

(Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts
(Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts

Authors: Minghao Wu, Yulin Yuan, Gholamreza Haffari, Longyue Wang
Paper: https://arxiv.org/abs/2405.11804
Repo: https://github.com/minghao-wu/transagents
Over the past year or two, practices in working with Large Language Models (LLMs) have significantly evolved. Initially, it all started purely with LLMs, prompts, and various strategies around them (like CoT and others). Then came LLM Programs, and frameworks like LangChain, Semantic Kernel, and Prompt Flow developed. Next, we saw multi-agent stories like LangGraph, CrewAI, and others. SOM is also somewhere nearby, and development continues in each branch.
Today, let's talk about multi-agent work using the example of translation. Incidentally, Andrew Ng recently contributed to this field, releasing the Translation Agent: Agentic translation using reflection workflow. Here, an agent first performs the translation, then reflects on it, and subsequently makes an improved translation based on this reflection. This can be considered a significantly lighter version of what we will discuss today.

Enter TransAgents
In this study, the authors assembled a virtual (for now) multi-agent company called TransAgents, specializing in literary translation. The work is not reproducible, as important artifacts like code and prompts are absent. However, this doesn't diminish its interest.
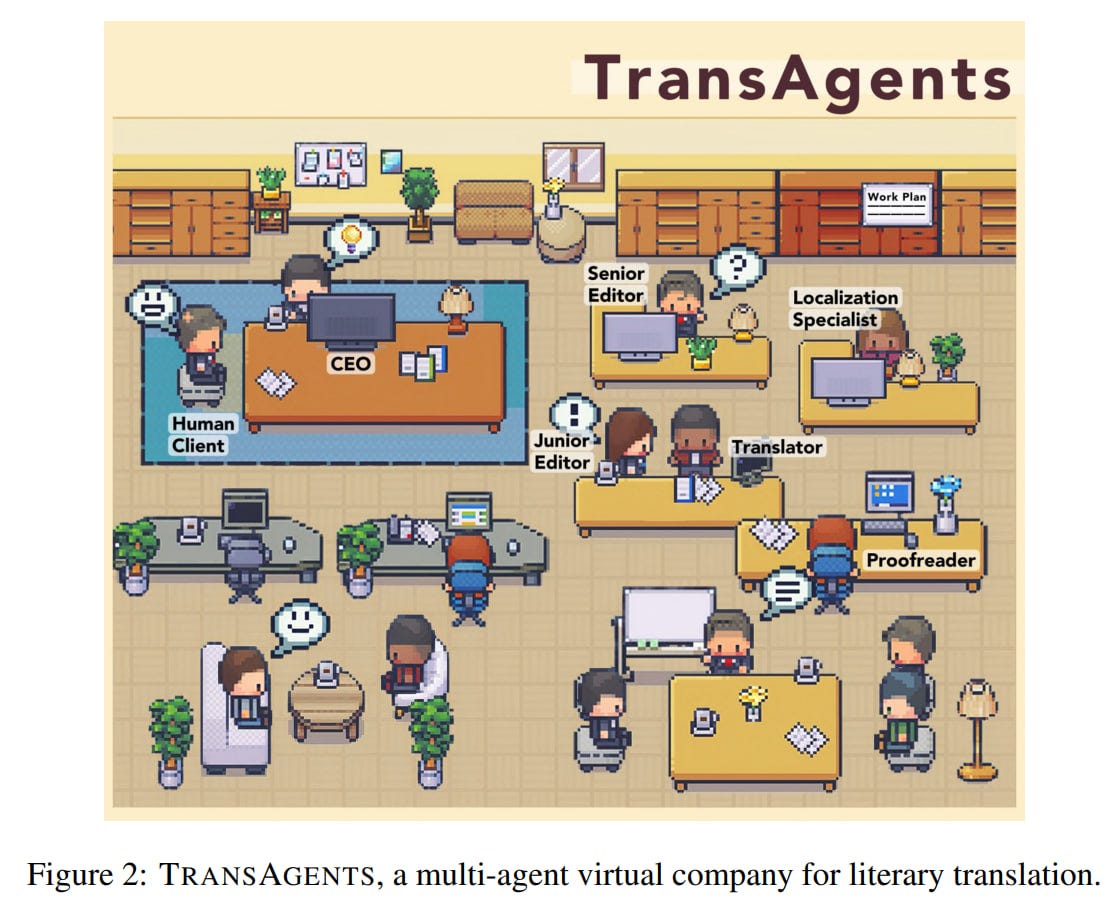
Roles in the company: CEO, Senior Editor, Junior Editor, Translator, Localization Specialist, Proofreader. For each role, 30 diverse profiles were generated using GPT-4 Turbo. These profiles include attributes related to translation (language knowledge, experience, education, rate per word) as well as non-translation-related attributes (hobbies, persona, age, gender, nationality). It would be interesting to analyze how this influences the results.

