
BLT: Byte Latent Transformer
Patches Scale Better Than Tokens

Title: Byte Latent Transformer: Patches Scale Better Than Tokens
Authors: Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, Srinivasan Iyer
Paper: https://arxiv.org/abs/2412.09871
Code: https://github.com/facebookresearch/blt
Byte Latent Transformer (BLT) presents an interesting approach to moving away from fixed-vocabulary tokenization and working at the byte level in LLMs. It dynamically splits the input stream into patches, determining their boundaries based on next-symbol entropy, and operates on these patches. If the data stream is simple and predictable, we can make patches longer, and if things get complex, we can allocate more compute to a larger number of patches. This gives us dynamic compute allocation.
This is an interesting and non-trivial work. Let's dive into the details!
Hidden debt of the Tokenization
Tokenizers are an interesting story that exists alongside the beautiful and differentiable end-to-end training of transformers, disrupting this idyllic end-to-end picture. Tokenizers are also trained, but not through backpropagation - instead, they use a relatively simple algorithm that selects the most frequently occurring sequences in the language and builds a vocabulary of predetermined size from them.

People sometimes forget about tokenizers, but they're an incredibly important component because poor tokenization severely impacts the final quality of various tasks. For example, it's difficult to train a transformer to perform arithmetic operations if numbers are tokenized not by individual digits but by arbitrary multi-digit chunks. Another typical example is applying the model to languages where tokenization wasn't well-trained, resulting in words being split into tokens that don't reflect the actual linguistic patterns and don't correspond to anything meaningful. The story about incorrectly counting the letters "r" in "strawberry" also relates to this.

There have been attempts to overcome this by training models on bytes or UTF-8 characters, but the main problem is that this significantly increases sequence length. Sure, we now have contexts up to 2M, but that's only recently appeared and is quite expensive.
Of course, it would also be nice to get rid of huge softmaxes over vocabulary size... Input and output embedding tables can be quite large. There's always a tradeoff between vocabulary size and computations. Increasing vocabulary size increases average token length, which reduces the number of elements in the sequence that the model works with. But this also increases the dimension of the final projection layer, so there's not much room for manipulation here. Llama 3's embedding size increased 4x compared to Llama 2, while the average token size only grew from 3.7 to 4.4.

