

Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
The first really large non-transformer LLM!

Authors: AI21 Labs Jamba Team
Paper: https://arxiv.org/abs/2408.12570
Post: https://www.ai21.com/blog/announcing-jamba-model-family
Models: https://huggingface.co/collections/ai21labs/jamba-15-66c44befa474a917fcf55251
The release of the Jamba-1.5 models, scaled versions of the Jamba models from March 2024, went largely unnoticed.
To recap, Jamba is a hybrid model combining SSM (State Space Models) and transformer components, specifically Mamba + MoE (Mixture-of-Experts) + transformer layers.
Jamba
Originally, a Jamba block consisted of eight layers: every second layer was an MoE (four in total), three layers were Mamba, and one was a transformer layer.
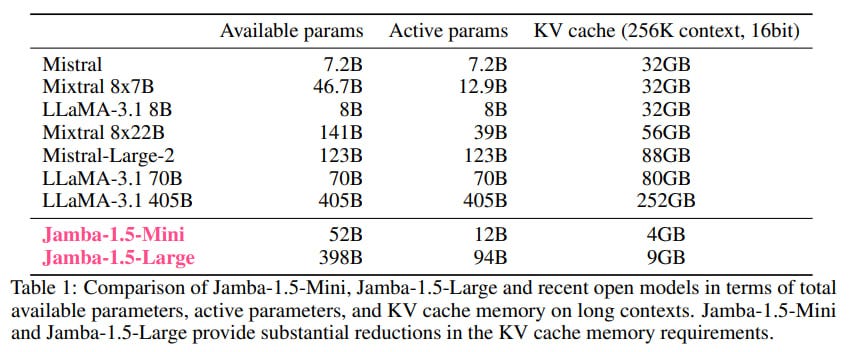
The small number of transformer layers allowed for a reduction in the size of the KV cache (eight times smaller than a standard transformer with the same number of layers).
The original Jamba contained 52B parameters, of which only 12B were active at any given time (due to the MoE).
Thanks to its smaller memory footprint, the model could work with a context size of 140k tokens on a single A100-80 Gb GPU, much more than Llama-2 70B or Mixtral 8x7B could handle. The total context size of the model was 256k tokens. This also enabled larger batches, so the overall throughput starting from a batch size of 4 was higher than that of the mentioned competitors.
Regarding quality, the original Jamba performed well compared to Llama-2 13B-70B, Gemma 7B, and Mixtral.
This was a base model with no alignment or instruction tuning. It was available under the Apache 2.0 license.
Jamba-1.5
Now, in August, an update has been released: Jamba-1.5, which includes two models:
Jamba-1.5-Mini: 12B/52B active/total parameters (same as the original Jamba)