The study uses two collaboration strategies: Addition-by-Subtraction Collaboration and Trilateral Collaboration.
Addition-by-Subtraction Collaboration, unlike typical debate strategies where different agents propose their solutions and a separate agent finalizes it, involves only two participants. The first agent (addition) strives to extract all relevant information and add it, while the second agent (subtraction) reviews, detects redundancies, and provides feedback to the first. The interaction continues as long as revisions are needed.
Trilateral Collaboration involves three active branches: Action, Critique, and Judgment, with each assigned to an agent. The actor produces the result, the critic critiques it and adds to the interaction history, which the actor can consider in generating an updated response in the next iteration. The judge, at the end of each (after the first) iteration, reviews the response and decides whether to continue the discussion or conclude it.

The company's process is two-tiered, consisting of preparation and execution phases, functioning as follows:
1. Preparation phase: A human client comes with a request for literary text translation. At this moment, the appointed CEO agent selects (using self-reflection) the Senior Editor suitable for the client's specific request.
For translation, a translation guideline of five components needs to be prepared, including a glossary, summary, tone, style, and target audience.
Key terms for the glossary are collected in the Addition-by-Subtraction mode, where the Junior Editor (addition agent) adds all important terms, and the Senior Editor (subtraction agent) removes common words. The Senior Editor then translates them considering the context. Summaries of chapters are collected similarly, and the Senior Editor compiles them into a book summary. The Senior Editor also determines the tone, style, and target audience using a randomly selected chapter.
The compiled guideline is used as an essential part of the prompts for all roles involved in the subsequent translation, ensuring consistency and coherence throughout the work.
2. Execution phase: This phase is divided into four sub-stages: translation, cultural adaptation, proofreading, and final review. The first three operate in Trilateral Collaboration mode, with the Translator, Localization Specialist, and Proofreader as the Action agents, and the Junior Editor and Senior Editor as the Critique and Judgment agents. In these phases, the content is translated (by chapters), adapted culturally, and proofread for errors.
The final stage is the final review, where the Senior Editor evaluates the quality of each chapter and how one chapter transitions to the next.
The Judgment agent is considered crucial for maintaining translation quality because models do not handle long contexts well, and the meaning of translations starts to deviate from the original after several review iterations. The judge does not use the entire review history, thus helping maintain the final quality.
Experiment
All agents are based on GPT-4 Turbo (gpt-4-1106-preview).
The experiment is based on the discourse-level literary translation (DLLT) task from WMT2023.
Baselines include Llama-MT (Llama fine-tuned on literary translation), GPT-4 (with translation by individual chapters), Google Translate (with translation by sentences), DUT, and HW-TSC from WMT23.
The test set from WMT2023 includes 12 web novels, each with 20 chapters, totaling 240 chapters.
The authors performed a Standard Evaluation (as for regular MT) through document-level BLEU (d-BLEU) and Preference Evaluation. BTW, we at Intento just published our brand new annual The State of Machine Translation 2024 report. It’s the best place to understand what is happening in the machine translation field and how to approach it when needed.
Interestingly, TransAgents scored significantly lower on d-BLEU (25 versus 43-52 for the baselines). However, BLEU is far from ideal even for regular translations, let alone literary translations, where the same thing can be said in completely different words, and a universal translation may not exist. Also, there are many questions about the references against which it is calculated. Thus, this metric's low value here says little by itself.
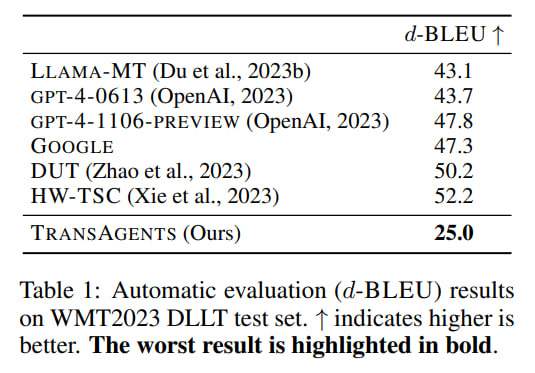
Therefore, two other evaluation methods were used. The authors proposed Monolingual Human Preference (MHP) and Bilingual LLM Preference (BLP). Both compare two translation options and choose the best. Each method outputs a winning rate in percentage, indicating how often the current system's output was preferred over another.
Monolingual Human Preference (MHP) is based on human evaluation (via SurveyMonkey), where the evaluator is not shown the original text in the source language. Each chapter was manually segmented into approximately 150-word pieces, which were given for evaluation. Each evaluator sequentially assessed all segments of a specific chapter to account for the full context and because segments might depend on each other.

