
DeepSeek-R1: Open model with Reasoning

Title: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Paper: https://arxiv.org/abs/2501.12948
Repository: https://github.com/deepseek-ai/DeepSeek-R1
While Jay Alammar has created an excellent illustrated guide:

, I still want to dive in and discuss what makes DeepSeek-R1 special.
It’s worth keeping in mind, there are many different GPT-like models from DeepSeek:
DeepSeek-V3-Base: a pre-trained model before post-training (i.e., before SFT and RL). Technical details were discussed in the post about DeepSeek-V3 architecture.
DeepSeek-V3: a final V3 model after Post-training, you can consider it a chat or instruction-tuned model. This part was covered in the post about DeepSeek-V3 training procedure.
DeepSeek-R1: a reasoning model trained on top of DeepSeek-V3-Base model. It actually includes DeepSeek-R1-Zero, DeepSeek-R1 and six smaller distilled dense models. This post covers all of these models.
R1 is a reasoning model, similar to OpenAI o1/o3, Google Gemini 2.0 Flash Thinking, or Alibaba Cloud Qwen QwQ. The core idea behind reasoning models is that instead of producing an immediate answer, the model first engages in Chain-of-Thought (CoT) reasoning, generating many tokens in its reasoning chains before arriving at a final answer. This represents a fascinating shift in model scaling: while previously, all scaling happened during training time (bigger models, longer training), now we can let models "think longer" during inference time. This opens up a new dimension for model scaling — we've entered the era of Test-time compute.
DeepSeek-R1 appears to be the best open-source reasoning model available today, competing well with top commercial offerings. The race is on, and we'll likely see many new models, including smaller ones with reasoning capabilities, in the coming months. It's already happening, with models like s1 (https://arxiv.org/abs/2501.19393) emerging.

Notably, this work also signals a renaissance of Reinforcement Learning in NLP.
What's groundbreaking about R1?
The main achievement, reminiscent of AlphaZero (hence the name DeepSeek-R1-Zero), is demonstrating that teaching reasoning doesn't require vast numbers of SFT examples. These capabilities can be effectively learned through large-scale RL, potentially eliminating the need for "human demonstrations" via SFT. However, jumpstarting the process with a small amount of high-quality SFT examples still yields better results.
Another huge achievement is that now we have a really good open model with reasoning. And we may expect much more when the community use the distilled models and fine-tuned them further.
DeepSeek-R1-Zero
The foundation for this work is DeepSeek-V3-Base.
The team employed Group Relative Policy Optimization (GRPO), previously used in DeepSeek-V3 and DeepSeekMath. This approach cleverly eliminates the need for a critic model, which typically matches the policy model in size.

The reward system uses rule-based modeling, again saving the overhead of another large model. This approach mirrors the Rule-based RM from DeepSeek-V3's post-training.
They implemented two types of rewards:
Accuracy rewards: Evaluating answer correctness, which is straightforward for mathematical problems or coding tasks.
Format rewards: Ensuring the "thinking process" follows the correct format within '<think>' and '</think>' tags.
They deliberately avoided Neural-based RM due to its susceptibility to reward hacking, resource intensity, and added training complexity.
The approach uses a straightforward CoT prompt that requires the model to think before answering:

R1-Zero shows impressive progress during training, reaching performance levels on AIME 2024 that approach OpenAI o1-0912 and surpass o1-mini within 8,000 steps. Majority voting significantly improves quality (the paper reports results with 64 answers).


The Zero approach, using pure RL without SFT, allows us to observe the model's evolution during training. A particularly interesting graph shows steady growth in response length — the model naturally learns that thinking longer is beneficial. This leads to spontaneous emergence of reflection capabilities (where the model re-evaluates previous steps) and exploration of alternative approaches, none of which were explicitly programmed.

The now-famous "Aha Moment" became particularly popular, showing the model learning to reconsider its answer in a remarkably human-like way.

