
Chain-of-Thought → Tree-of-Thought
An Evolution in Large Language Model Reasoning

It starts with Chain-of-Thought (CoT)
The technique known as Chain-of-Thought (CoT) for enhancing the response quality of Large Language Models (LLMs) appears to originate from the study titled "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" (https://arxiv.org/abs/2201.11903). This has since become a staple in the toolkit of prompt engineers, and is also a patented technology (https://patents.google.com/patent/US20230244938A1/en).
In essence, CoT involves asking the model not to provide an immediate answer but to first generate a sequence of intermediate steps, culminating in the final result. This method can be combined with few-shot learning by providing illustrative examples.
Surprisingly, using this approach enhances the quality of responses, especially in mathematical problems, commonsense, and symbolic reasoning. Another benefit of this method is its decision-making transparency and interpretability. The initial study revealed that CoT emerges as an inherent property in models roughly around the 100B size.
An additional decoding technique called Self-Consistency, introduced in "Self-Consistency Improves Chain of Thought Reasoning in Language Models" (https://arxiv.org/abs/2203.11171), swaps out greedy decoding for generating multiple CoT chains. In the end, the most consistent answer, determined by a majority vote, is selected. This CoT-SC approach, sometimes also dubbed Multiple CoTs, improves with more chains – with researchers achieving up to 40.
A general overview of CoT, and a touch of CoT-SC, can be found here: https://blog.research.google/2022/05/language-models-perform-reasoning-via.html.
Enter Tree-of-Thoughts (ToT)
However, these developments date back to early 2022. Since then, more advanced techniques have emerged. Notably, the Tree-of-Thoughts (ToT) emerged almost simultaneously from two studies: "Large Language Model Guided Tree-of-Thought" (https://arxiv.org/abs/2305.08291) and "Tree of Thoughts: Deliberate Problem Solving with Large Language Models" (https://arxiv.org/abs/2305.10601).
In this paradigm, reasoning is represented as a tree rather than a linear chain. This allows the model to backtrack if the reasoning veers off track.
The core premise of these studies is that the thought process isn't linear but more akin to navigating a tree. One might explore a branch, find it unfruitful, backtrack, and then try a different path. This implies multiple rounds of interaction between the LLM and the agent providing prompts.

These newer methods go beyond mere prompt engineering. A simple text prompt won't suffice; one needs to design specific programs to manage the process. In this regard, it aligns more with the LLM Programs paradigm.
Large Language Model Programs

Authors: Imanol Schlag, Sainbayar Sukhbaatar, Asli Celikyilmaz, Wen-tau Yih, Jason Weston, Jürgen Schmidhuber, Xian Li Paper: https://arxiv.org/abs/2305.05364 A fascinating study caught my attention, primarily because of its association with Sainbayar Sukhbaatar, but seeing Jürgen Schmidhuber as a co-author made it even more intriguing.
The 1st paper
Let's Dive into the first paper by Jieyi Long's Work from Theta Labs.
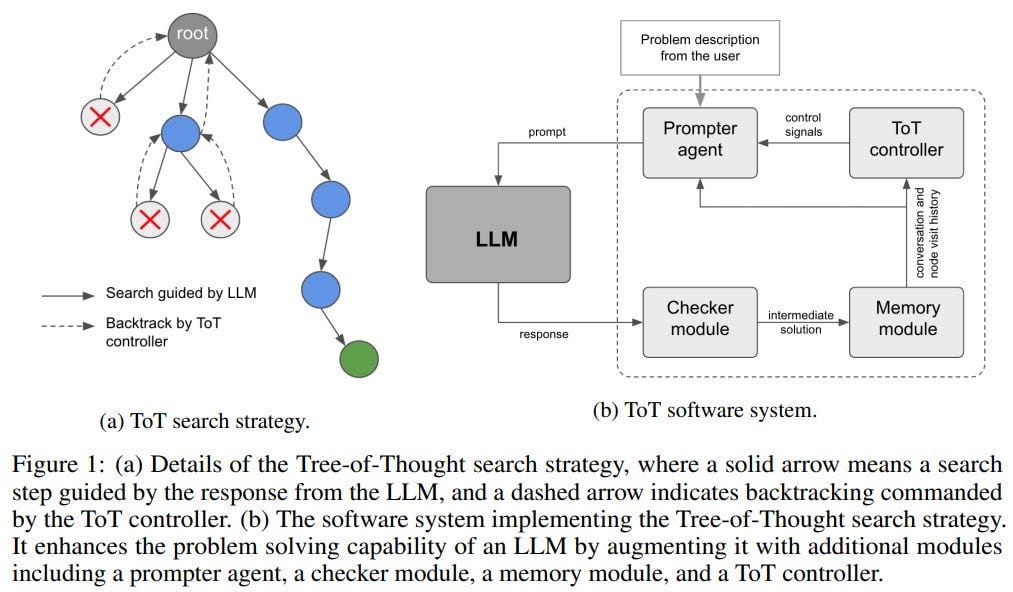
At the core of this research, we have an LLM which receives prompts and provides answers. Then there's the prompter agent that gets the original task from the user. Instead of trying to extract a final solution from the LLM, this agent seeks an intermediate one. There's a unique checker module that tests the validity of the solution from LLM. If the solution passes the test, it's parsed and stored in memory. Depending on what's in memory, the prompter agent generates the next prompt to guide LLM to the subsequent step. But if the LLM provides an invalid answer, a ToT controller will ask the prompter to give the model appropriate hints and request the solution again. The ToT controller also monitors progress and decides if there's a need to revert to a parent node or even an earlier ancestor.

