
Universal Reasoning Model
I had the same idea, but they had the GPUs

Authors: Zitian Gao, Lynx Chen, Yihao Xiao, He Xing, Ran Tao, Haoming Luo, Joey Zhou, Bryan Dai
Paper: https://arxiv.org/abs/2512.14693
Code: https://github.com/zitian-gao/URM
Good job, guys! They did exactly what I wanted to do myself after the HRM/TRM papers. It was begging to take UT, or essentially ALBERT with ACT, and see what performance could be achieved with it. There was a very strong feeling that HRM/TRM wasn’t necessary to build. My explorations ended when Google credits and GPU machines ran out, along with free time. But theirs resulted in a paper. Nice to be GPU-rich 😭
Recap: HRM/TRM/UT
Let me remind you that Hierarchical Reasoning Model (HRM) proposed a brain-inspired hierarchy of networks with high-level and low-level modules. Subsequent analyses from the ARC-AGI authors showed that perhaps the most important thing in the work was deep supervision, which performed many iterations on a single sample, progressively improving the representation (similar to recycling in AlphaFold). On top of that, adaptive computation time was layered to make this process take no longer than necessary. And the two levels with recursion weren’t needed at all—a regular transformer achieves roughly the same thing. That’s where I wrote that UT or ALBERT is our everything.

Then the simplified Tiny Recursive Model (TRM) came out, which reinterpreted HRM and packaged it all into an almost ordinary recurrent transformer that first updates the internal representation and then refines the answer based on it, with all the same deep supervision on top. The only trainable parameters there were a two-layer network that was applied in all these cycles and gave an effective depth of 42 layers. This is even closer to UT/ALBERT.
Let me briefly remind you about Universal Transformer (UT) and ALBERT. UT (see #3 here) consists of one shared layer that is recursively applied multiple times, progressively improving the embeddings. In the most complete version, the number of times is determined dynamically through Adaptive Computation Time (ACT), which for each specific token decided how much it needs to be processed. I still believe this is a very beautiful and undervalued idea—actually, these two ideas, UT and ACT.
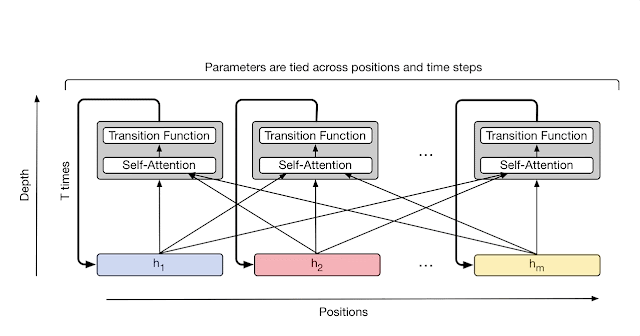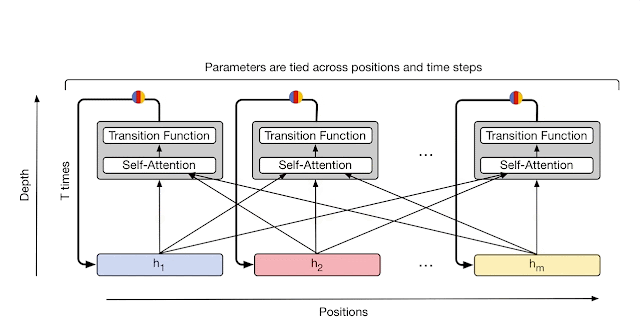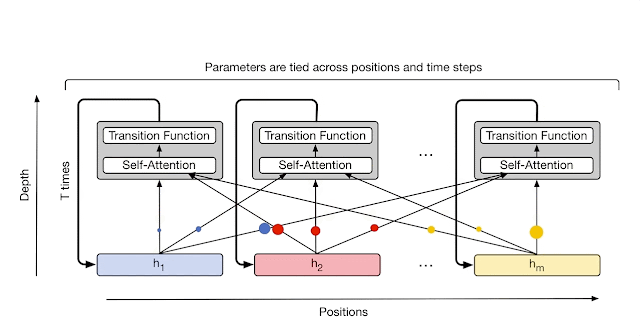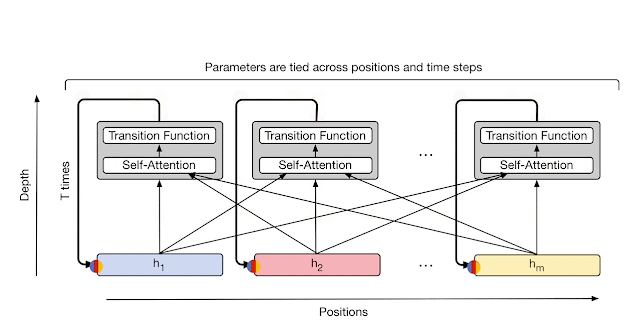
ALBERT (see #3c here) was very similar conceptually to UT with the only difference being that one layer there was applied a fixed number of times and it was a transformer-encoder.