Jamba-1.5-Large: 94B/398B active/total parameters
The authors experimented with Mamba-2 blocks, but they did not perform better, so the architecture retained Mamba-1.
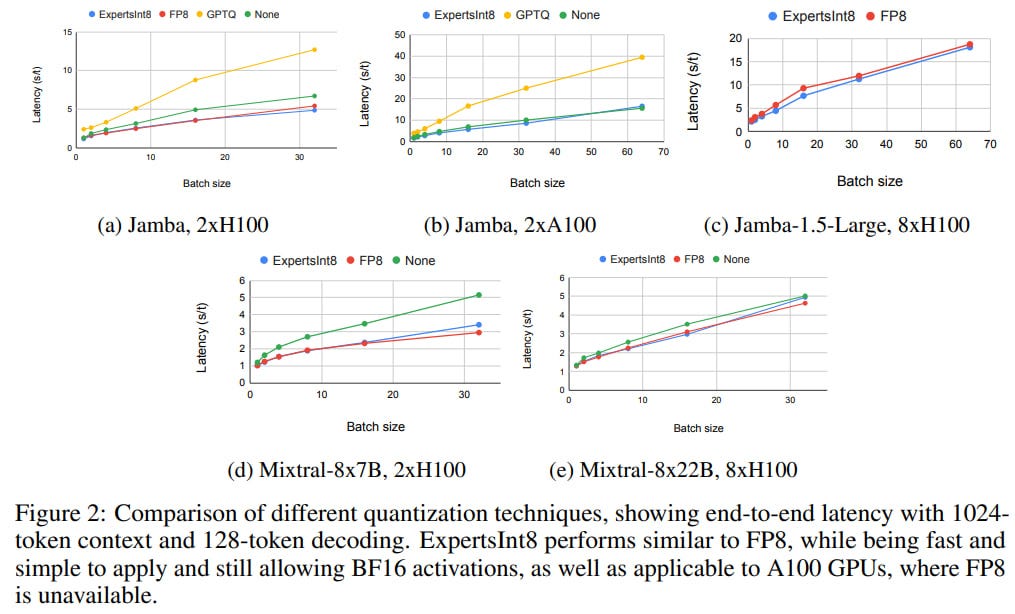
For efficient inference, a new quantization method called ExpertsInt8 was developed, where the MoE and MLP weights are quantized to INT8 and then converted to BF16 before computation to utilize fast BF16 kernels. All of this happens inside vLLM in the fused_moe kernel. On H100, ExpertsInt8 latency matches FP8, and on A100, where FP8 is not available, it significantly outperforms GPTQ.
Activation loss was added during training because some activations grew as large as 4e6, which didn't seem to cause any issues but was addressed just in case.
Jamba's throughput and latency are good compared to competitors (Llama 3.1 8B, Mixtral-8x7B, Mistral Nemo 12B for the Mini; Llama 3.1 70B, Mistral Large 2, Llama 3.1 405B for the Large), especially with large context sizes.
The training process consisted of three phases using an internal dataset.
In the pre-training phase, compared to the previous Jamba, multilingual data was added, focusing on English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew. This was followed by mid-training focused on long documents and post-training with SFT on high-quality conversational, skill-specific data with long context. As far as I understand, there was no separate preference tuning like PPO/DPO; they managed with high-quality synthetic data, filtering, and SFT.
The model was trained with function calling. I’m glad this topic (open multilingual model with function calling) is evolving.
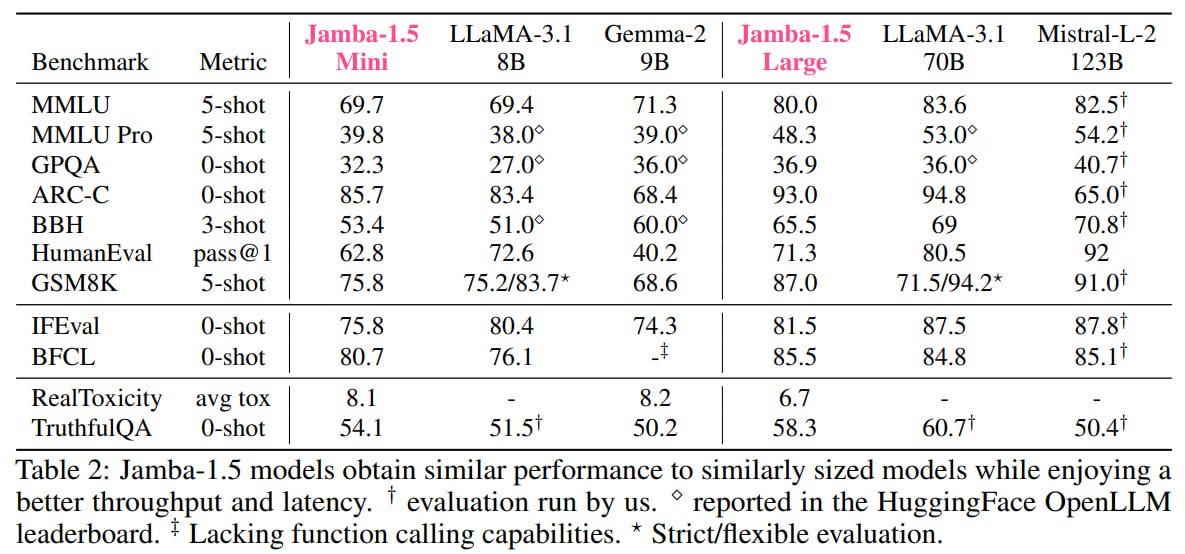
The final models are comparable to similarly sized competitors from the Llama-3.1, Gemma-2, and Mistral-Large-2 families.