Here comes BLT
The idea that the model should dynamically allocate compute where it's needed led to the Byte Latent Transformer (BLT) architecture, which consists of three transformer blocks: two small local byte-level models and a large global latent transformer. The latent transformer operates on patch representations, while the two local models handle encoding the input byte sequence into patches and decoding patch representations back into bytes.
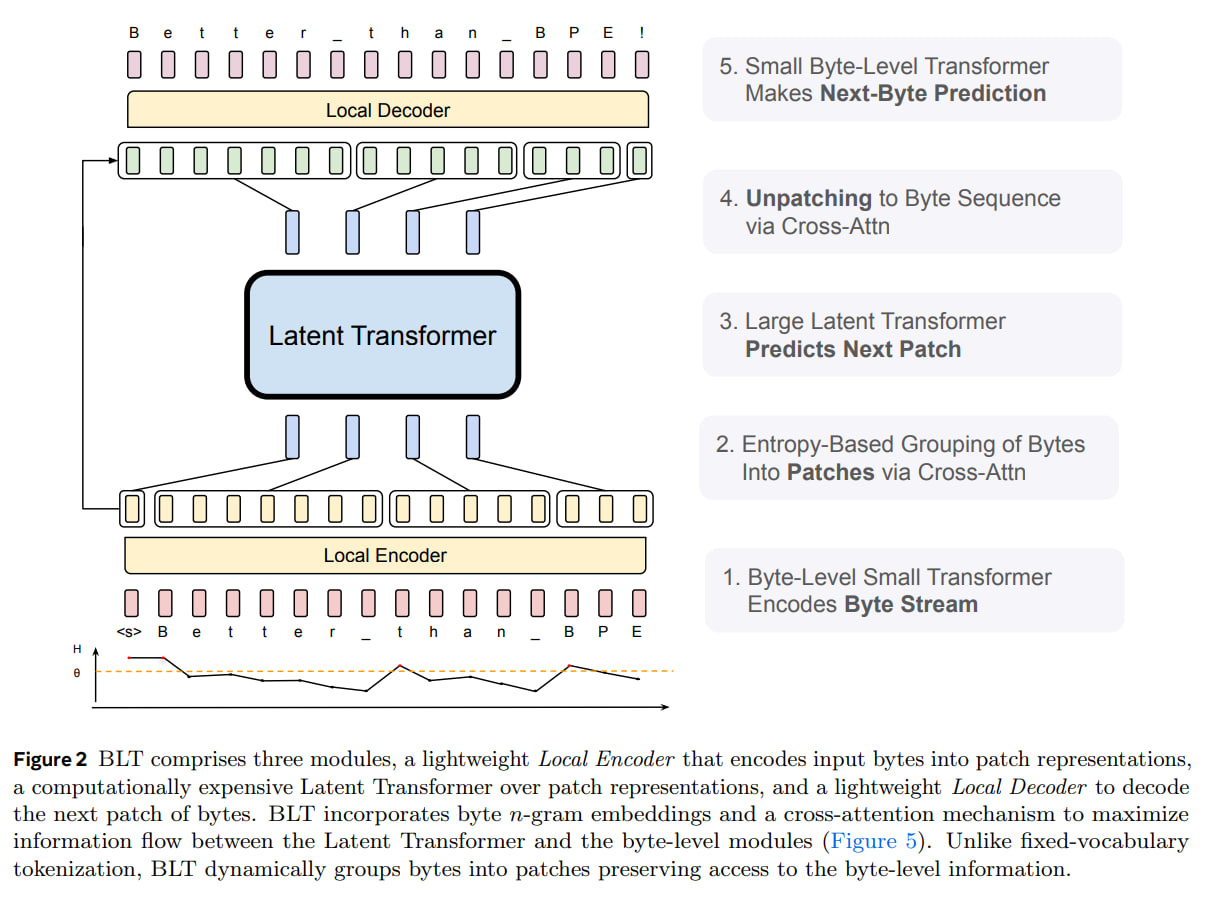
There are multiple ways to split the input byte stream into patches. The simplest variant is Strided Patching Every K Bytes — fixed-size patches of k bytes. You can control the amount of computation by setting the patch size. But there's no dynamic compute allocation, and we'd like to allocate more for complex sections and less for simple ones. Another problem is an inconsistent splitting of the same words depending on their position. It's unclear what benefit this provides besides harm.
A more intuitive variant is Space Patching, splitting on whitespace characters, which are likely natural sentence boundaries. But this might work poorly with some languages and domains. And you can't adjust patch size.
Entropy Patching is a more interesting variant and essentially a data-driven approach that uses entropy estimates to determine boundaries. Usually, the first bytes in words are the hardest to predict and have maximum entropy, which then decreases because everything becomes predictable. To get entropy estimates, they train a small byte-level autoregressive language model on the same corpus as the transformer itself, and then calculate next-byte entropy through its probabilities. Then, you need to somehow divide the sequence into tokens. For example, you can define token boundaries when entropy exceeds a given global threshold. Another method identifies high entropy relative to the previous one, i.e., points where the roughly monotonic entropy decrease breaks (essentially when the delta of entropies of the last two symbols exceeds a given threshold). All this can be done with light preprocessing in the data loader.

