
Mamba-2 is here!
Transformers are both RNNs and SSMs

“Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality”
Authors: Tri Dao, Albert Gu
Paper: https://arxiv.org/abs/2405.21060
Code: https://github.com/state-spaces/mamba
X: https://x.com/_albertgu/status/1797651223035904355

The authors of Mamba have released an updated version of their model, Mamba-2. It has a larger state internal state (16 -> 256), trains twice as fast, and has simpler code (30 lines).

The original Mamba was good, but the authors were not completely satisfied. Firstly, attention mechanisms remained outside the SSM paradigm, and it would be interesting to integrate them. Secondly, although Mamba was already fast (with an efficient implementation through selective scan), it still lagged behind the computational efficiency of attention mechanisms and matrix multiplication.

The authors approached the problem fundamentally and proposed a framework called structured state space duality (SSD), which unifies structured SSMs and variants of attention in a new SSD layer. They demonstrated the equivalence of SSMs and a family of structured matrices called semiseparable matrices.

The main idea is that different methods of computing SSMs can be expressed as structured matrix multiplication algorithms. Additionally, the authors developed the theory of linear attention (“Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention”, https://arxiv.org/abs/2006.16236 — the title of the current work seems to allude to this) and generalized the results on its recurrent form to structured masked attention (SMA).

Finally, they combined SSM and SMA, showing that they have a large overlap where they are dual to each other and are essentially a model expressed by the same function. They also proved that any kernel attention method with a fast recurrent form must be an SSM.

This 52-page article contains a lot of mathematics that I have not yet delved into, but the authors have written a wonderful series of posts that can be read instead of the article:
Part 1: Overall about the SSD model (https://goombalab.github.io/blog/2024/mamba2-part1-model/)
Part 2: Theory with a mathematical analysis of the SSD framework (https://goombalab.github.io/blog/2024/mamba2-part2-theory/)
Part 3: Algorithmic part and code (https://goombalab.github.io/blog/2024/mamba2-part3-algorithm/)
Part 4: System-level optimizations for large-scale training, fine-tuning, and inference (https://goombalab.github.io/blog/2024/mamba2-part4-systems/)
The original Mamba was a selective SSM (S6) with a diagonal structure. SSD goes even further and constrains the diagonal of matrix A, where now all elements must have the same values (i.e., a scalar multiplied by the identity matrix). The old Mamba was applied to each input channel separately, while the new one processes multiple channels at once (e.g., 64) with a common recurrence. This improves computational efficiency and speeds up training.
However, theoretically, Mamba-2 has less expressiveness than Mamba-1, and the first Mamba may also be better in inference. This has yet to be studied and awaits further research.
The framework allows established techniques for attention to be transferred to SSM architectures and implements analogs of heads (MHA) in SSM. The network block architecture (Mamba block, see the post on Mamba) is slightly modified compared to SSM. Grouped-value attention appears in the head structure, and all data-dependent projections (parameters A, B, C in SSM) are now obtained in parallel with input X, rather than sequentially as before. Various optimizations have been implemented, making the model Tensor Parallelism-friendly.
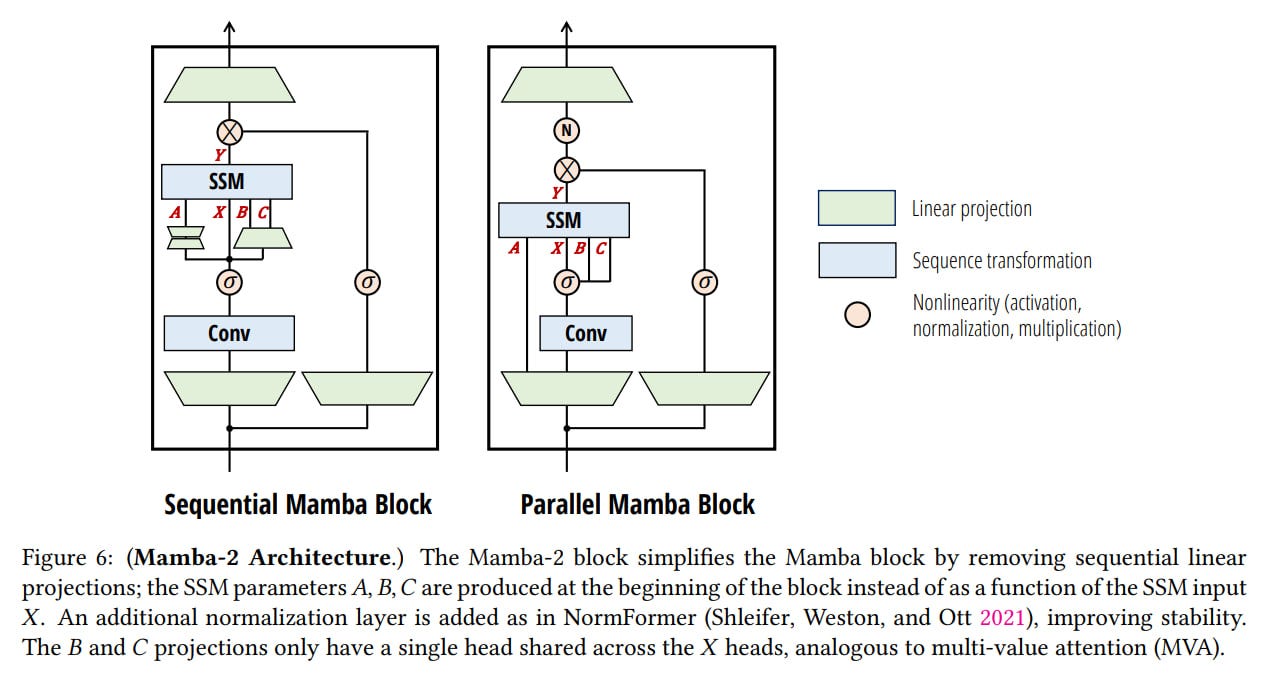
No giant models have been trained; the largest seems to be 2.7B. There have also been no mass tests of Mamba-2 yet, but the authors believe the new model should be comparable or better.

On The Pile, the loss curves of the new Mamba are slightly below the old one. In the complex multi-query associative recall (MQAR, https://arxiv.org/abs/2312.04927) task, Mamba-2 is significantly better than Mamba-1.

We look forward to further development and adoption.