
Learning to Model the World with Language
Dreaming with language

Authors: Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, Anca Dragan
Paper: https://arxiv.org/abs/2308.01399
Site: https://dynalang.github.io/
Alright, folks, gather around! We've got this sizzling new piece about World Models. Now, we've been a bit lazy and haven’t chatted about this topic before, but trust me, it's all the rage! Remember our beloved buddy Schmidhuber and his equally rad friend David Ha? (Link to their brilliance). They once had this dope idea that an agent could learn all about its surroundings and then flex its skills within a simulation. And dang, it was good! (Check their swanky project).
Since then, there's been an explosion of cool stuff! Remember Dreamer? (Link). Now, there's DreamerV3 (Link to the sequel). Fun fact: One of our current paper's rockstars, Danijar Hafner, is the genius behind Dreamer. And guess what? Our latest model is like the love child of DreamerV3 and LLM – getting input from language and, if it feels like it, spitting it out too.
Now, let's introduce you to the superstar: Dynalang! Imagine an agent who's like a DJ, mixing the beats of a multimodal world model and adding the spicy lyrics of language. Agents have used language before to predict moves (like if you told them, "Make me a sandwich"), but just predicting actions from text is like expecting your cat to fetch – kinda weak. These peeps hypothesized that predicting future 'thingies' gives a richer vibe to understand language and how it jives with the world. So now, language isn't just for direct instructions but also to predict future chats and what your eyes see, and oh, the rewards, baby!
Dynalang does this super cool dance move where it separates learning about the world dynamics and then rocking out actions in that world using the learned model.

The task for the world model (or, you know, the WM for the cool kids) is to condense what it sees and reads into a 'latent representation'. Think of it like cramming for an exam the night before. Then it uses these notes to predict future notes based on the agent's shenanigans in its surroundings. These notes get passed to the policy, which then calls the shots and aims to score big.
Thanks to this split, Dynalang can train solo on things like text or video, without needing any actions or rewards. It's like eating dessert before dinner because you can!
You can now make it chatter away like a parrot on caffeine! Basically, when our little digital agent gets a nudge from its language model, it starts babbling to the environment. Cool, right?
Alright, let's get a tad nerdy. When our agent is out there playing its digital video game of life, it chooses an action (a_t). Most of the time, it’s just picking a number (as if it's choosing what pizza topping it wants). But sometimes, it might just throw in a word or two. And when it does its thing, the environment responds, producing a reward (r_t), a boolean flag meaning an episode continuation (c_t), and an observation (o_t). The observation consists of the pair of image (x_t) and a language token (l_t). Here’s a spicy bit: using a word-by-word approach is way slicker than whole sentences. The goal? Get as many of those sweet, sweet cookies (rewards) as possible!
Enter WM. It’s this snazzy thing called Recurrent State Space Model (RSSM), which is based on GRU that's like a memory wizard for our system. GRU holds a recurrent state (h_t).
There's a bunch of fancy tech magic that happens after, involving sequences and decoders.
Every moment (x_t, l_t, h_t) gets encoded (using VAE encoder) into a latent code (z_t):
z_t ∼ enc(x_t, l_t, h_t)
The sequence model (GRU) produces new latent and recurrent states:
z’_t, h_t = seq(z_{t−1}, h_{t−1}, a_{t−1})
A decoder restores observation data from the latent and recurrent states:
x’_t, l’_t, r’_t, c’_t = dec(z_t, h_t)
For my peeps who love the details: the visuals use CNN (nope, not the news channel), and everything else uses MLP (sadly, not My Little Pony).