Since HRM and TRM were encoders with ACT, it naturally suggested taking ALBERT+ACT and fine-tuning it to a state where it would give no worse results.
URM: Universal Reasoning Model
The authors of the current work were also inspired by UT and proposed URM (Universal Reasoning Model) based on its template.
They write that they took decoder-only:
”The base architecture of our Universal Reasoning Model (URM) closely follows that of the Universal Transformer, with the difference being its decoder-only design. This aspect is consistent with previous works such as HRM and TRM”
but I think this is an error. HRM/TRM were encoders. In the HRM paper they explicitly say:
“Both the low-level and high-level recurrent modules f_L and f_H are implemented using encoder-only Transformer blocks with identical architectures and dimensions”
TRM is built on it, and there’s no autoregressive generation anywhere, neither in the paper nor in the code. And in general, a decoder isn’t needed for this task—the output size is known in advance and fixed, so an encoder would be logical. So it’s probably a typo.
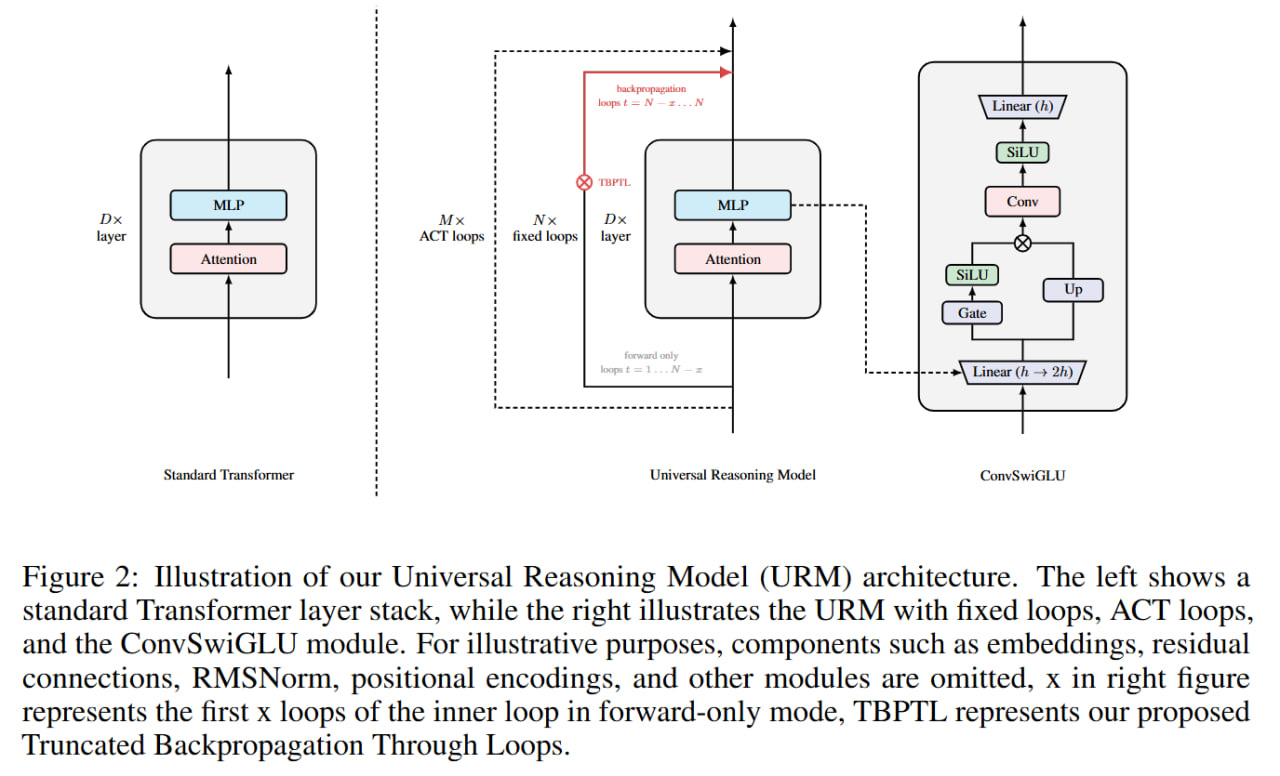
Unlike TRM/HRM, the URM authors made a more custom transformer with ConvSwiGLU and Truncated Backpropagation Through Loops (TBPTL).
ConvSwiGLU
