
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
SSMs are competitive with Transformers, finally!

Authors: Albert Gu, Tri Dao
Paper: https://arxiv.org/abs/2312.00752
Code: https://github.com/state-spaces/mamba
Twitter-thread: https://twitter.com/_albertgu/status/1731727672286294400
A fresh continuation of the story about state space models (SSM), specifically structured SSM or S4.
S4 has a recurrent formulation and can also be implemented via convolution, achieving linear or near-linear complexity with respect to the length of the input sequence. These models have shown promising results in modeling long sequences, and there's been anticipation about beating transformers in large-scale text-based models. So far, the main successes have been with continuous signals like audio and vision. The current work introduces a new class, selective state space models, bridging this gap by achieving transformer-level quality with linear input size scaling.

S4 shortcomings
Recall that S4 is defined by four parameters: A, B, C, and ∆, which determine a two-stage seq2seq transformation, where input x(t) is transformed into hidden state h(t), and in turn, into output y(t). The new work finally aligns with standard notations for input and hidden state, unlike the S4 work where the input was u(t) and the hidden state x(t). The recurrent implementation looks like this:
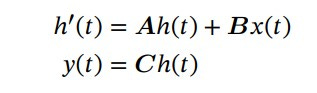
In the first stage, continuous parameters ∆, A, B are discretized according to a given rule, and the second stage involves computation either through linear recurrence or global convolution. Recurrence is good for inference, while convolution is parallelizable and convenient for training.
The model possesses the Linear Time Invariance (LTI) property, meaning its dynamics are constant over time. This allows efficient computation via convolution. The current work demonstrates the fundamental limitations of LTI and the challenge of efficient implementation.
Thanks to the structure in the parameter matrices, each of them (A, B, C) can be represented by N numbers. For processing an input sequence x of length L with D channels and batch size B, the SSM is applied independently to each channel, and the total hidden state has a dimension of DN. Therefore, processing the entire input requires O(BLDN) memory and computation.
The authors believe the fundamental issue in sequence modeling is context compression into a smaller state. We can look at the trade-offs of popular models from this perspective. Attention mechanisms are effective (yielding good results) but inefficient (requiring too many resources). Their inefficiency stems from not compressing context – the entire context in transformers is explicitly stored as a KV cache, leading to linear time inference and quadratic time training. In contrast, recurrent models are efficient – they have a fixed-size state, resulting in constant time inference and linear-time training. However, the quality of results depends significantly on how well the state retains the context.
This was demonstrated in two model tasks requiring context understanding, where constant dynamics are insufficient.

One task is Selective Copying, a modification of regular Copying, where the distance between remembered tokens can vary, and models need to selectively remember or ignore input depending on its content. The other is Induction Heads from Transformer Circuits, involving prefix matching within the context followed by copying. LTI systems fail these tasks.
Here comes S6 and Mamba
Ultimately, the authors argue that the fundamental principle for building sequence models is selectivity, the context-dependent ability to focus on or filter inputs into the sequence state. Their solution method allows parameters interacting with the sequence (∆, B, C) to depend on the input (via linear projections, but other variants are possible).
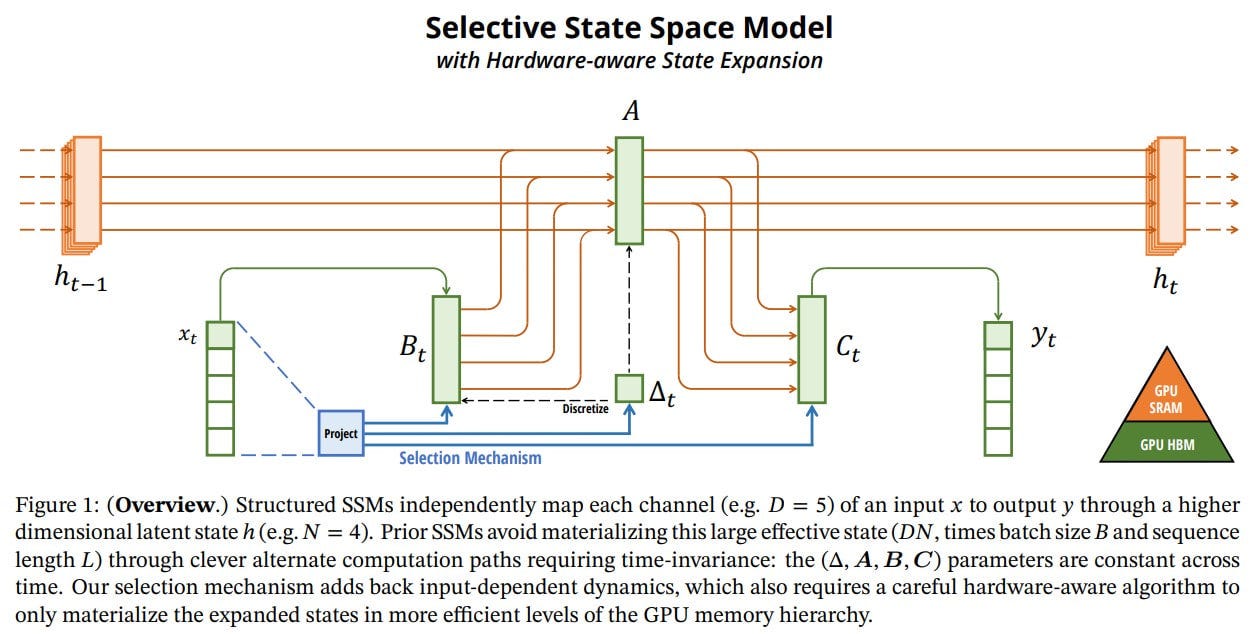
Effectively doing this is a challenge, and the authors implemented a parallel scan algorithm with smart use of GPU memory hierarchy – some processes occur in fast SRAM, others in slower HBM. Combined with kernel fusion and recomputation, they achieved an efficient implementation with memory requirements similar to an optimized transformer implementation with FlashAttention (Tri Dao, a co-author of the current work, also co-authored FlashAttention).
Selective SSM models in the work are sometimes called S6 models, because S4 + selection mechanism + computed with a scan.