However, DeepSeek-R1-Zero isn't perfect: its outputs can be hard to read and often mix languages. This led to the decision to improve the model's cold start by fine-tuning it on high-quality data before RL.
DeepSeek-R1
The enhanced training pipeline consists of four carefully orchestrated stages.
The first stage, Cold Start, involved collecting thousands of examples with long Chain-of-Thought chains. The team used few-shot prompting with detailed CoT examples, explicitly prompting for detailed answers and verification. They incorporated results from DeepSeek-R1-Zero with human post-processing, and all examples included summaries at the end of reasoning chains.
In the second stage, Reasoning-oriented Reinforcement Learning, they fine-tuned DeepSeek-V3-Base on the cold start data and applied the same RL process as -Zero. To address language mixing issues, they added a language consistency reward, which is a proportion of the target language inside CoT. The final reward combined task accuracy and language consistency, and they trained the model until convergence.
The third stage, Rejection Sampling and Supervised Fine-Tuning, utilized the checkpoint from the previous stage to gather data for subsequent SFT. While the initial cold-start data primarily targeted reasoning, this stage's data encompassed examples from various domains to enhance the model's capabilities in writing, role-playing, and other general-purpose tasks. The data was split into two categories: Reasoning and Non-Reasoning data.
For the Reasoning portion (600,000 examples), they generated new chains from the previous checkpoint and filtered them, partly using DeepSeek-V3 as a judge. Multiple samples were generated for each prompt, and problematic outputs (mixed languages, lengthy paragraphs, code blocks) were filtered out.
The Non-Reasoning portion (200,000 examples) incorporated examples for writing, factual QA, self-cognition, and translation. They leveraged the DeepSeek-V3 pipeline and reused parts of its SFT dataset, also using DeepSeek-V3 for generation.
They then fine-tuned DeepSeek-V3-Base (not the previous checkpoint) for two epochs on the complete dataset of 800,000 examples.
The fourth stage introduced Reinforcement Learning for all Scenarios, implementing a second RL phase to enhance both helpfulness and harmlessness (reminiscent of Constitutional AI approaches) while simultaneously improving reasoning capabilities. Rule-based rewards were employed for reasoning data, while reward models from the DeepSeek-V3 pipeline were used for general data. For helpfulness, they focused solely on the final summary, while harmlessness evaluation considered the model's entire output. While specific details are somewhat limited in this section, it appears they implemented Constitutional AI (or RLAIF) for both signals, rather than just harmlessness as in the original CAI work.
Distillation
The team recognized that while large MoE models are powerful, there's also a significant need for smaller dense models. To address this, they distilled DeepSeek-R1 into various open-source architectures including Qwen and Llama. The distillation process involved fine-tuning these models on DeepSeek's outputs, utilizing the previously mentioned 800,000 samples.
The resulting family of distilled models includes:
Qwen2.5-Math-1.5B
Qwen2.5-Math-7B
Qwen2.5-14B
Qwen2.5-32B
Llama-3.1-8B
Llama-3.3-70B-Instruct
These distilled versions underwent only SFT without additional RL training, leaving an opportunity for the community to potentially enhance their performance further through RL fine-tuning.
Evaluation Results
The team conducted extensive evaluations against DeepSeek-V3, Claude-Sonnet-3.5-1022, GPT-4o-0513, OpenAI-o1-mini, and OpenAI-o1-1217.
R1's reasoning performance matches OpenAI-o1-1217, significantly outperforming Sonnet, 4o, and mini.