ConvSwiGLU is standard SwiGLU with a short depthwise convolution. Regular SwiGLU works with each token independently; convolution adds local contextual interactions to the gating mechanism, implementing channel mixing for neighboring tokens.
Let me remind you that the already classic SwiGLU is a function with gating. First, for each token, a transformation is computed through matrix Wup:
[G, U] = X Wup ∈ R{T×2m}
Then from G, through the SiLU activation, gate weights are calculated, which are element-wise multiplied with U:
Hffn = SiLU(G) ⊙ U
The authors add a one-dimensional depthwise convolution with kernel k=2 (as I understand it, the current token and previous token) on top of features that have already passed through the gate:
Hconv = σ(Wdwconv * Hffn)
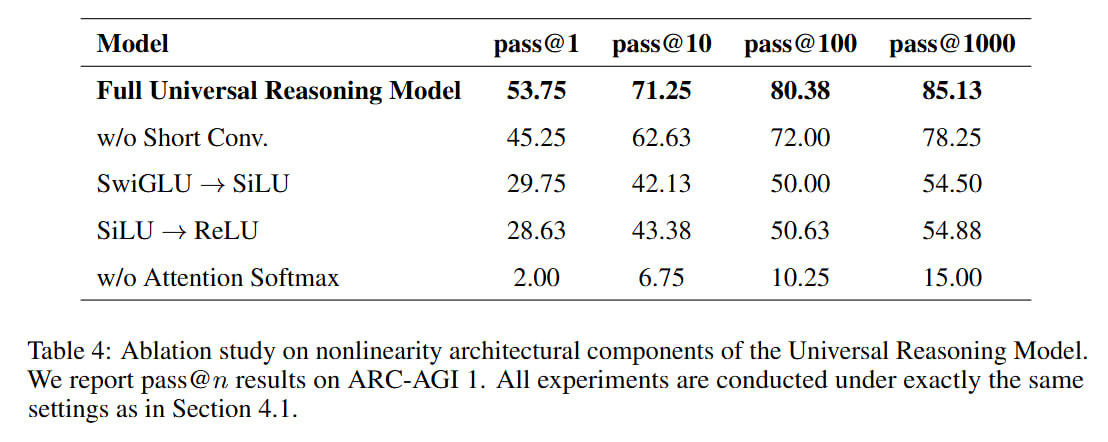
As I understand it, they came to this activation theme after studying ablations that showed that sequentially removing nonlinearity from the activation function monotonically decreases performance on ARC-AGI-1. This, it seems to me, generally agrees with the ranking of the activation functions mentioned there: SwiGLU → SiLU → ReLU. There’s nothing new here that SiLU/swish is better than ReLU, and a function with gating is even better. So they decided to add even more nonlinearity.