Bilingual LLM Preference (BLP) uses an LLM (gpt-4-0125-preview, a different model to reduce bias) instead of a human. It is prompted with the source text and two translations to choose the better one. It works segment-wise, not by full chapters. Each pair (segment and its translation) was evaluated both directly and in reverse (although it's unclear where two translation options come from in reverse). There are no details about the evaluation prompt (only its beginning), and it's unclear whether they immediately asked which was better or broke it down by problem types like in the MQM framework (we use it in our own LLM-based metric Intento LQA).

Both evaluations were performed on the first two chapters of each of the 12 novels. As human evaluation is expensive, MHP was compared only with gpt-4-1106-preview and human Reference 1 from the dataset (there is also Reference 2).
TransAgents translations were slightly preferred in both evaluations compared to the reference or GPT-4. BLP especially preferred TransAgents over Reference 1 (approximately 66% versus 30%).
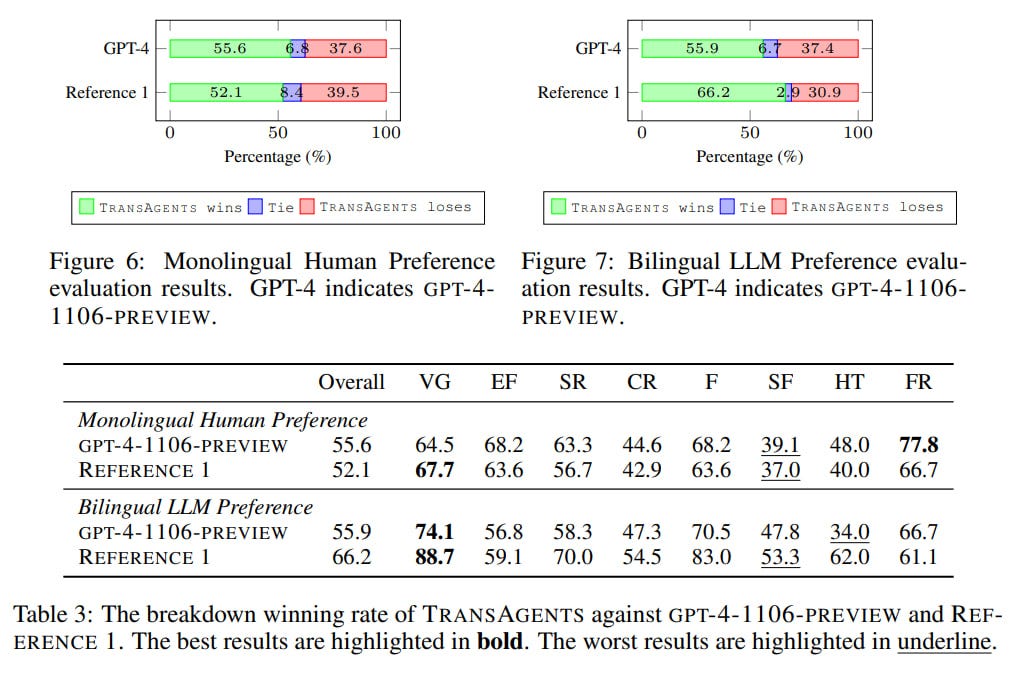
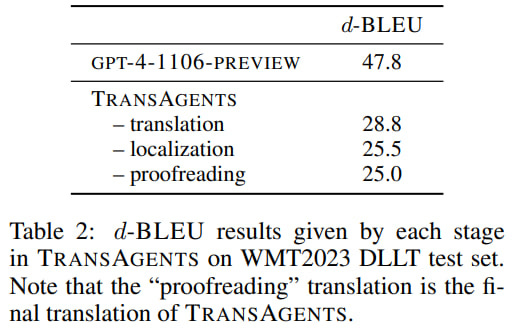
The authors examined a bit deeper the standard evaluation with d-BLEU and evaluated translations at different process stages. Direct translation through gpt-4-1106-preview (the same model used by agents) gives a high score of 47.8, translation by agents is scored 28.8, and then the score further decreases at localization and proofreading stages. The authors believe the initially low translation scores are significantly influenced by the guideline.
The original texts span different genres, and more detailed analysis showed that TransAgents performs best in areas requiring extensive domain knowledge, like historical context or cultural nuances (which are also significant challenges for translators). The system performs worse in Contemporary Romance (CR), Science Fiction (SF), and Horror & Thriller, where such knowledge is seemingly unnecessary.
They also assessed Linguistic Diversity using Moving-Average Type-Token Ratio (MATTR) and Measure of Textual Lexical Diversity (MTLD). The system scores better than the baselines.
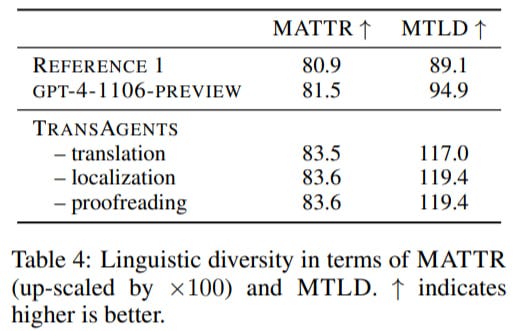
The cost estimate for TransAgents is $500 for the entire test set or approximately $2.08 per chapter. The human work estimate is $168.48 per chapter.
The study includes a case study analyzing specific properties, problems, and features of TransAgents. The system performed better than vanilla gpt-4-1106-preview (and better than the human reference, but the source of this reference is questionable) in cultural adaptation, exemplified by the translation of names and titles.

