
Generative Agents: Interactive Simulacra of Human Behavior
Getting closer to "The Thirteenth Floor"...

Authors: Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein
Paper: https://arxiv.org/abs/2304.03442
Code: https://github.com/joonspk-research/generative_agents
A very interesting paper from Stanford and Google.
In a novel endeavor, researchers have developed generative agents that simulate human behaviors. These agents lead their own lives, going through daily routines such as waking up, preparing breakfast, heading to work, and so on. They engage with other agents, retain memories, and strategize for the upcoming day.

The agents are hosted in a sandbox environment named 'Smallville', modeled after a small town. This town comprises houses, a college, shops, parks, cafes, and more. Inside the houses, individual rooms are equipped with items like tables and wardrobes. The entire world is depicted as a tree structure, with its leaves representing individual objects.
This world is visualized in the form of a 2D sprite-based game built on Phaser. The dedicated server handles the transfer of the world's state to agents and oversees the agents' movements and interactions. Internally, it maintains a JSON structure containing the states of each agent.
Agent architecture
The agent itself is an event memory augmented LLM. In this case, ChatGPT (gpt3.5-turbo) is employed. At the time the article was written, GPT-4 was invite-only, making it unavailable for this project (though its use might have offered enhanced performance at a likely higher cost).
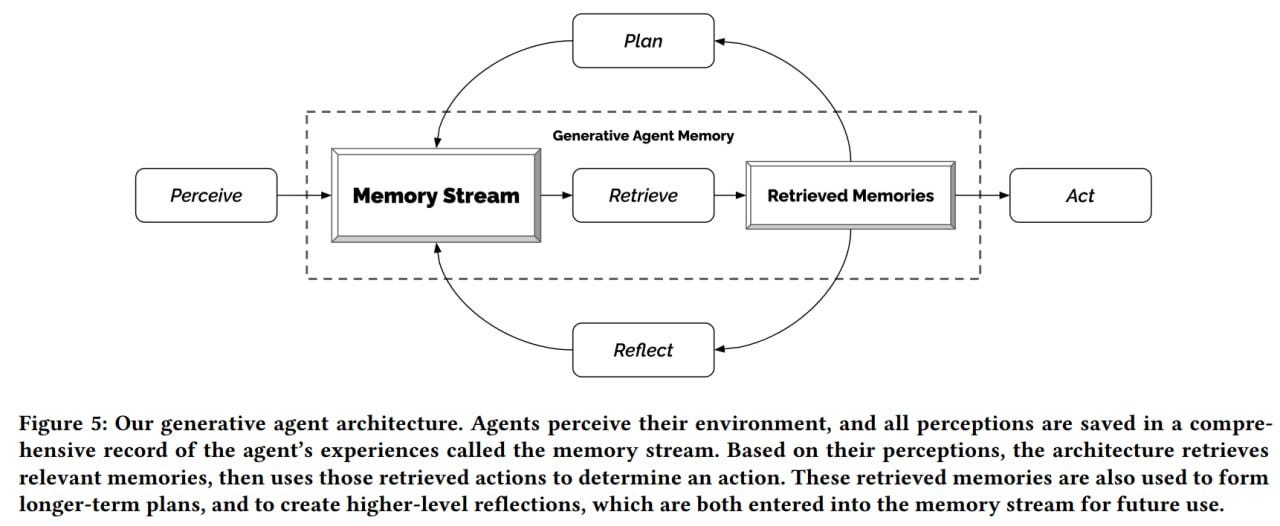
The agent's architecture is built upon three primary components:
Memory Stream: This stores the agent's life experiences.
Reflection: Synthesizes memories into higher-level conclusions.
Planning: Translates the agent's reasoning and the environment's state into high-level plans and detailed behaviors.
Memory Stream - the agent's experience database
At the heart of the agent's architecture is the Memory Stream, essentially the agent's experience database. The records and the agent's reasoning are in natural language, making use of the LLM. A challenge arises when an agent partakes in numerous events. Retrieving the most pertinent memories becomes vital, or they could surpass the prompt's capacity. Summarization might not always achieve the desired outcome as crucial details could be overlooked. Moreover, the significance of information can vary depending on the situation. Hence, extracting relevant data is crucial.