There's a significant difference between patches and tokens (e.g., BPE) in that with tokens, the LLM doesn't have access to byte-level features (and particularly doesn't know how many R's there are). BPE also doesn't satisfy the incrementality property of patching, meaning it shouldn't depend on future parts of the sequence. BPE can tokenize the same prefix differently depending on what comes next. This doesn't work for BLT — the transformer needs to decide in the moment whether there's a patch boundary at the current byte or not.
Now to BLT itself.
BLT Architecture
Remember, there are three parts:
Latent Global Transformer
Local Encoder
Local Decoder
The Latent Global Transformer is a regular large and heavy autoregressive transformer that maps the sequence of input patch representations to a sequence of output patch representations. This model uses a block-causal attention mask that restricts attention to positions up to (and including) the current patch in the current document. This is where most FLOPS are spent.
The Local Encoder is a lightweight transformer with far fewer layers that maps the input byte sequence to patch representations. The special feature of this encoder is that after each transformer layer there's cross-attention, whose task is to pool byte representations into patch representations.
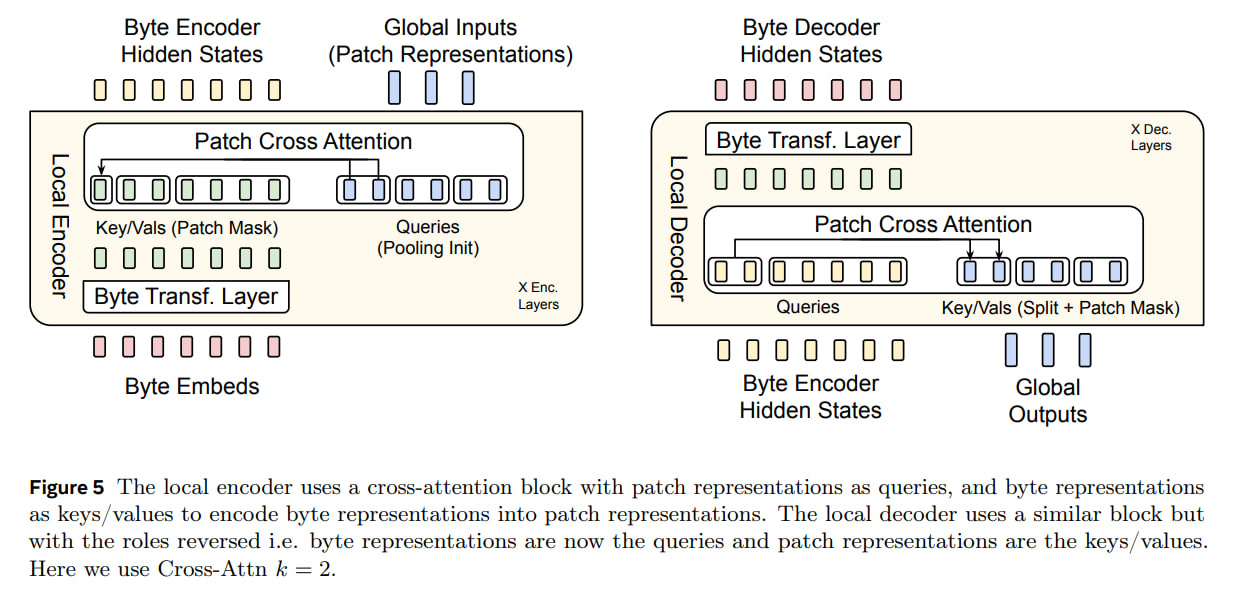
The transformer layer uses a local block causal attention mask, where each byte can "look at" a fixed-size window of preceding bytes (crossing patch boundaries is allowed).
Byte embeddings are quite clever, augmented with hashed embeddings. For each byte, n-grams from previous bytes (byte-grams) are computed for n=3..8, mapped through a hash function to a fixed-size embedding table, and added to byte embeddings before being sent to the local encoder. Besides n-gram embeddings, they also tried frequency-based ones.
Encoder Multi-Headed Cross-Attention is very similar to Perceiver's input cross-attention, except latents are now not a fixed set but correspond to patch representations and only look at bytes from the given patch. Query vectors correspond to patches, and Key/Value vectors correspond to bytes (hence, it is called cross-attention, which is different from self-attention, where Query/Key/Value all come from the same sequence).

