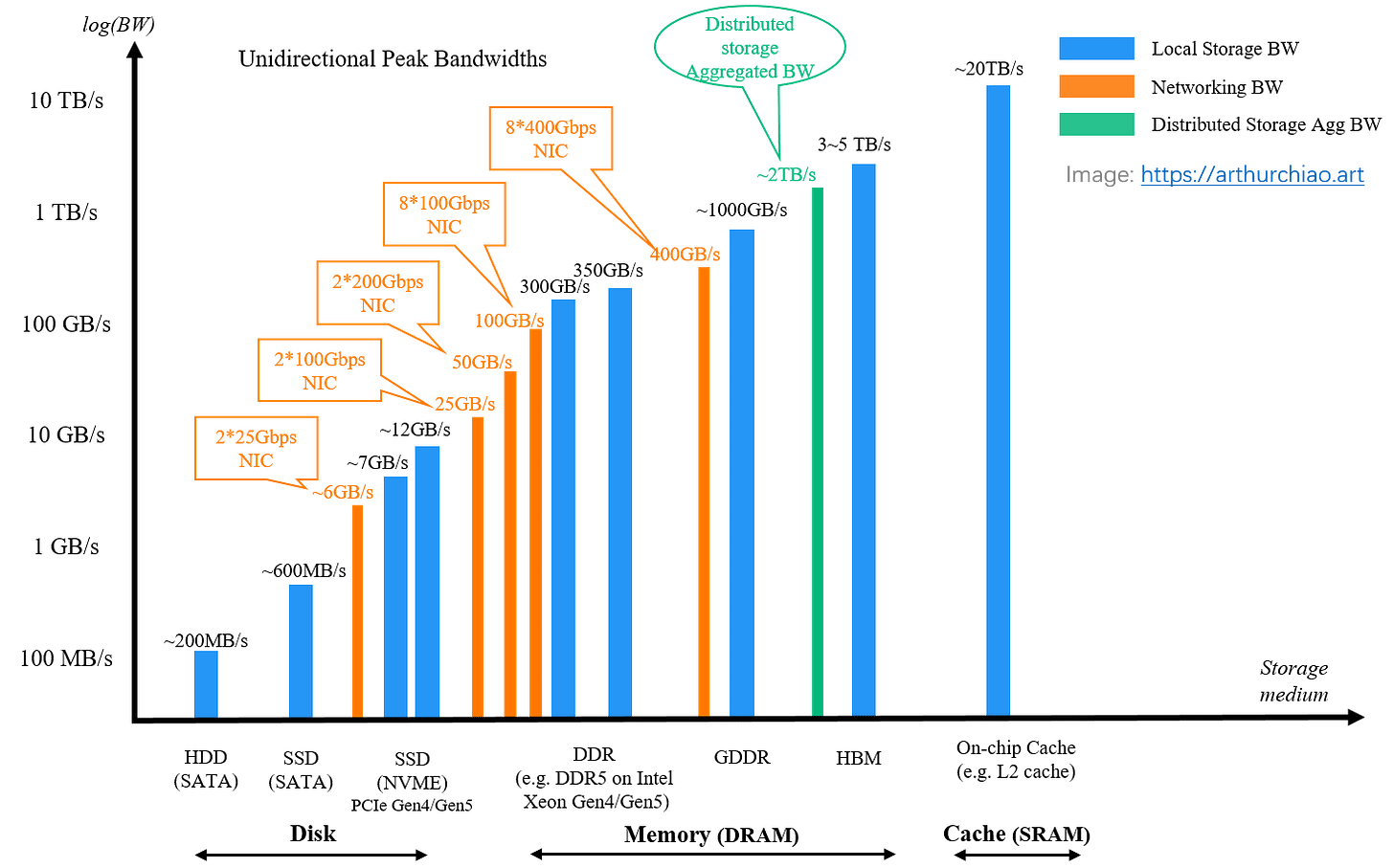
Peak bandwidth of storage media, networking, and distributed storage solutions [source]
Test-time scaling out of the box — you can often run the recursion deeper to get a higher-quality result. In some sense, this is reasoning inside latent space, only realized again over depth rather than over sequence length as in Coconut. And even in my own example with UT+memory on solving Sudoku tasks, the model scales well beyond the number of iterations it was trained on, and continues to improve the result.

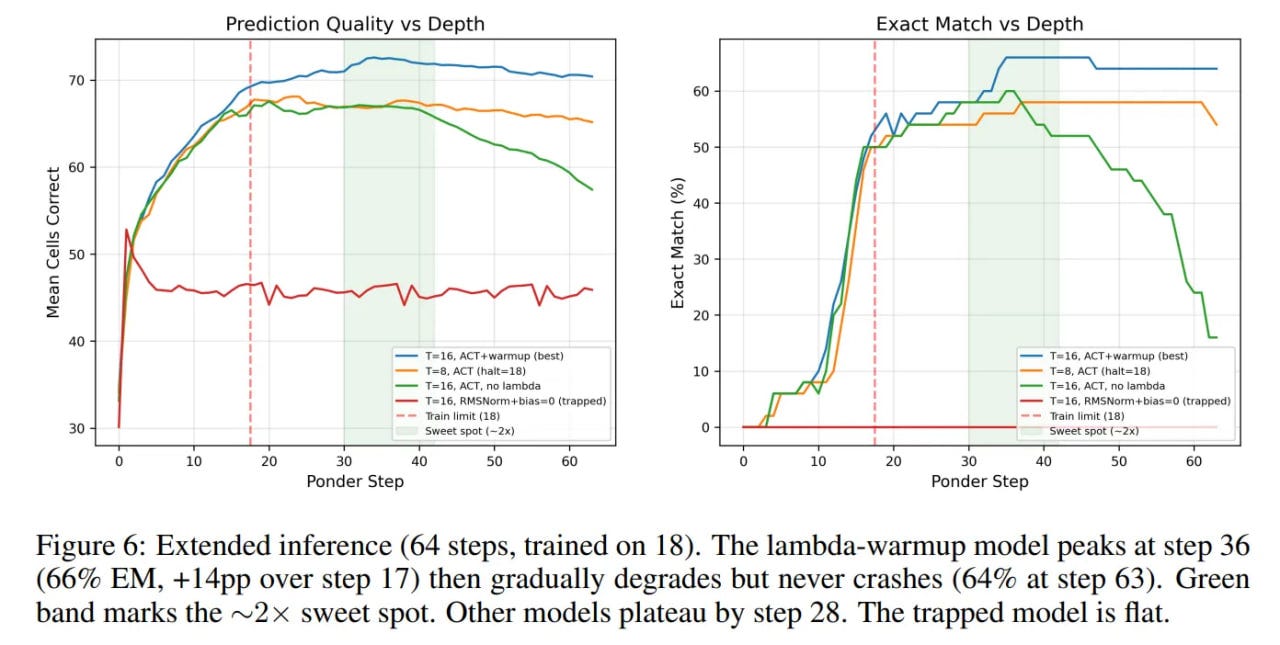
Overall, I personally am waiting for the appearance of really large models with these properties. Surely, of course, in combination with other modern improvements — sparse MoE, mHC [already applied here], low-bit training and quantization (even better for edge!). In my predictions for 2026, I wrote about recurrence somewhat vaguely, just one word, but now I’m making up for it!