

Large Concept Models: Language Modeling in a Sentence Representation Space
Authors: LCM team, Loïc Barrault, Paul-Ambroise Duquenne, Maha Elbayad, Artyom Kozhevnikov, Belen Alastruey, Pierre Andrews, Mariano Coria, Guillaume Couairon, Marta R. Costa-jussà, David Dale, Hady Elsahar, Kevin Heffernan, João Maria Janeiro, Tuan Tran, Christophe Ropers, Eduardo Sánchez, Robin San Roman, Alexandre Mourachko, Safiyyah Saleem, Holger Schwenk
Paper: https://arxiv.org/abs/2412.08821
Code: https://github.com/facebookresearch/large_concept_model
Another impressive work from Meta (BLT was also their project).

Working in a Sentence Representation Space
We want to work at different levels of abstraction. The brain, obviously, can do this, and our thinking doesn't operate solely at the word level. We have some kind of top-down process for solving complex problems. For example, when creating a long document, we (usually) first plan its high-level structure, and then start adding details at lower levels of abstraction. Current LLMs work rather differently, with the token level being their everything. Maybe there are some implicit hierarchical representations inside them, but having them explicitly would be more useful. Having reasoning and planning at this level would also be valuable. It would be even better to have this level independent of specific language and modality — the same thought can be expressed in different languages and modalities, such as text or voice.
We want to (again) move away from tokens. In BLT, we moved to latent tokenization not visible from the outside, and here, we're moving to a higher-level embedding space for concepts. We want to model the reasoning process at the semantic level rather than tokens and have an LCM (Large Concept Model) instead of an LLM.

To test this idea, we limit ourselves to two levels: 1) subword tokens and 2) concepts. A concept is understood as an abstract indivisible idea, often corresponding to a sentence in a document or an utterance in spoken language. Unlike single words, this is a suitable element for achieving language independence.
For this approach, we need a sentence embedding space with an accessible encoder and decoder. They chose FAIR's SONAR, which supports 200 languages (all languages from the No Language Left Behind project) for text inputs/outputs, 76 languages for speech input, and English for speech output. SONAR outperforms LASER3 and LabSE in quality and is available in the repo. The embedding size is 1024 float numbers (which means a typical sentence in embeddings will take several times more space; in the work, 1TB of text required approximately 15-20TB of embeddings).
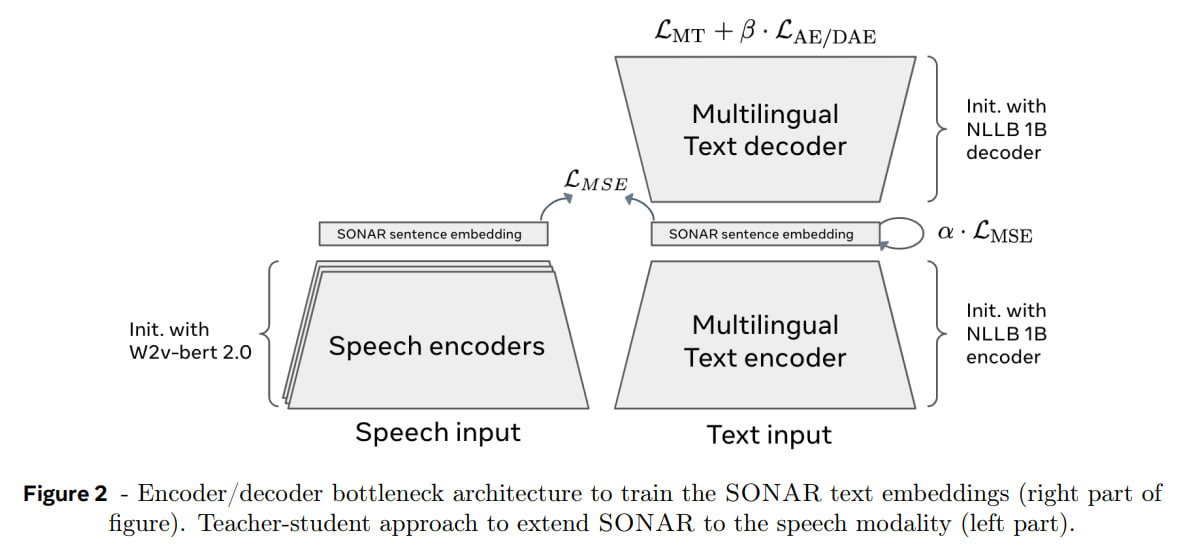
With all this, we can get a sequence of concepts (sentence embeddings) from the input text through the SONAR encoder. Then process this sequence with LCM, generating a new sequence of concepts at the output. And then decode it with SONAR into a sequence of tokens. SONAR's encoder and decoder are taken as-is and aren't trained, only LCM is trained.
What's beautiful is that the same sequence of concepts from LCM can be decoded into different languages and modalities without needing to rerun the entire reasoning process. LCM doesn't know anything about the languages or modalities from which its input data came. This creates elegant modularity — train an encoder/decoder for a new language, and the already trained LCM automatically works with it. The paper includes a table about the number of supported languages in different modalities; LCM, with its 200 languages for text, beats everyone here, but it's not entirely clear how the numbers for GPT/Gemini/Claude were obtained, as I haven't seen a declared list of supported languages for these models. Also, it would be interesting to look at concepts that don't decode equally well into different languages.