Each memory object contains textual content, its creation date, and the date of the last access. The most elementary memory type is an 'observation,' representing what the agent directly perceives. This could be the actions of the agent itself or the behaviors observed in other agents or objects.
Here is an example memory stream from of Isabella Rodrigues, who works at a cafe:
"(1) Isabella Rodriguez is setting out the pastries, (2) Maria Lopez is studying for a Chemistry test while drinking coffee, (3) Isabella Rodriguez and Maria Lopez are conversing about planning a Valentine’s day party at Hobbs Cafe, (4) The refrigerator is empty".
A special retrieval function takes an agent's current situation as input and returns a subset of events from its memory to pass to the LLM (Large Language Model). The score of each memory item depends on three factors:
Recency: This is an exponentially decaying freshness score, calculated based on the last time an item was accessed.
Importance: This score comes from the LLM, rated on a scale of 1 to 10. Here, 1 indicates something mundane and minor (like brushing teeth), while 10 represents something significant (like getting a divorce or entering college).
Relevance: It's determined using cosine similarity between the embeddings (obtained from the LLM) of the query and the memory item.
All three factors are normalized to a range of [0, 1] and are weighted and summed (with equal weights in this study). Only the best memory candidates that fit within the prompt are retained.
Reflection - A Higher-level Memory
After observations, Reflection serves as a secondary, more abstract type of memory generated by the agent. These reflections are also stored in the memory stream and are retrieved in a similar manner. Reflections are created periodically, especially when the combined importance scores of the agent's recent events exceed a certain threshold. In practical terms, this happens about two or three times a day.
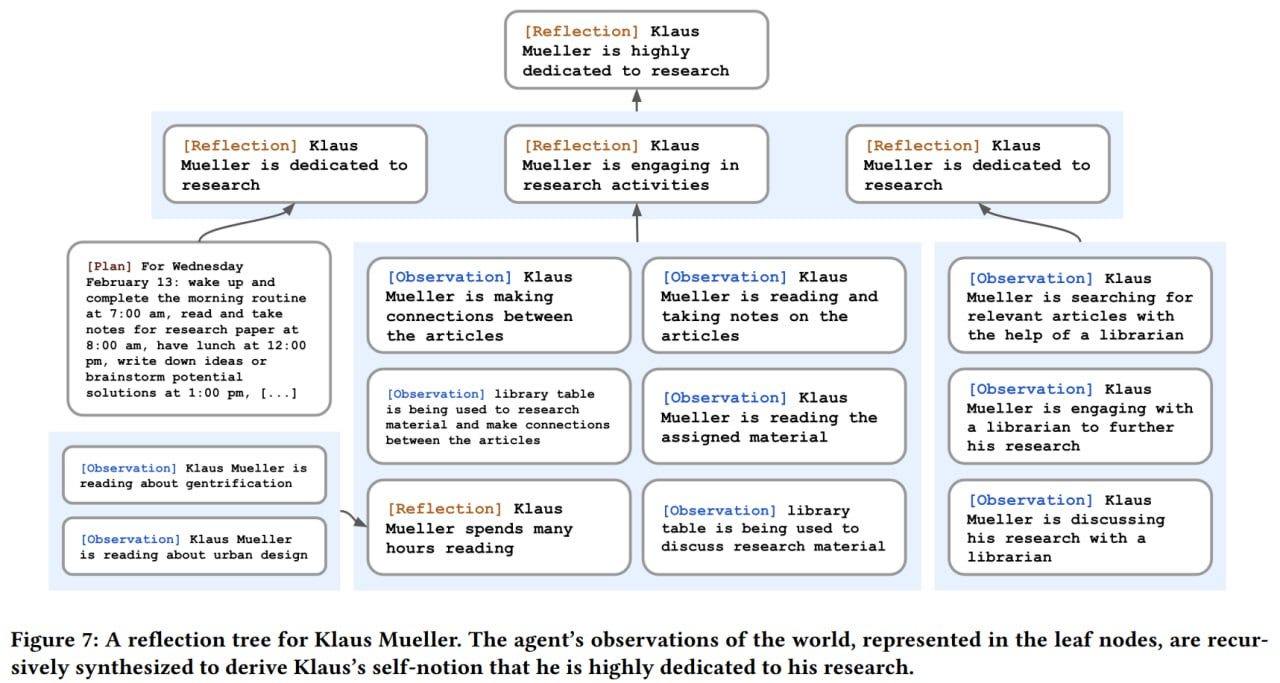
To create a reflection via the LLM, the 100 most recent memories of the agent are taken and sent to the LLM with the prompt: "Given only the information above, what are the 3 most salient high-level questions we can answer about the subjects in the statements?". Based on the retrieved questions, relevant memories are recalled, and insights are generated using the prompt: "What 5 high-level insights can you infer from the above statements? (example format: insight (because of 1, 5, 3))". For instance, the outcome might be something like: "Klaus Mueller is dedicated to his research on gentrification (because of 1, 2, 8, 15)." Reflections can also be generated based on previous reflections.