Also, TransAgents (like the reference) was better than pure GPT in the consistency of chapter title translations. However, both GPT and TransAgents made omissions.
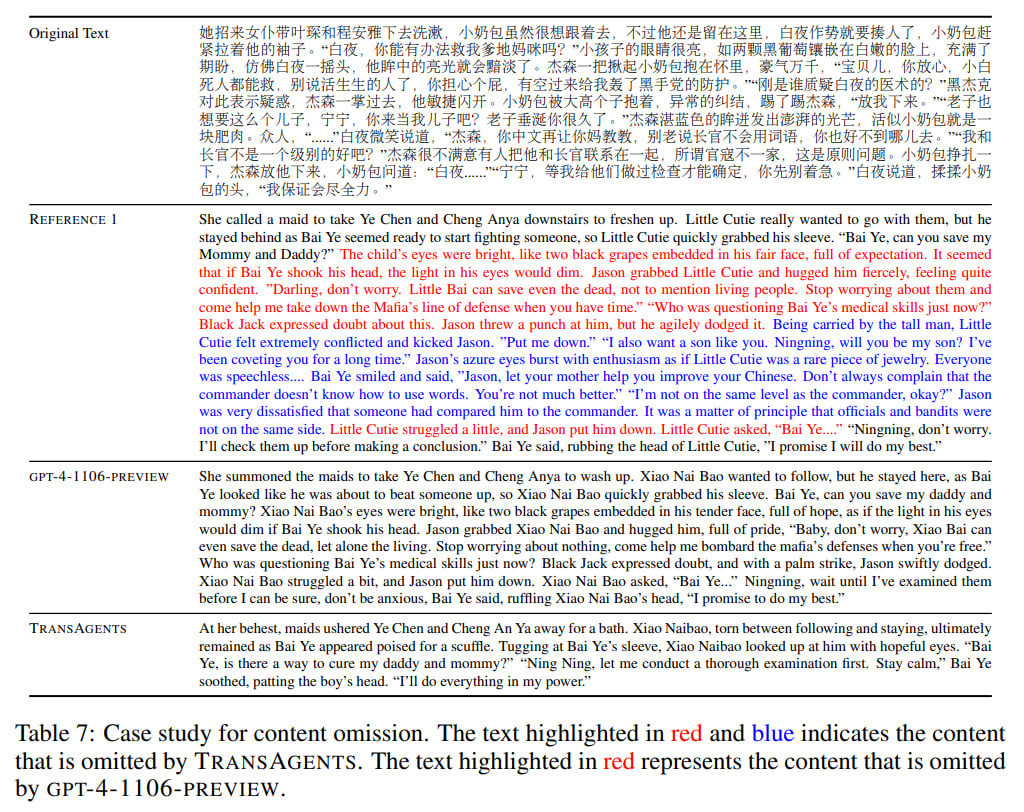
In a blind evaluation of one chapter by two professional translators among TransAgents, Reference 1, and gpt-4-1106-preview, they characterized TransAgents translations as having a novel-like expressive style using rich language but sometimes losing parts of the original text. They rated it as the most expressive and captivating, while Reference 1 and gpt-4-1106-preview were deemed the most traditional.

The authors highlight problems with the approach, mainly in the evaluation part. Evaluating large texts is challenging (and expensive), and the segmentation used (not necessarily the best) somehow influences the results. The scale of the study was small, with no guarantees that the target audience was correctly selected. There are also questions about the origins of the references. All this remains for future work.
In any case, the work is interesting. Imagining a working system of this kind even a couple of years ago was problematic, and now multi-agent systems have grown to quite functional operability. What we see are just the first signs. Another such sign for me was Generative Agents, but there are now many works of this kind — a fresh Agent Hospital, Automated Social Science, assistance in software development, and much more. Within a year or two, we will see many more working cases, a rich practice of working with such systems will form, effective patterns will stabilize, and improved models will add quality. Those who studied to be prompt engineers will need to retrain as agent coordinators.
It's also interesting to see when the first purely virtual agency (with such type of agents) with viable economics will appear. Ideally, one where no human is needed, except perhaps to reboot the server once every six months :) I think we're already at that point; it can be done.