
Chain Of Continuous Thought (Coconut)
Training Large Language Models to Reason in a Continuous Latent Space

Training Large Language Models to Reason in a Continuous Latent Space
By Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, Yuandong Tian
Paper | Code | Song
Let's analyze this paper about Coconut and reasoning in latent space. It's particularly relevant and even Quanta Magazine has already covered it, but we haven't yet.
📃 TL;DR
The idea is simple: language space might not be the best choice for reasoning through Chain-of-Thought (CoT, read this post to learn more about CoT and ToT), and reasoning can be done without generating tokens. This insight gives birth to Coconut (Chain Of CONtinUous Thought). Instead of decoding the last hidden state into a token, it can be directly fed as input to the decoder in the autoregressive generation process as an embedding for the next step.
💡 Concept
This approach is interesting for several reasons.
First, running all reasoning through tokens creates a bottleneck. Different tokens, equivalent or not, can be generated from a single embedding, and all the richness of the original "thought" might be lost. What if we could preserve it?
An additional drawback is that each token consumes the same computational budget, although tokens aren't equally important. BLT (Byte Latent Transformer) partially solved this problem, and it's worth noting that some of the same authors worked on both BLT and Coconut.
In general, why not try reasoning without language constraints? Moreover, this aligns with certain neuroimaging data showing that language areas of the brain aren't engaged during reasoning processes. In particular, one recent study suggests that language is optimized for communication, not for thinking.
🛠 Implementation
The implementation, as already mentioned in the TL;DR, is extremely simple. During reasoning, we don't use the model's output head and embedding layer. Instead, we use the output embedding from the previous step as the input embedding for the next step.

The LLM switches between two modes: language mode and latent mode. Language mode is the standard mode for LLMs with token generation. Latent mode is a new mode that reuses embeddings. The beginning and end of latent mode are marked by <bot> (beginning of thought) and <eot> (end of thought) tokens. Accordingly, the new mode is enabled for all tokens with indices between these two tokens. The entire process is fully differentiable and allows the model to be trained using standard backpropagation.
The question is where to get data for such training. For this, language data for regular CoT is used, and a multi-stage curriculum is implemented. In the initial stage, the model is trained for regular language CoT. In subsequent stages, for step number k, the first k steps of language reasoning are removed, and within the <bot>/<eot> tags, k positions appear, each recording embeddings from the previous step. The optimizer's state is reset between individual stages.

During training, the standard negative log-likelihood loss is optimized, but the loss for the question and latent thoughts is masked and not counted. This objective doesn't incentivize the model to compress the removed textual thoughts, so there's potential for learning more efficient reasoning representations.
For an example with N reasoning steps, N+1 forward passes are needed. KV-cache can help avoid recalculating the same things, but the sequential nature of computing these stages still doesn't allow for efficient parallelization of the entire process. Optimization is a separate interesting research direction, and I'm confident it will be pursued.
During inference, the main challenge is deciding when to enter and exit latent mode. With the <bot> token, it's simple – we place it right after the question. For <eot>, two strategies are considered: 1) train a binary classifier that decides based on the embedding when to switch, and 2) pad the latent thoughts to a fixed length. Both approaches work, so by default, they use the simpler second one.
🧪 Evaluation
The approach is tested on three datasets with mathematical (GSM8k) and logical reasoning (ProntoQA, and the new ProsQA).

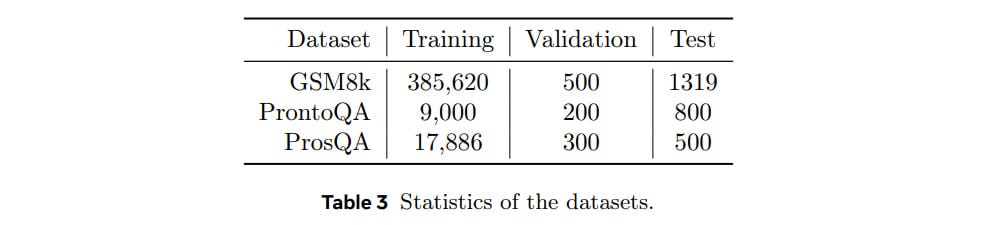
They test it using a pre-trained GPT-2. For mathematics, they use two latent thoughts (c=2) per reasoning step, three stages (k=3), and train for six epochs in the first stage and three in the others. For logic, one latent thought per step, six stages, training five epochs per stage.
The following baselines are used for comparison:
Regular CoT with model fine-tuning on examples
No-CoT, training the model to give answers directly
iCoT (implicit CoT) from https://arxiv.org/abs/2405.14838, which gradually internalized intermediate reasoning steps through sequential fine-tuning; there, steps were dropped one by one, while in Coconut, they're replaced by latent steps, theoretically giving the model more "thinking" space
Pause token, where special
<pause>tokens (as many as continuous thoughts in Coconut) are inserted between the question and answer – there's no chain of reasoning here, but additional tokens can give the model additional computational capabilities
Coconut itself is also tested in three modes:
w/o curriculum – without multi-stage training, immediately using data from the last stage where there are no language thoughts, only latent ones
w/o thought – with multi-stage training and gradual removal of language reasoning steps, but without using continuous latent thoughts – essentially similar to iCoT, but with Coconut's training procedure
Pause as thought – replacing continuous thoughts with
<pause>tokens while preserving the multi-stage procedure
🏁 Results