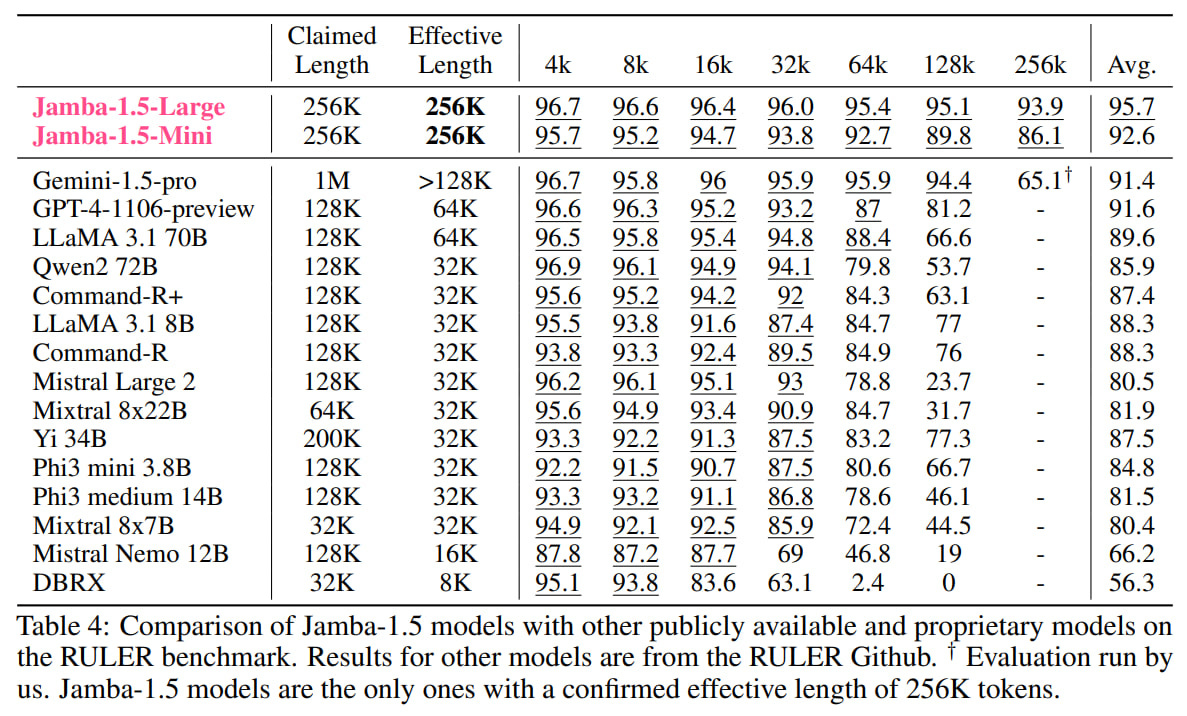
The authors specifically tested the model capabilities on tasks with large contexts using the RULER benchmark (https://arxiv.org/abs/2404.06654), featuring 8 variations of needle-in-a-haystack tasks. They claim to be the only ones supporting an effective context size of 256k, while others, despite claiming longer lengths, fail.
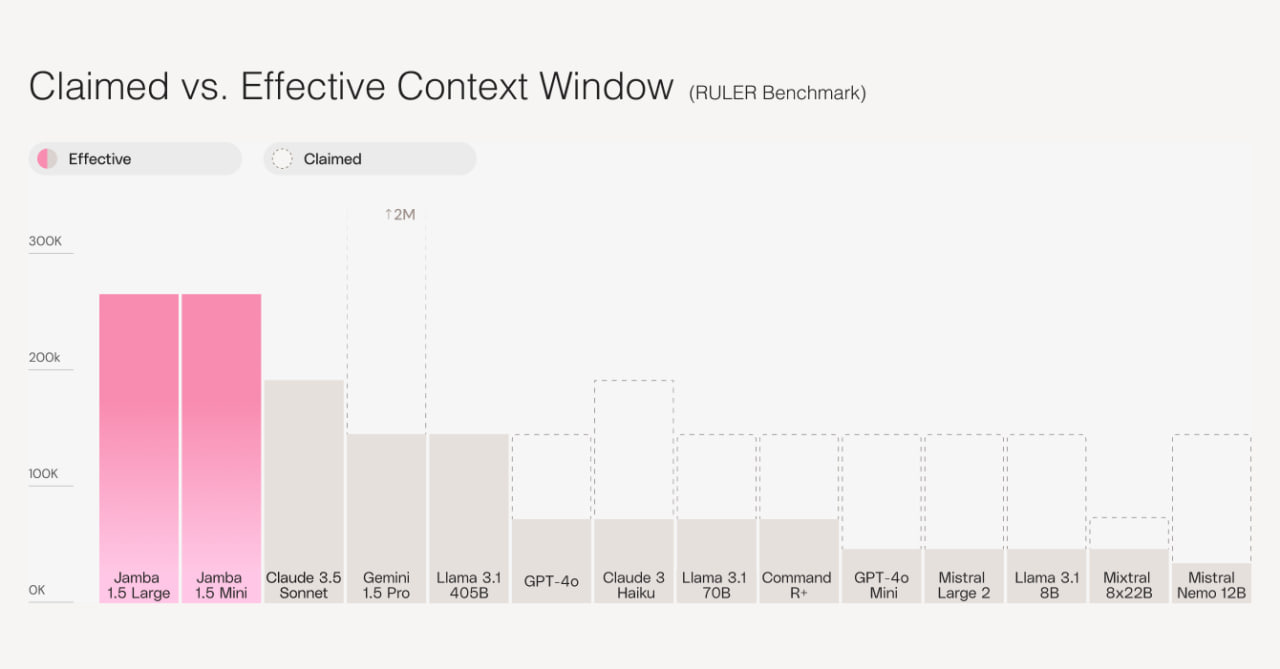
The models also perform well on ∞BENCH.

In short, it looks promising. This seems to be the first truly large non-transformer (well, almost) model.

However, the new model's license has changed from Apache 2.0 to the Jamba Open Model License, which is personal, revocable, and prohibits commercial use if you earn more than $50M a year (problems nice to have).
Overall, an interesting development, and we look forward to more non-transformer SSMs and other types of models. NVIDIA also had a hybrid Mamba-2-Hybrid (https://arxiv.org/abs/2406.07887), and there's also StripedHyena (Hyena convolutions + attention), but the latter two were small, 7-8B.