In the picture, by the way, they also declare another SiLU, already after the convolution—it’s not in the paper’s formula, but it is in the code.
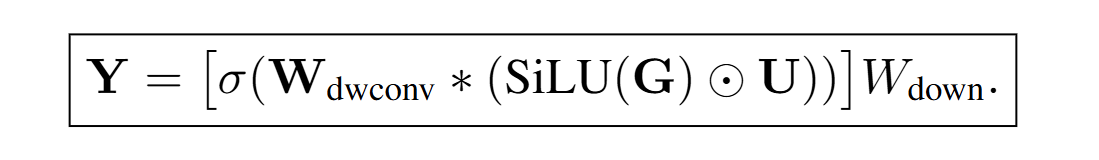
They conducted experiments with convolutions of different sizes; for a kernel size of 2, the best result was obtained. They tried rearranging convolutions in different places in the transformer. Inside the attention mechanism, the position has little effect on anything and sometimes even makes everything worse. The best result (on ARC-AGI) is if you place it after MLP expansion. But this doesn’t quite correspond to the position in the picture—it’s certainly after expansion, but it’s already after the gate too. Maybe they just described all this imprecisely.
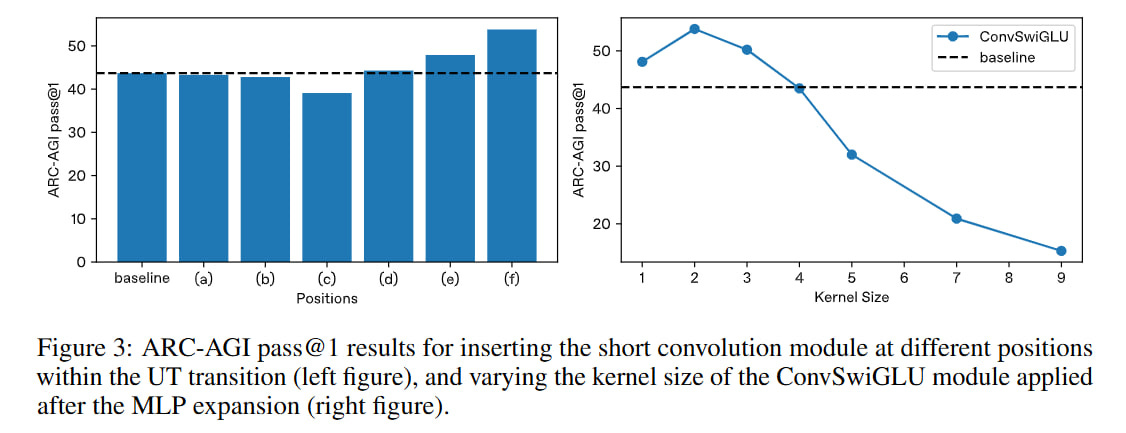
Truncated Backpropagation Through Loops (TBPTL)
TBPTL is needed to limit the depth of recursion; it only computes gradients of late cycles. Inside TRM and HRM there was also similar logic: HRM used gradients only from the last cycle (final state H of the module and final state of the L-module), and TRM during deep recursion ran the internal cycle without tracking gradients for all times except the last. (Also don’t forget that in the highest-level deep supervision loop, output values are detached from the computation graph and passed to the next improvement step simply as input data).
TBPTL does approximately the same thing. If you take a model with D layers and apply it iteratively over M iterations, then new representations htd of layer d ∈ {1, . . . , D} at iteration t ∈ {1, . . . , M} will be computed as a function of htd-1 (previous layer of the same iteration) and hdt-1 (same layer of the previous iteration). Here, by the way, I’m also not sure they wrote this correctly—this thing with the same layer of the previous iteration is somewhat dubious, IMHO. I perceived it as nested loops.