The Local Decoder is also a lightweight transformer that decodes the sequence of patch representations into output bytes. It predicts the sequence of output bytes as a function of already decoded bytes and takes as input the hidden byte representations from the local encoder. Here, too, there's an alternation between transformer and cross-attention (now Q is byte representations, and K/V are patches, the opposite of what was in the local encoder), and it starts with cross-attention.
Evaluation
They used datasets from Llama 2 with 2T tokens and a new BLT-1T with 1T. The entropy model is a 100M parameter transformer, 14 layers, 512 hidden dimension and attention with a sliding window of 512. Transformer blocks generally follow Llama 3 recipes.
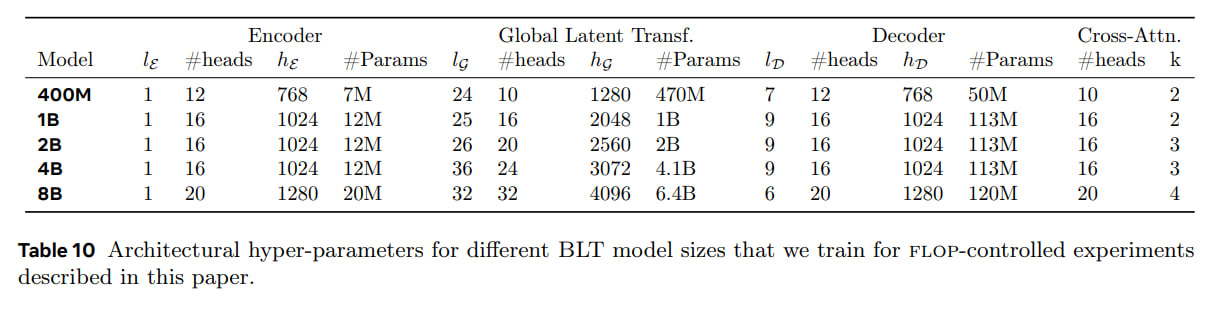
They trained a family of models sized 400M, 1B, 2B, 4B and 8B.
First, they trained compute-optimal BPE and BLT models of sizes 1B-8B. BLT either matches or exceeds BPE models and maintains this property with scaling. They claim BLT is the first byte-level transformer with the same scaling trends as BPE transformers in compute-optimal mode.

Along the way, they confirmed once again that tokenization matters — models with Llama 3's tokenizer outperform models with Llama-2's tokenizer on the same data.
In beyond the compute optimal ratio mode, BLT-Entropy trained on 4.5T bytes surpassed Llama 3 trained on 1T tokens, with the same FLOPS.

BLT models get an additional scaling dimension - you can increase model size simultaneously with patch size under the same budget. Large patches save compute, which can be directed toward growing the latent transformer that will be called less frequently. BLT's scaling curve is much better than BPE's. At small budgets BPE is better, but BLT quickly overtakes it.

On byte-level noise robustness tasks, BLT rules, sometimes strongly beating Llama 3.1 trained on 16 times more tokens.

The examples from the CUTE benchmark show that BLT performs much better on sequence manipulation tasks (which is very close to the “strawberry” example).

On translation in 6 common languages and 21 low-resource languages, BLT also performs better by BLEU score.

Another interesting experiment involved initializing BLT's global transformer from a pretrained (on tokens) Llama 3.1. Such BLT significantly outperforms both BLT and Llama 3 trained from scratch (on bytes and tokens, respectively), all with the same FLOPS budget.

In principle, this can be used to convert tokenizer-based models to BLT. I expect a wave of conversions-finetuning of known models. This probably also says something about the universality of computations in the transformer backbone, which apparently aren't super strongly tied to tokens.
Overall, this is very interesting. I like this movement—the tokenizer always looked like a bolt-on hack to me. I think transitioning to such models should boost multilinguality, where rare languages significantly underperformed due to poor tokenizers not being trained on them. Compatibility between different models will probably increase, too (now many models are incompatible in the sense that they require different tokenizers, and you cannot use data tokenized for one model with another one). Finally, there will be fewer silly examples like the “strawberry issue”.
The only unclear thing is commercial model pricing—what will they charge for? Surely not latent patches, which people won't understand. Could they finally charge for understandable bytes or, better yet, characters?