Planning and Reacting for Consistent Behavior
Now, Planning and Reacting. Planning ensures consistency and believable behavior. Without plans, if you constantly ask the LLM what the agent should do, there's a chance it might suggest having lunch at noon, then again half an hour later, and once more afterward. Plans are also stored in the memory stream and are retrieved when relevant. The approach to generating plans is top-down and recursive. Initially, a broad plan is generated for the day with 5-8 points, which is then refined and detailed. This primary plan is built based on the agent's general description and a summary of the previous day's experience. These elements are first detailed at an hourly resolution and later refined to intervals of 5-15 minutes.

The agent constantly perceives the world, saves it in the memory stream, and decides via the LLM whether to continue following the plan or react to something. When querying the LLM, relevant context about the observed entity is also considered. This is achieved using prompts like “What is [observer]’s relationship with the [observed entity]?” and “[Observed entity] is [action status of the observed entity]” to recall and summarize pertinent memories. If the LLM suggests a reaction, the plan is regenerated accordingly. If an interaction between two agents is implied, their dialogue is generated, influenced by their memories of each other.
Life in Smallville
In the town of Smallville, there are 25 agents. The identity of each agent is described by a single paragraph of text in English. Within this description are phrases separated by semicolons; these phrases are input into the agent's memory as recollections before the simulation starts.
Here's an example of one agent's description:
“John Lin is a pharmacy shopkeeper at the Willow Market and Pharmacy who loves to help people. He is always looking for ways to make the process of getting medication easier for his customers; John Lin is living with his wife, Mei Lin, who is a college professor, and son, Eddy Lin, who is a student studying music theory; John Lin loves his family very much; John Lin has known the old couple next-door, Sam Moore and Jennifer Moore, for a few years; John Lin thinks Sam Moore is a kind and nice man; John Lin knows his neighbor, Yuriko Yamamoto, well; John Lin knows of his neighbors, Tamara Taylor and Carmen Ortiz, but has not met them before; John Lin and Tom Moreno are colleagues at The Willows Market and Pharmacy; John Lin and Tom Moreno are friends and like to discuss local politics together; John Lin knows the Moreno family somewhat well — the husband Tom Moreno and the wife Jane Moreno.”
Agents can perform actions and communicate with other agents. At every time tick of the sandbox, an agent produces a text that describes its current action. For instance, "Isabella Rodriguez is writing in her journal", "Isabella Rodriguez is checking her emails", "Isabella Rodriguez is talking with her family on the phone", or "Isabella Rodriguez is getting ready for bed". This text translates into an action within the environment.
A separate language model translates this text into a set of emojis, which appear above the agent's avatar within the environment.
Agents communicate with each other in English. They're aware of the presence of other agents nearby and decide whether to walk past or engage in conversation. An agent can move around the world, enter buildings, and approach other agents. If an agent's model directs it to a specific place in Smallville, the environment calculates the route, and the agent follows it.
The simulation operator can engage in conversation with an agent, as well as issue directives through an "internal voice". Users can enter Smallville as agents, either as new agents or as existing ones. All this increasingly reminds me of the movie "The Thirteenth Floor":
When interacting with a new agent, other agents treat them just like any other, with the exception that there's no history about the new agent in Smallville.
In their interactions with the world, agents can alter the states of objects. For example, a bed might be occupied, a fridge emptied, or a stove turned on. Users can also intervene and modify the state of world objects. For instance, making a shower in the bathroom leaky, in which case an agent will start fixing it. To perform an action, the LLM is queried to determine how the object's state will change.