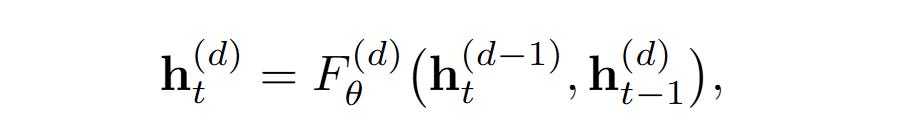
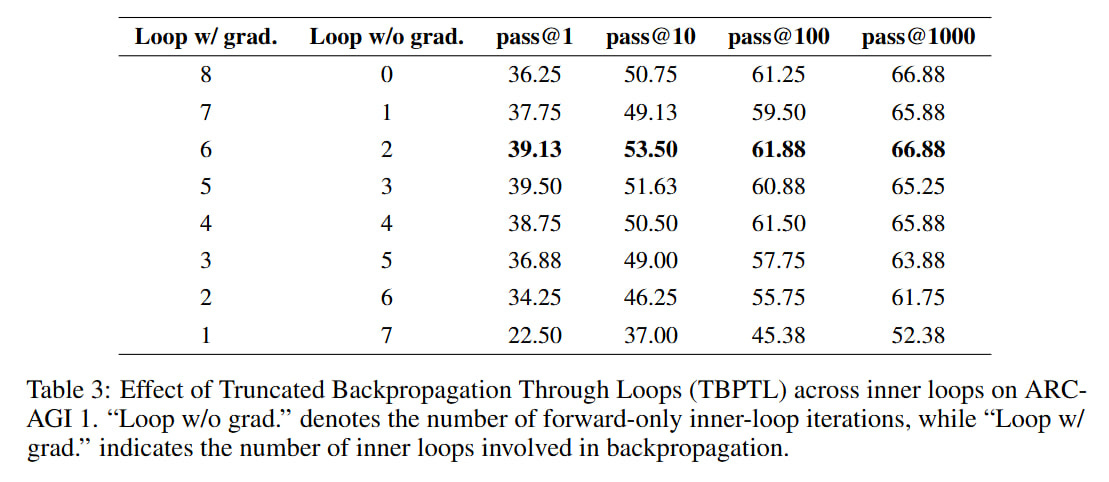
Instead of full backprop through all M iterations, we set a cutoff index N<M, so for all steps from 1 to N, backprop is not done, and for N+1 .. M it is done. Conceptually, absolutely the same logic—in the loss we only account for the last computations.

For example, for a model with D=4 layers and M=8 internal cycles (which in theory is equivalent to 32 layers), with N=2 chosen, only the last 6 cycles (t=3..8) will affect the gradient. This configuration with 6 out of 8 steps was chosen based on trying all variants on ARC-AGI (though this was done on a two-layer model without convolutions, not on a four-layer one with convolutions).
Experiments
The authors took the same datasets and augmentations as TRM/HRM (respect to the original HRM authors for providing reference code on which everyone else could build!).
In TRM (but not HRM), EMA was used (the model trains and updates its parameters, but parallel to this we keep another model that is an exponential moving average of the updated model’s weights, and evaluation is done on this model).
They trained with AdamAtan2 as in the original work. Weight decay also as in previous works. A model with 4 layers of dimension 512 and 8 heads was used. The model size is not mentioned, but based on the code I calculated there are 27.3M trainable parameters, which is comparable to 27M for HRM (TRM was smaller, from 5M to 19M, depending on the task).
In total, the entire processing includes 4 layers at the internal level, 8 iterations (of which only the last 6 participate in backprop), and an outer loop with ACT and a maximum of 16 steps. That is, if I understood everything correctly, it’s like a 4*8*16=512-layer model. Between ACT steps, as I understand it, gradients are not passed, but this part is not described in the paper—need to double-check in the code.