In essence, the ToT strategy can be visualized as a tree-search algorithm, using LLM as a heuristic for search steps. LLM is utilized for "short-range reasoning" tasks, like obtaining the next intermediate answer. Generally, LLM handles these tasks quite well. The ability to revert to prior solutions enhances "long-range reasoning" capabilities, since it allows the system to explore a wider solution space. Being able to carry out multi-step interactions also expands the number of computational steps the system can take.
Delving a bit deeper, the checker module can either be rule-based or neural network-based. Some forms of correctness (like 3SAT, equation solving, etc.) are easier to validate with rules, while some tasks are better suited for neural networks.
The memory module retains the entire dialogue history between LLM and the prompter agent, which the latter can use to generate hints for the LLM.
Overall, the ToT Controller oversees the ToT search. It can be defined by simple rules like:
If the checker deems the current solution invalid, revert to the parent node.
If the current intermediate solution is valid but after exploring X (a hyperparameter) children no solution is found, then revert to the parent node.
Alternatively, this controller can also be designed as a policy network
The prompter agent gives hints (or prompts) to the LLM for generating the next step. It can be implemented as a general prompt or as a policy network.
In the study, they utilized a version of the REINFORCE algorithm to train both policy networks. In the future, they plan to use a more advanced MARL (multi-agent reinforcement learning) algorithm. Overall, there's great potential for policy training in the style of AlphaGo through self-play.

The trained system can be employed for ToT problem-solving.
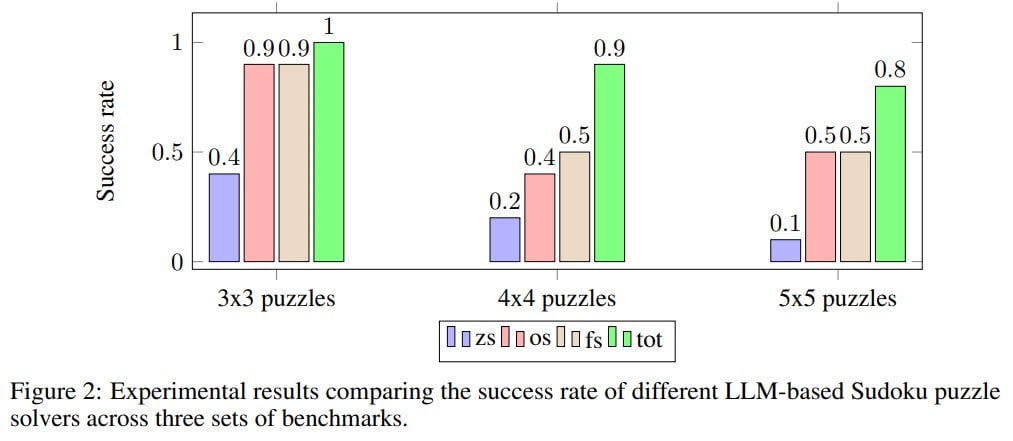
They tested it on small Sudoku puzzles (which isn't the most LLM-friendly task, and is, in fact, NP-hard) ranging from 3x3 to 5x5.