Coconut consistently outperforms LLMs without CoT and surpasses CoT on logical tasks. On GSM8k, regular CoT performs better, but Coconut's quality improves as the number of thoughts per step increases (saturation isn't visible up to two thoughts per step, but in the appendix, they tried three and it performed worse, likely due to training issues).
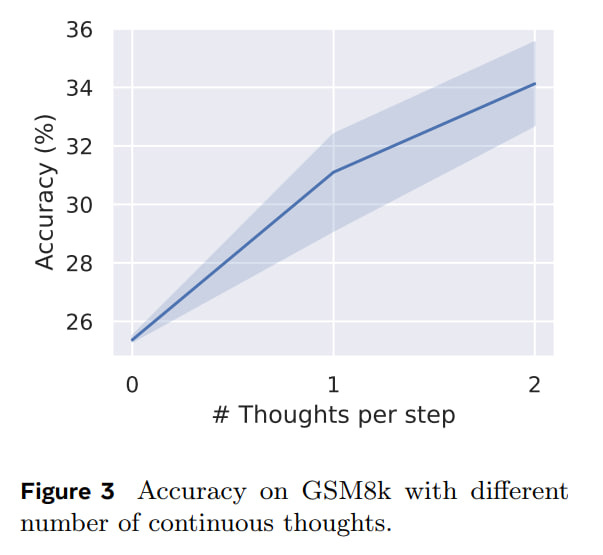
Coconut uses significantly fewer tokens in the process.
Coconut with "pause as thought" also works quite well, but standard Coconut is better.
On the authors' ProsQA dataset, where predicting the next step isn't very helpful and planning and searching through a more complex graph is necessary, regular CoT isn't better than No-CoT, but Coconut or iCoT significantly improve the situation.
Without the multi-stage curriculum procedure, the model poorly learns reasoning in latent space. In an ideal world, it would learn the most efficient continuous thoughts through backpropagation, but something is missing.
Although Coconut is designed to bypass the transition to token space, this can still be done if desired. In one example, the authors decoded the first continuous thought and saw tokens that were expected in the intermediate reasoning. This is interesting for interpretability.

🔍 Analysis
The model has an interesting ability to switch between language reasoning and reasoning in latent space. The authors further explored latent reasoning.
They tested the model on the ProsQA dataset with different numbers of latent thoughts, from zero to six. The difference here is only in inference time; the model is the same. They also enhanced the multi-stage training procedure so the model doesn't forget earlier stages, mixing in data from other stages with a 0.3 probability.
They created a more granular classification of model answer quality, now including not just the correctness of the final answer but more detailed types:
Correct Path – correct shortest path in the graph
Longer Path – correct but not shortest
Hallucination – path contains non-existent edges or is disconnected
Wrong Target – path is valid but leads to the wrong node
Correct Label and (6) Incorrect Label – for methods where only the final answer can be obtained

As expected, with an increase in the number of continuous thoughts, correct results increase. Hallucinations also decrease. A separate interesting result is that Coconut with k=0, i.e., when it's forced to generate a regular language CoT chain without latent thoughts (but already with a pair of <bot>/<eot> tokens), quality is higher than with CoT, and hallucinations are reduced. Apparently, the training procedure with mixing different stages helps (and maybe the additional token pair as well).

Latent reasoning can be interpreted as tree search, based on the intuition that continuous thoughts can contain more than one reasoning step. Thus, Coconut's first thought can select all children of a graph node, and the next thought can select the children's children. This resembles breadth-first search (BFS), but not uniform—with probabilities or priorities. The paper calculated these probabilities for examples, resulting in an implicit value function for exploring the graph. It feels like Monte Carlo Tree Search (MCTS) is somewhere nearby. And overall, it looks like they trained not a continuous CoT, but a continuous Tree of Thoughts (ToT).

Based on the probabilities obtained, one can assess the degree of thought parallelism by looking at the cumulative values of top-1/2/3 candidates. The first thoughts have higher parallelism (difference between lines for top-1/top-2/top-3) than the second ones.

Latent reasoning allows the model to postpone choosing specific words and "think through" options deeper in the search tree, evaluating nodes near the leaves where erroneous paths are easy to identify. Experimentally, it's seen that the model's confidence is inversely proportional to node height: at low heights, it clearly separates correct options from incorrect ones, whereas at greater heights, this distinction becomes blurred—therefore, planning in continuous latent space proves advantageous.

This is an interesting approach that strongly resonates with LCM (Large Concept Model), except that LCM immediately worked at the level of individual large thought-sentences, while here they're rather eliminating tokens for intermediate calculations. Perhaps somewhere in between is an approach with latent concepts for objects, actions, and properties, though I haven't seen such an approach yet. I globally believe in this direction of latent reasoning and latent everything. Thought vector is a thing.
In the meantime, enjoy this lovely song.