Agents construct their trees with subgraphs of the entire environment as they move through the world. These trees can become outdated. Each agent is initialized with a tree containing important places they should know about (home, work, stores).
To convey the state of the environment to an agent, the world's description tree is translated into natural language. To determine a suitable location for a specific action, the tree is traversed, the current portion of the tree is converted into text, and the LLM is queried to find the most suitable place.
Evaluation
To assess the performance of this entire setup, the authors did a few things.
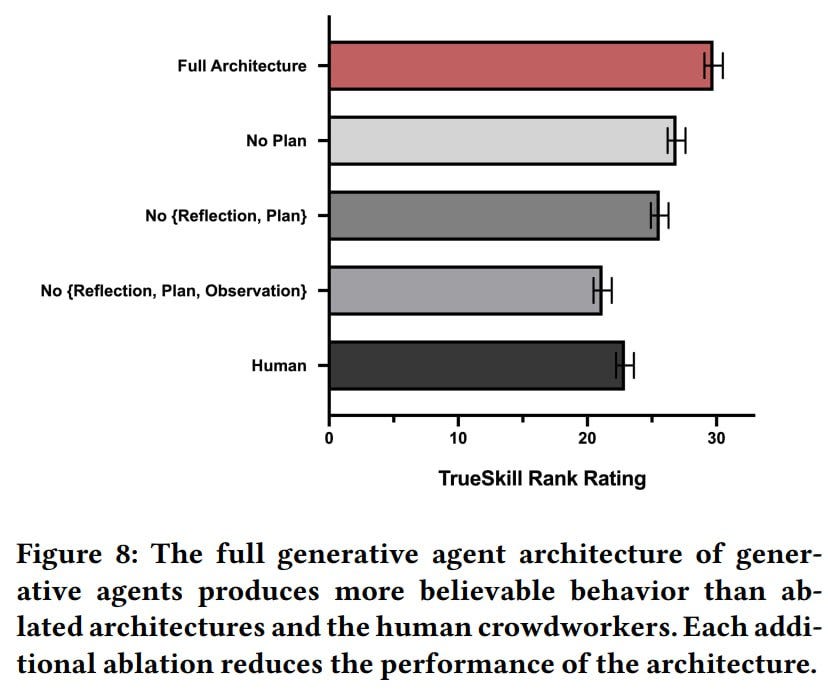
Firstly, agents can be queried to determine their abilities to recall past experiences, plan actions, and adequately respond to unexpected events. For this, agents need to recall and synthesize information. Five areas were examined: maintaining self-knowledge, retrieving memory, generating plans, reacting, and reflecting. The results were evaluated by humans based on the believability of the behavior. These were compared to versions of the architecture with disabled types of memory (without planning, without reflection, and without observations) and were also compared to some (not the best) crowd workers. The full architecture turned out to be the most believable. But even without planning and reflection, the results were decent. The study delves deeply into these findings. Interestingly, reflection is essential for proper synthesis and decision-making. How human-like!
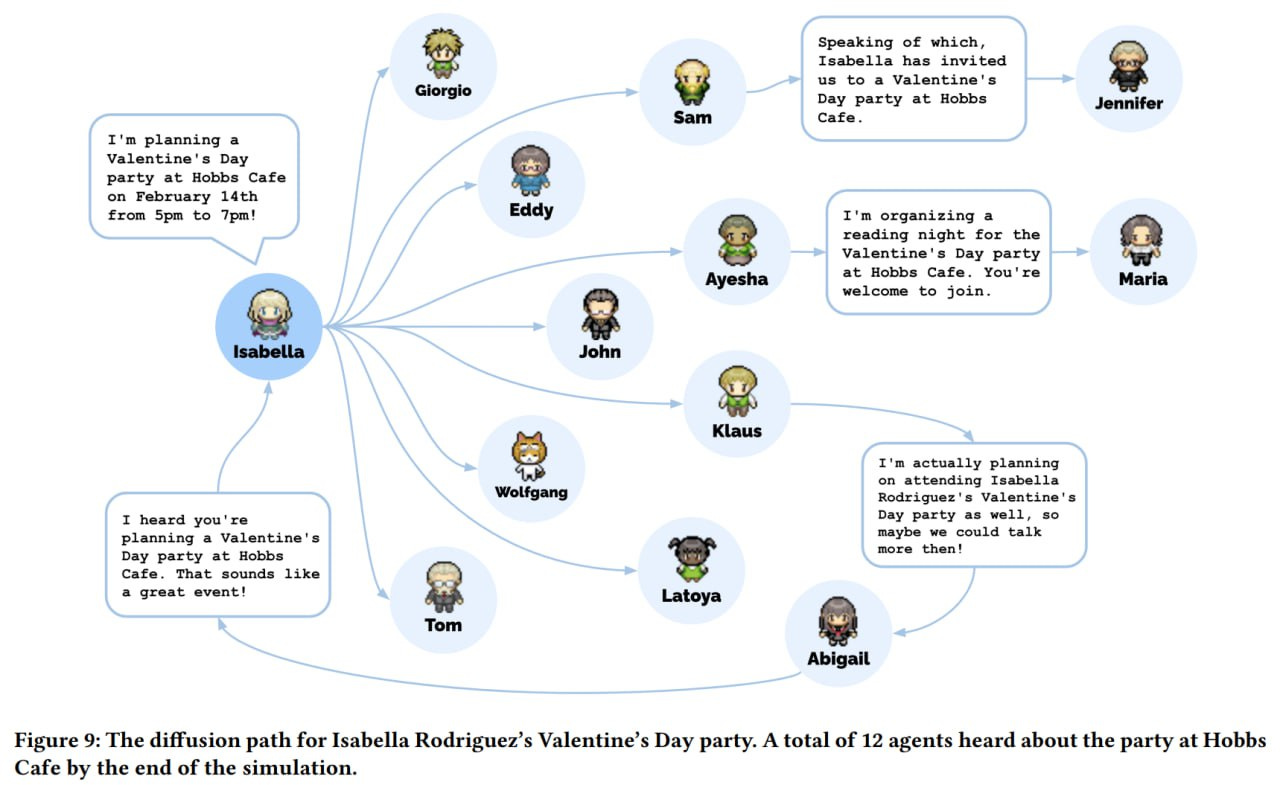
Secondly, they observed emergent behavior. The authors checked three types of such behavior: information diffusion, relationship formation, and agent coordination.
Information diffusion is when crucial information spreads among agents. The authors checked this with topics like mayoral election nominations and planning a Valentine's Day party. Initially, only the initiating agents had the knowledge, but after two game days, all agents were polled. The authors ensured that these weren't hallucinations of the LLM and found specific dialogues confirming the transfer. The percentage of informed agents significantly increased in both cases (from 4% to 32% or 48%).