WM gets its knowledge from two major teachers: representation learning loss (L_repr) and future prediction loss (L_pred). And trust me, these aren’t as terrifying as they sound! They're just about how well the model is doing its homework on images, text, and rewards.
Thanks to WM and policy decoupling, Dynalang has the ability to pre-train on the large text and video corpuses without performing actions.
A super rad difference between this model and old-school LLMs? Instead of just straight-up guessing the next word, this model is like a fortune teller, predicting the vibe of the next move, predicting the next step representation first.
Lastly, our little agent learns its moves from some imaginary action-movie sequences, not from actual experiences. Imagine it daydreaming about being James Bond and learning all the tricks! It even replays its own imaginary scenarios to perfect its strategy.
Now get ready for some fun, folks! Here’s a quirky breakdown of the hypotheses authors test:
H1) Can an agent use language outside of just instructions to up its game? Like using some sneaky in-game manuals or language hints. Spoiler: Yep!
H2) Grounding language in future predictions might just be better than outright telling an agent what to do. A bit like telling your friend, “I bet you can’t jump over that puddle” versus “Jump over that puddle.”
H3) Taking instructions as future rewards predictions is just as cool as predicting actions from them. It’s like betting on a horse because of its name vs. its odds.
H4) The Dynalang formulation additionally enables the agent to generate language.
Techy Bits: The content is sliced and diced by T5’s tokenizer. Depending on what you’re up for, you can either go for one-hot or snag embeddings from T5-small (the lightweight, 60M version).
Baseline models? Say hello to model-free IMPALA and R2D2. No, not THAT R2D2, silly! These are grabbed from Seed RL, and these models have around 10M parameters. Bigger isn’t always better for them.
The Testing Grounds:
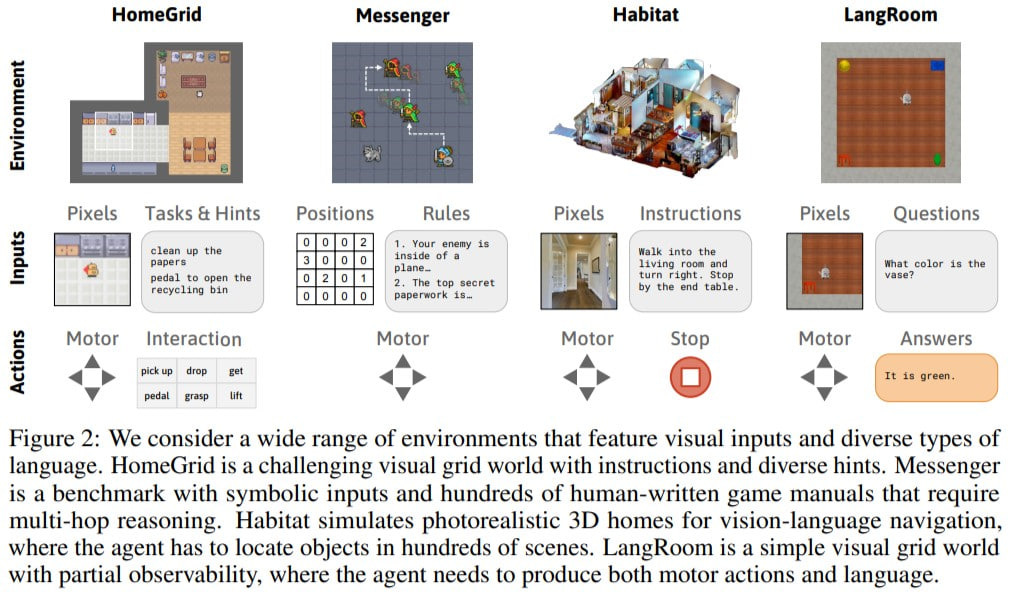
HomeGrid: This is like a DIY board game where the agent gets textual tasks and hints. The game might say, “Psst, that wall might move!” or “You might wanna go left.” There’s a bunch of different tasks involving various objects and trash bins.
Guess what? With Dynalang's tips, agents are rockin’ it, even if hints are miles away from what’s happening. H1 and H2, you’re onto something!

Messenger: This is not your grandma's game of post office! The agent’s got to pass messages, avoiding some bad guys. There are text manuals detailing the game dynamics. Oh, and difficulty levels go from S1 to S3.


Compared to other models, Dynalang is the life of the party, especially in the hard-level S3 where others just can't keep up. H2, you're golden!
Vision-Language Navigation (VLN): Here, agents are like tourists in a VR world of house panoramas.

They get directions, and compared to R2D2, they’re nailing it way more. High-five, H3!
LangRoom: This is all about an embodied agent answering text questions about stuff around them. It’s kinda like a fun “Where’s Waldo?” but with words.

It’s more of a proof-of-concept thing, but the agent does learn to pick up info and come up with the right answers. H4, you're the real MVP!






So, in short, the future's looking bright for Dynalang and language-based learning. Rock on!
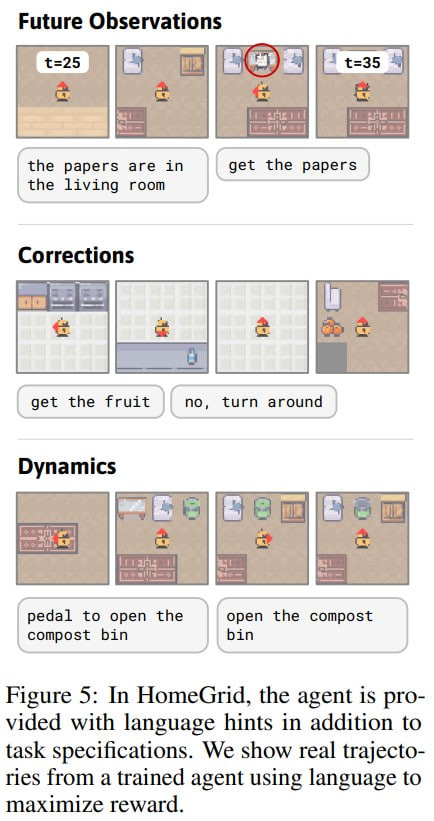
Hey, guess what? You can make some really groovy imaginary rollouts from a world model. It's kinda like peeking into your model's brain to see if it's making any sense at all.

Now, before y'all get too carried away, here's the scoop:
Trying to stack up Dynalang against those existing LLM bad boys? Nuh-uh, honey! It's like comparing a goldfish to a whale. Dynalang's got around 150-300M parameters, depending on the vibes you set. That's not even in the same ballpark as the lightest version of LLaMa 2. Plus, its architecture? Totally not a transformer. So, if you're peeking at quality metrics that compare LLMs, well... don't bother.
Comparing it with Gato or PaLM-e? Again, it's apples and oranges, dudes. PaLM-e is still struttin' its LLM stuff, albeit with some snazzy multi-modal inputs and spits out text commands. Plus, it's one of the biggest models out there. Gato? It's a bit bulkier than Dynalang but still on the petite side. But, whispers say DeepMind's probably training a mega Gato 2 and playing coy. These models are versatile, cranking out all kinds of tokens, not just for chitchats or image descriptions but actions too. And get this, they learn without RL and don't have any fancy dynamic world models inside (though they might have some secret sauce somewhere).
All in all, things are heating up! We're likely gonna see big daddy models like Dreamer+LLM real soon. Keep your eyes peeled, folks! And go out there and make your digital agents talk, predict, and daydream!