A separate benefit of this approach for processing long documents is that the sequence of concepts is at least an order of magnitude shorter than the sequence of tokens, making it easier to process with a transformer with a fixed context window (or more can fit in).
To some extent, LCM resembles LeCun's JEPA, which also predicts representations of the next observation in embedding space. But JEPA focused on learning such a space in a self-supervised mode, while LCM focuses on accurate prediction in an existing embedding space (though merging these two approaches probably makes sense).
So, working in embedding space, to train LCM we need to prepare a text dataset and convert it through SONAR into embeddings, one for each sentence. In practice, this isn't so simple; exact segmentation isn't always easy due to dataset errors or specific formatting. Additionally, long sentences can be too complex for encoding/decoding through SONAR, and the quality will suffer. Eventually, they chose Segment any Text (SaT) for sentence splitting with an additional segment length limit — anything longer than 250 characters (we'll see this number again soon) gets split; this method is called SaT Capped.
LCM must conditionally generate continuous embeddings based on context. This differs from LLM work, where you need to output a probability distribution over discrete tokens in the vocabulary. A straightforward approach would be to train a transformer to generate embeddings with an objective of minimizing MSE loss. This would be called Base-LCM. This isn't so simple because a given context can have many suitable but semantically different continuations, as seen in image generation with diffusion models, where one prompt produces quite different images. And in general, that area has many developments in learning conditional probability distributions for continuous data, so another logical variant to try is a diffusion model, Diffusion-based LCM. Finally, another option is quantization and return to the task of generating discrete elements, Quantized LCM.
LCM Architectures
Let's go through the LCM variants in detail.
Base-LCM serves as a baseline; it's a standard transformer decoder that converts a sequence of preceding concepts (sentence embeddings) into a sequence of future ones. The transformer is surrounded by two simple networks on the input and output sides, PreNet and PostNet, handling normalization/denormalization and projection of SONAR embeddings into and out of the model's dimension. It's trained on a semi-supervised task of predicting the next concept, minimizing MSE loss relative to ground truth. Training documents are appended with an "End of text" suffix, enabling learning to generate variable-length documents. During inference, one stop criterion checks the proximity of the generated embedding to this suffix's embedding and stops generation if the proximity exceeds a given threshold; another stop criterion looks at the cosine similarity between current and previous embeddings and stops if it's above the threshold (both thresholds are set to 0.9).

Diffusion-based LCM also autoregressively generates concepts, one at a time, performing a specified number of denoising steps for each generated concept. It uses classifier-free diffusion guidance. There are One-Tower and Two-Tower model versions. In the first case, it's one transformer tower doing everything. In the second, a separate tower (contextualizer) handles encoding the preceding context, while the second (denoiser) generates new concept embeddings and uses cross-attention to look at the context from the first tower.

Quantized LCM uses Residual Vector Quantization and then works similarly to regular LLMs predicting discrete units. Here, you can use temperature and top-p/top-k parameters. They try to build the architecture as similar as possible to Diffusion-based LCM for easier comparison.
All models are made with approximately 1.6B trainable parameters. Base-LCM has 32 layers and 2048 hidden dimension, One-Tower is similar. Two-Tower has 5 layers in the contextualizer and 13 in the denoiser. Quant-LCM is similar to One-Tower but with different output dimension.
Evaluations
They pre-trained on FineWeb-Edu (apparently English-only), evaluated pre-training results on four datasets (ROC-stories, C4, Wikipedia, Gutenberg) using next sentence prediction metrics.
Overall, diffusion LCMs showed better results. They did instruction-tuning on Cosmopedia, with similar results. Along the way, they showed the importance of hyperparameters for diffusion.


They showed that LCM scales well with context length, requiring fewer FLOPS for the same context length in tokens. I understand this is purely because a concept corresponds to a sentence of multiple tokens, so there are fewer concepts, quadratic attention requires fewer resources (and this heavily depends on how paragraphs are split into sentences). It's also important to remember that each LCM inference includes three steps: 1) SONAR encoding, 2) transformer-LCM, 3) SONAR decoding. On very short sentences (less than 10 tokens), LLM is better than LCM in FLOPS.

They investigated the fragility of SONAR's embedding space. Fragile embeddings are those where small perturbations in the space can lead to substantial information loss during decoding. This can be evaluated, for example, by BLEU between the original and post-perturbation text (called Auto-Encoding BLEU). They fine-tuned a decoder that is more resistant to noise, which performs better by this metric.

You can also evaluate by cosine similarity through an encoder independent of SONAR. They drew curves showing how metrics deteriorate with increasing text length and noise level. It gets really bad at lengths over 250 characters (the maximum length we chose to split sentences). Meanwhile, metrics behave somewhat differently, and SONAR fine-tuning helps quite a bit. In short, these embeddings aren't simple, and there's room for investigation.

After experiments, they scaled up the Two-Tower diffusion variant to 7B. This version has 5 layers in the contextualizer, 14 in the denoiser, and a hidden dimension of 4096. They pre-trained on 2.3B documents with 2.7T tokens and 142.4B concepts/sentences. The context was expanded to 2048 concepts. This resulted in the Two-Tower-7B model. They fine-tuned it on open instruction tuning datasets, creating Two-Tower-7B-IT.
They tested summarization on CNN DailyMail and XSum. They looked at Rouge-L, input trigram overlap ratio (OVL-3), output four-gram repetition ratio (REP-4), metrics from Q4, Q5 from SEAHORSE, and another metric from a classifier trained on CoLA about whether sentences are linguistically acceptable.

Baselines for comparison were T5-3B, Gemma-7B, Llama-3.1-8B, Mistral-7B-v0.3. T5 is much smaller but, unlike others, was fine-tuned on the given datasets.
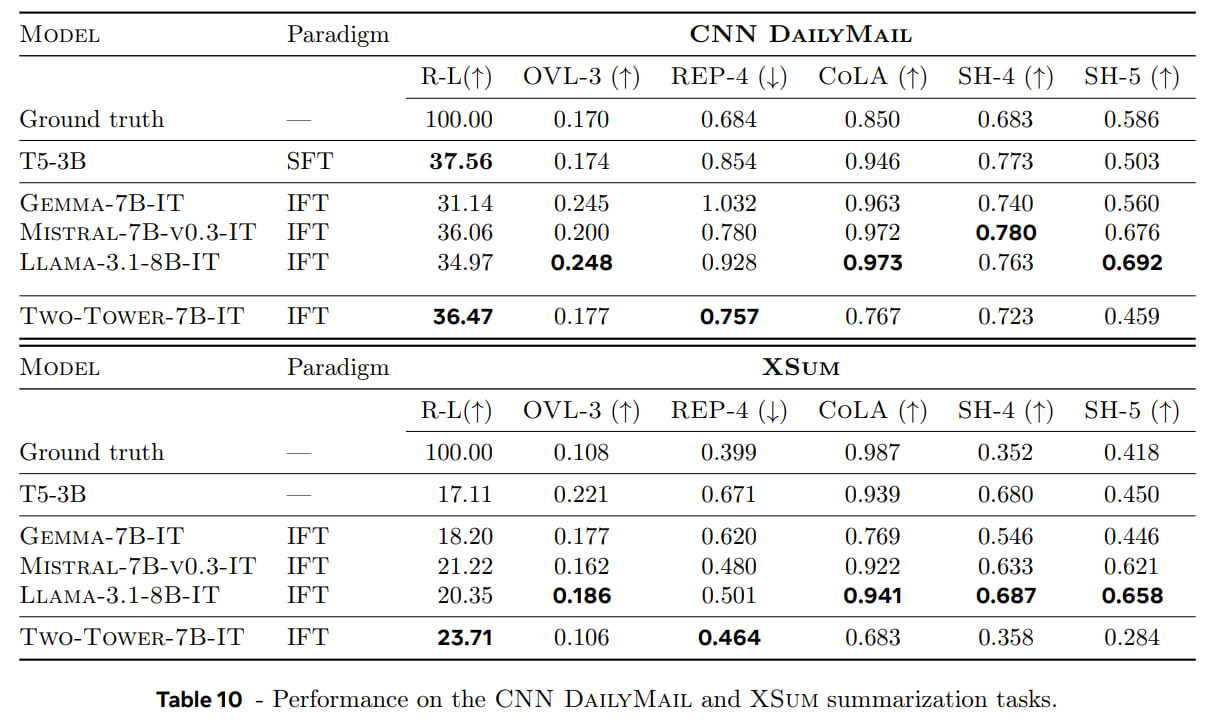
LCM outperformed instruct-finetuned LLM in Rouge. OVL-3 shows summaries are more abstractive than extractive. REP-4 shows fewer repetitions, CoLA classifier shows less fluent summaries. But human ground truth also scores lower on this metric than LLMs.
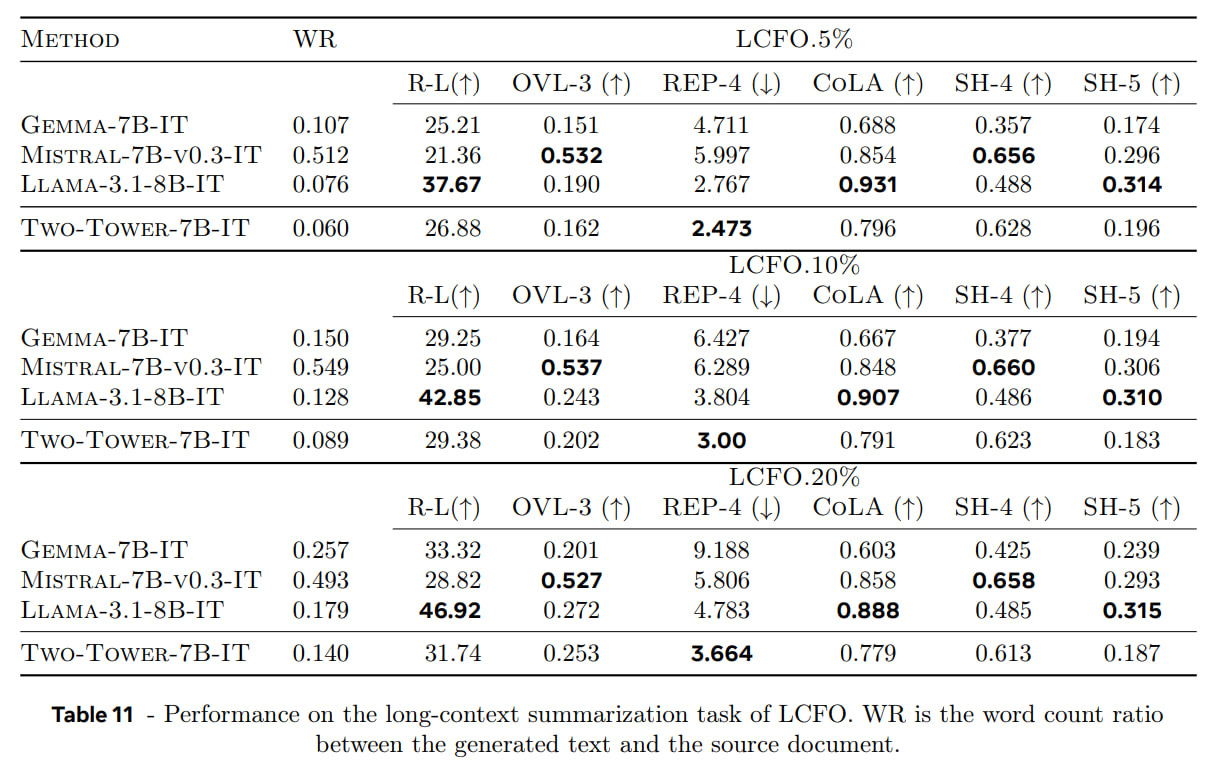
Long-context summarization is generally better than Mistral and Gemma but worse than Llama (they suspect contamination or poor performance of other models on long context).
LCM extensions
The paper then proposes several LCM extensions.
Summary Expansion involves writing long text from short summaries, essentially the reverse of summarization, though the task isn't to recreate the original document but rather generate coherent text. Based on available metrics, it generally performs worse than LLMs.

In Zero-shot generalization, they test the model on other languages available in XLSum. LCM saw nothing but English in training, while Llama was fine-tuned on eight languages from the list and saw many others in pre-training. Overall, LCM generalizes very well to other languages, often beating Llama, especially on low-resource languages. What numbers would we see if LCM trained on a proper multilingual corpus?

For the Explicit planning task, another planning model (LPM) generates a high-level plan of what should be done next, and LCM generates a sequence of concepts + break concept (which can indicate paragraph end) based on this plan. The final setting is called LPCM. They evaluated coherence in LLM-as-a-judge mode (Llama-3.1-8B-IT). On Cosmopedia, LPCM seemed better than just LCM, but does 2.82 ± 0.62 versus 2.74 ± 0.70 mean anything with such large and intersecting confidence intervals? Not sure, it's a peculiar setting — the dataset is generated by LLM, evaluated by LLM, there are many questionable factors here.

Well, okay, this is a proof of concept work, and as proof it's good. The fact that they haven't set a new state of the art right now doesn't matter. We probably won't see a new ConceptLlama tomorrow, but this is an interesting approach, and I like it. I also don't believe that predicting the next token is what we globally need, and it's good to be able to work at a level higher than usually happens in LLM. I also really like the modularity. It will be interesting to see how this develops further.