In terms of inter-agent relationships, they asked if they knew each other at the beginning and end of the simulation. The density of relationships noticeably increased.
Regarding coordination, they checked how many agents eventually came to the party at the right time and place after hearing about it. 5 out of 12 invited attendees showed up. The other seven were polled: three cited conflicts that prevented them from coming, and the remaining four expressed interest but didn't plan anything.
The authors analyzed the agents' erroneous behaviors and highlighted three types.
Synthesizing a large volume of memories is a challenge, both from the perspective of bringing up the relevant ones and from the standpoint of choosing the correct place of action, especially if the agent has a vast world model.
In some cases, agents incorrectly classified the appropriateness of behaviors. For example, when an agent believed that a college dorm bathroom could accommodate more than one person or when heading to a store that was already closed. This can potentially be addressed by more explicitly adding norms to environmental states and descriptions (see language hints in the Dynalang paper).
Possibly due to instruction tuning, the agents' behavior was generally more polite and cooperative. Sometimes dialogues appeared overly formal, and agents seldom said "no."
That's the rundown.
The current simulation with 25 agents spanned two days of in-game time and required "thousands of dollars" and several (multiple) days of real time.
Some more reflections
Overall, it's a very cool and well-executed piece of work. It gives rise to a new class of interesting simulations. There are still many questions and challenges, but it seems to me that computational social studies are getting an unexpected turbo-boost. Surely, this will also lead to the emergence of a new class of NPCs in games and metaverses.
I also see it as a tool for assembling prototypes of cognitive architectures. One can experiment with different modules, algorithms, and organizational methods.
It's interesting how LLM has become a kind of magical dust that can be sprinkled on various complex-to-formalize parts of a program, and they start to work effectively. Or like a magical glue that binds different pieces together.
Let's see where this goes.
UPD. See a newer work by the same team: