
DeepSeek-V3: Training

Today, let's discuss the training procedure of DeepSeek-V3. We covered the architecture and technical solutions in the previous post.
To be clear upfront — this isn't DeepSeek-R1, which handles reasoning like o1/o3; this is the base chat model that R1 was trained on. I'm not sure if I'll do an analysis of R1, as the existing V3 analysis and Jay Alammar's post seem sufficient. But we'll see.
Among the technically important points, I want to emphasize again the significance of FP8 training from the previous post. It's a big deal that it finally works in production for a large, high-quality model. Effectively, it doubles the available computing power or enables training models twice the size.
Training procedure
The training is divided into pre-training and post-training phases.
Pre-training
Compared to the previous DeepSeek-V2 (https://arxiv.org/abs/2405.04434), they increased the proportion of mathematics and programming examples and expanded the language set beyond English and Chinese. However, English and Chinese still make up the majority of the dataset, and I couldn't find descriptions of the composition and distribution of other languages.
The final dataset contains 14.8T tokens (up from 8.1T tokens in the previous version). They use a BPE tokenizer with a 128k vocabulary. Compared to the previous version, the tokenizer was modified and trained on a more multilingual corpus, with added tokens combining punctuation with line breaks.
During pre-training, in addition to standard Next-Token-Prediction, they use the Fill-in-Middle (FIM) strategy with a frequency of 0.1, as implemented in DeepSeekCoder-V2 (https://arxiv.org/abs/2406.11931) but originally invented by OpenAI (https://arxiv.org/abs/2207.14255).
The model must reconstruct the middle of the text. Specifically, they use the Prefix-Suffix-Middle (PSM) approach to structure data (at document level) as follows:
<|fim_begin|>𝑓_pre<|fim_hole|>𝑓_suf<|fim_end|>𝑓_middle<|eos_token|>
During pre-training, the maximum sequence length is 4k tokens. After pre-training, they apply YaRN (https://arxiv.org/abs/2309.00071) to extend the context and perform two additional training phases of 1000 steps each, expanding the context from 4k to 32k, and then to 128k.

The result outperforms the previous DeepSeek-V2 and two dense models, Qwen2.5 72B Base and LLaMA-3.1 405B Base, across multiple benchmarks including English, Chinese, code, mathematics, and one multilingual benchmark, making it the strongest open model.

The comparison with Qwen2.5 72B Base is interesting — it was one of the strong models with almost twice as many active parameters as DeepSeek. LLaMA-3.1 405B Base has 11 times more parameters but performs worse on these benchmarks.
The authors state that DeepSeek-V3 requires 180K H800 GPU-hours per trillion tokens during training.
The result of this stage is the base model called DeepSeek-V3-Base. The following post-training stage produces the instruction-finetuned chat model called DeepSeek-V3.
Post-training
This consists of two parts: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL).
SFT
SFT was performed on additional Reasoning and Non-Reasoning data. This was done for various domains, and the final instruction-tuning dataset comprises 1.5M examples.
Reasoning data focused on mathematics, programming, and logical problems. The data was generated by their internal DeepSeek-R1 model (which was itself trained using DeepSeek-V3 as a base — see the recursion). However, R1's data had issues with verbosity, overthinking, and poor formatting.
For domain-specific data generation, they created an expert model, also trained through SFT + RL. Two types of SFT samples were generated: <problem, original response> and <system prompt, problem, R1 response>. The prompt included instructions for reflection and verification. In the RL phase, model responses were generated with high temperature, and the model gradually learned R1's patterns. After training, examples for the original model's SFT were generated using rejection sampling.
Non-Reasoning data included creative writing, role-play, and simple question answering, generated by DeepSeek-V2.5 with human verification.
RL
Reinforcement Learning (essentially RLHF) included two types: rule-based Reward Model (RM) and model-based RM.
They used rule-based RM where validation by rules was possible. For example, this works for certain mathematical problems with deterministic results and specified answer formats, and LeetCode tasks can get compiler feedback. They preferred this approach where possible as it's protected from manipulation.
For questions with free-form ground truth answers, they used a model to evaluate how well the answer matched the ground truth. In more open-ended scenarios (like creative writing) without explicit ground truth, the reward model provided feedback based on the original request and response. RMs were trained on DeepSeek-V3's SFT checkpoints. For greater reliability, preference data not only provided final rewards but included chain-of-thought reasoning leading to the reward. This apparently helps prevent reward hacking.
As in DeepSeek-V2, the authors used Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO) developed at DeepSeek as part of DeepSeekMath (https://arxiv.org/abs/2402.03300). GRPO eliminates the need for a separate value model, which typically matches the policy model's size — another area where they saved on computation and memory. Instead of a value function, they use the average reward across samples generated from the same input request.

The KL loss (needed to prevent the model from generating drastically different and unreadable text) is also simplified, comparing directly between the reference model and policy rather than between reward and policy.
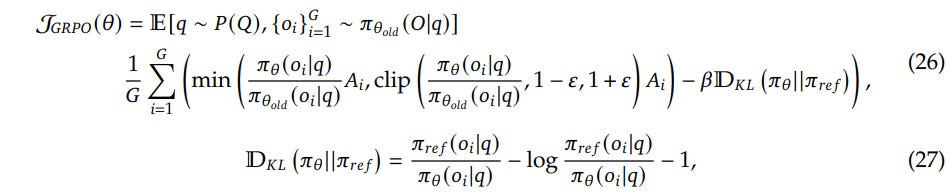
The advantage in GRPO is essentially calculated as a z-score.

I'm not an expert in these methods, but I wonder if DPO could have been used instead?
Different prompts were used for different domains.
The resulting chat model performs admirably on benchmarks, comparable to Claude-Sonnet-3.5-1022 and GPT-4o-0513. We remember that Sonnet's training cost several times more, tens of millions of dollars, though there's uncertainty about what exactly Dario reported and whether it includes experiments and related costs.

The paper includes an interesting analysis of distillation from the reasoning model (R1). This improves quality but also increases average response length, requiring careful balance in settings. They tested this on mathematics and programming but plan to expand further.

They also mention using Constitutional AI (https://arxiv.org/abs/2212.08073) — an approach I really like (primarily for its scalability) — for tasks where validation and algorithmic feedback are difficult. Essentially, the model evaluated itself, which they called Self-Rewarding. This approach improved quality, especially in subjective evaluations. I understand they plan to add more constitutional inputs.
I won't dive deep into the benchmarks, but the paper includes more detailed analyses. In any case, it's an impressive model.

What's particularly noteworthy about DeepSeek? DeepSeek isn't just a top-tier model competing with Western ones. It's a complete ecosystem of scientific work, incorporating nearly a dozen different innovations from their previous papers.
It will be interesting to see if they publish their training framework — this seems to be one of the main missing pieces currently.
To supplement your continuing coverage of DeepSeek, the following report provides insights into s1 and DeepSeek-R1 that you may find valuable, although it's focused on R1 rather than V3:
From Brute Force to Brain Power: How Stanford's s1 Surpasses DeepSeek-R1
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5130864