Result: they beat HRM and TRM on Sudoku, ARC-AGI-1, and ARC-AGI-2. Previous works also had Maze-Hard, which wasn’t done here.
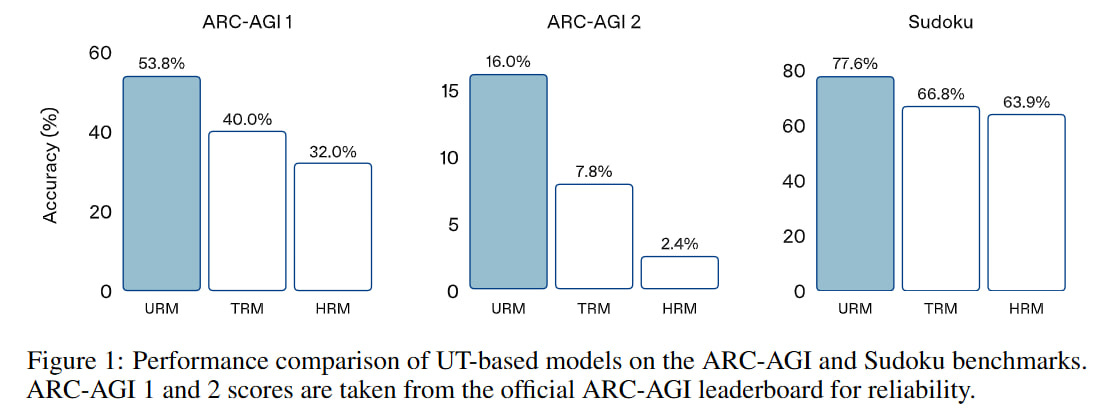
For ARC they provide scores for pass@1, @10, @100, and @1000; for Sudoku only pass@1. About ARC, it looks strange—I thought that in previous works the evaluation was set up so that 1000 augmentations were generated, but from them the two most frequent results were selected, by which ARC was evaluated (that is, sort of pass@2). Here it’s written that n answers were sampled and a sample was considered correct if at least one answer was correct, meaning for n=1000 this is really pass@1000, which is incomparable with previous works. It seems to make sense then to look only at pass@1.
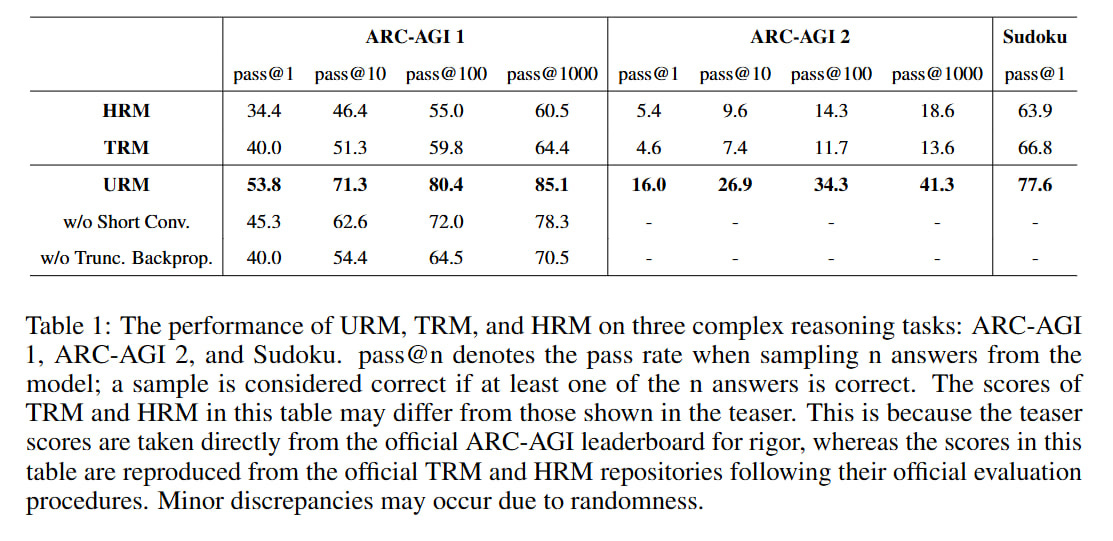
Interestingly, the scores differ noticeably from the scores in the HRM/TRM papers. For example, for Sudoku, the HRM and TRM results were 87.4/74.7 (TRM had two different versions, with MLP and SA) and 55.0 respectively. Here in the paper, the scores of these models are 63.9 and 66.8, which is interesting because, first, it’s noticeably less for TRM, and second, the difference between them became extremely small. URM has a score of 77.6, which is higher than the TRM/HRM numbers from the current work but lower than the original TRM work. On ARC-AGI-2, here HRM is generally higher than TRM, which was obviously different in the TRM paper, and also different in the picture from the beginning of the paper, where they explicitly say they took the numbers from ARC-AGI.