The distilled models also showed impressive results, they used the open QwQ-32B-Preview as a baseline:
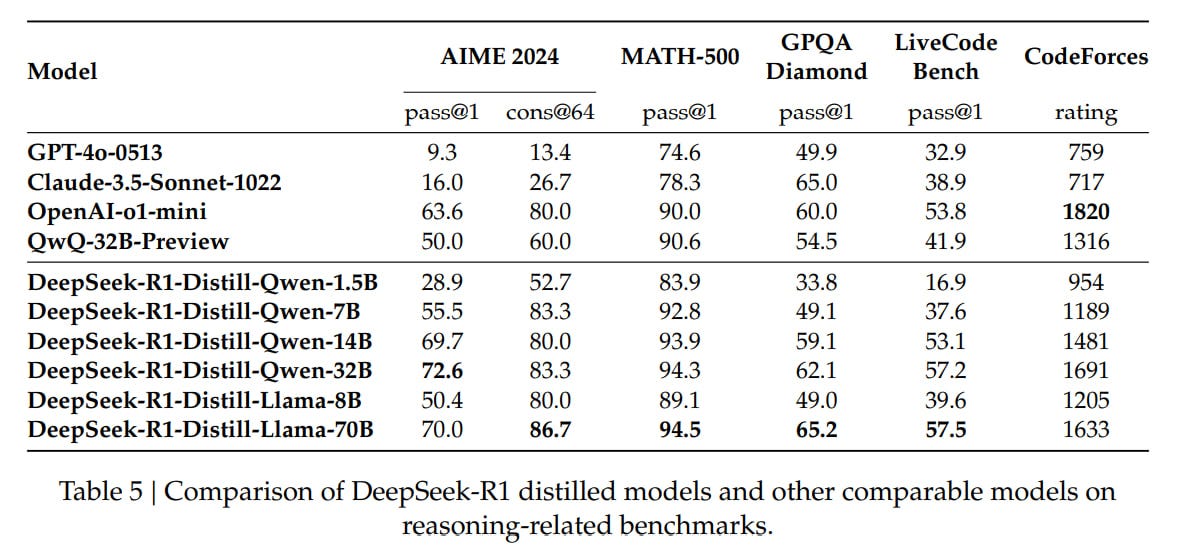
DeepSeek-R1-Distill-Qwen-7B outperforms non-reasoning GPT-4o-0513
DeepSeek-R1-14B beats QwQ-32B-Preview
DeepSeek-R1-32B and DeepSeek-R1-70B surpass o1-mini
It’s really cool we have open models of such quality now, the models you can run at home. We can expect even more after community improves these models with RL and other fine-tunes.
A separate experiment with Qwen-32B-Base compared pure RL training (DeepSeek-R1-Zero-Qwen-32B) to distillation. The results suggest that distilling from a larger model is more effective than training smaller models directly through RL.
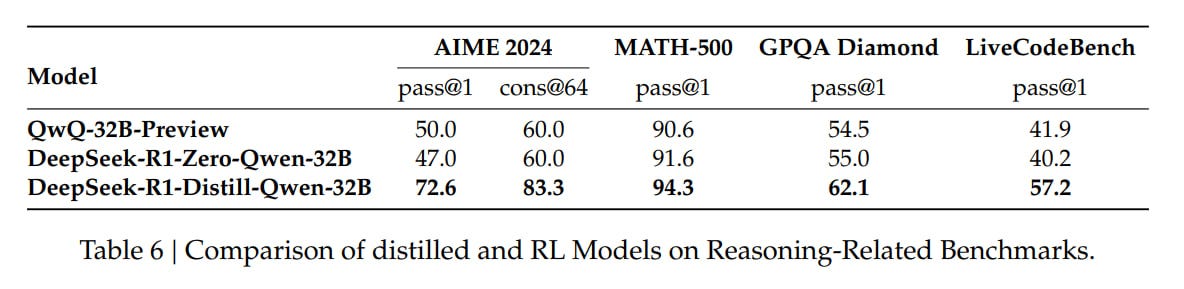
In other words, if you want to train a good small model, it's better to do it through distillation from a good large model rather than struggling to train it directly through RL. And even then, success isn't guaranteed. It's interesting that we're still not very good at finding effective small models directly — the path through larger models works better.
Another conclusion is that scaling continues to be crucial — larger models will perform better, and R1 itself could potentially be even more effective if it were a distillate from an even larger model.
What Didn't Work?
Process Reward Model (PRM, https://arxiv.org/abs/2211.14275), where rewards are given not just for the final result but also for individual CoT steps, proved challenging. In practice, it's often difficult to isolate well-defined steps within the overall reasoning process. Even when successful, evaluating the accuracy of individual steps is very challenging. Plus, this approach tends to lead to reward hacking. All of this complicates the process and requires significant overhead. The benefits gained turned out to be limited.
Monte Carlo Tree Search (MCTS), like the one used in AlphaGo, requires breaking down the answer into smaller steps to explore their solution space. The model was instructed to use separate tags for different stages of reasoning. The team first used prompting to find answers through MCTS with a pre-trained value model, then trained actor and value models on the discovered question-answer pairs, aiming to iteratively improve the process.
However, scaling this approach proved difficult. The solution space isn't as well-defined as in games. Token generation grows exponentially more complex, forcing them to limit maximum depth, which led to local optima. Additionally, training a good value model isn't straightforward, and its quality directly impacts generation. In the end, they couldn't achieve iterative improvements — this remains a challenge.
Future Plans
The authors are planning many improvements, and I'm really looking forward to their R2.
Their plans include:
Enhance function calling, multi-turn capabilities, complex role-playing, and JSON output.
Address language mixing — since the model is optimized for English and Chinese, it tends to switch to these languages when processing queries in other languages. While this might not be inherently problematic, it can be confusing for users.
The model is sensitive to prompting, with few-shot consistently degrading its performance, so they recommend using zero-shot. This aligns with recommendations for o1 (https://www.deeplearning.ai/short-courses/reasoning-with-o1/).
They also want to further optimize the model for Software Engineering. This is extremely exciting — at this rate, we'll soon have a local open-source copilot.
In conclusion, thanks to DeepSeek — few have advanced the entire field as significantly as they have.