The results surpassed zero-shot, one-shot, and few-shot with CoT.
You can find the implementation here: Tree of Thought Puzzle Solver on GitHub.
The 2nd paper
The second work is by a team from Princeton and Google DeepMind.
In this work, the solution to the problem is also represented by a tree, where the nodes contain individual "thoughts" – intermediate steps in solving the problem. LLM is also used as a heuristic for searching through this tree.
Every specific implementation of ToT (Tree of Thought) should answer 4 questions:
How to decompose the process into separate thought-steps. A balance has to be struck here: on one hand, the thought should be small enough for the LLM to generate promising and varied samples. On the other, it should be significant enough for the LLM to gauge its utility in problem-solving (for example, a token level might be too low).
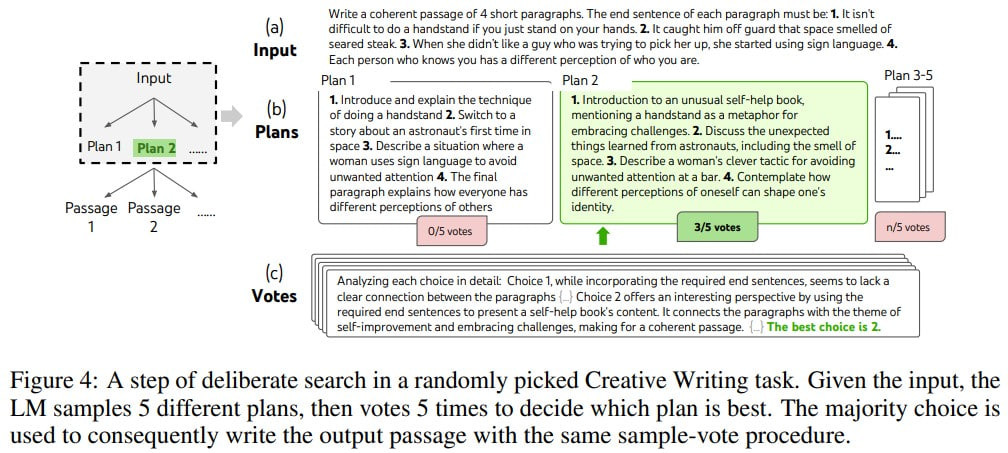
How to generate potential thoughts from each state. The task is to generate 'k' candidates for the next step. The authors consider two strategies: 1) to sample i.i.d. thoughts from a CoT prompt (this works better when the thought-space is large, e.g., when a thought is a paragraph); or 2) to suggest thoughts sequentially using a “propose prompt”.
How to heuristically evaluate states. Previously, search heuristics were either hardcoded algorithms or something learned. However, here, LLM is used for reasoning, introducing a new layer of fairly universal intelligence operating through language. Two strategies are considered here as well: 1) evaluating each state independently using a specific prompt, 2) grouping states into one prompt and voting, which is simpler when it's challenging to evaluate a state. Both types of evaluations can be done multiple times to aggregate the results.
Which search algorithm to use. This is straightforward: they tried depth-first and breadth-first search (DFS and BFS).

The system was tested on three tasks: Game of 24, Creative Writing, and 5x5 Crosswords. All tests were conducted on the GPT-4 platform (it's unusual to see a DeepMind work based on GPT-4 🙂).

The performance is significantly better than standard IO prompt, CoT prompt, and CoT-SC.
Game of 24:


Mini Crosswords:

Creative Writing:

The implementation can be found here: https://github.com/princeton-nlp/tree-of-thought-llm
Despite some differences in descriptions, the approaches are largely about the same thing. It's surprising how they are releasing all this synchronously.
I wonder if this has been added to AutoGPT? Or will they directly implement Graph of Thoughts (https://arxiv.org/abs/2308.09687, more on this another time)?
Overall, I get the feeling that we are getting close to creating something that might have an impact similar to the Morris Worm back in its day.
Very well done! We've featured your article in our today's newsletter.
Thanks for writing this, it realy clarifies a lot, though sometimes it feels like the field moves so fast we'll need an actual knowledge graph just to track all the 'thoughts' techniques.