Something’s murky here, need to look very carefully. It’s completely unclear how to compare with previous works. The only hope is for the ARC team themselves to measure fairly.
Interestingly, the authors ran many variants of regular transformers and a couple of UT variants on ARC-AGI-1 and showed the numbers.

UT with 4 layers and 8 cycles noticeably beats a vanilla transformer with 32 layers that has the same amount of computation and 8 times more parameters. I just didn’t understand what’s going on with ACT here—is this cycle equal to 1? It seems to turn out that iterative computations are better than adding layers (echoes https://arxiv.org/abs/2502.17416). Does the recurrent inductive bias of UT better suit such tasks?
For a complete bingo, the authors tried the Muon optimizer (I did the same thing).
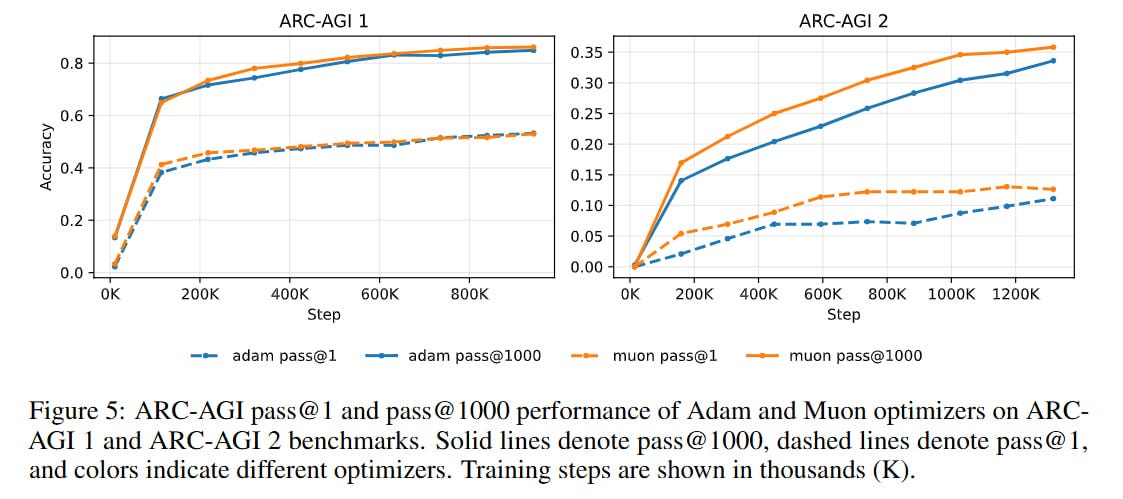
Muon gave faster convergence, almost twice as fast on ARC-AGI-2, but the same final result. With Muon, though, the devil is in the details—which layers it’s applied to, with what exact hyperparameters. The paper has no details, need to dig into the code (provided it corresponds).
Thoughts converge. And I’m very much looking forward to verification from ARC-AGI. Maybe the next time I will have enough GPU… I still have some ideas 😁
I had the same idea, but someone had a newsletter to prove it!