The final architecture is a mix of SSM (here, H3 or Hungry Hungry Hippos, https://arxiv.org/abs/2212.14052) and MLP blocks from the transformer in one new block, which can then be homogeneously connected. Inside the block, model dimension D is first increased by a factor E=2, making most of the block's parameters linear projections at the input and output, rather than the SSM itself. It also includes SiLU/Swish activations and optional LayerNorm in the same position as in RetNet (https://arxiv.org/abs/2307.08621).
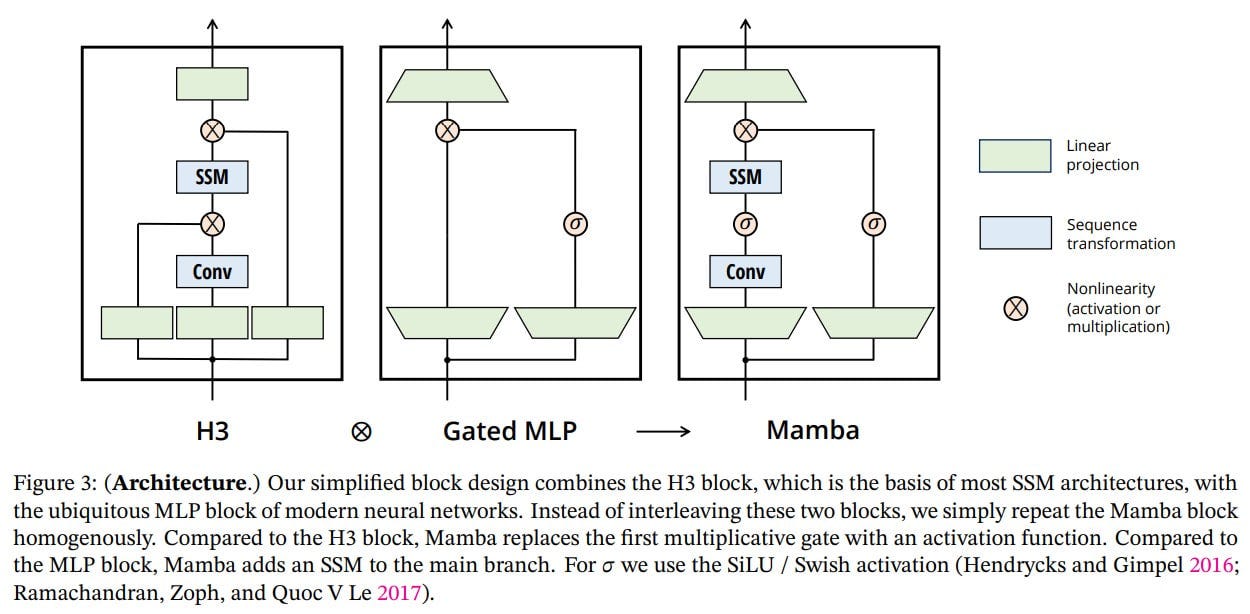
The resulting block, alternated with standard normalization (likely RMSNorm or LayerNorm) and residual connection, forms the architecture named Mamba.
The model uses real numbers (many previous SSMs used complex numbers) by default, and this works well everywhere except one task. The authors suggest that complex numbers might be useful in continuous modalities like audio/video, but not in discrete ones like text or DNA. The initialization is taken from S4D-Lin/S4D-Real.
Evaluations
The model was tested extensively.
First on synthetic tasks. Selective Copying works excellently, very close to 100%. Also great results on tasks with Induction Heads.

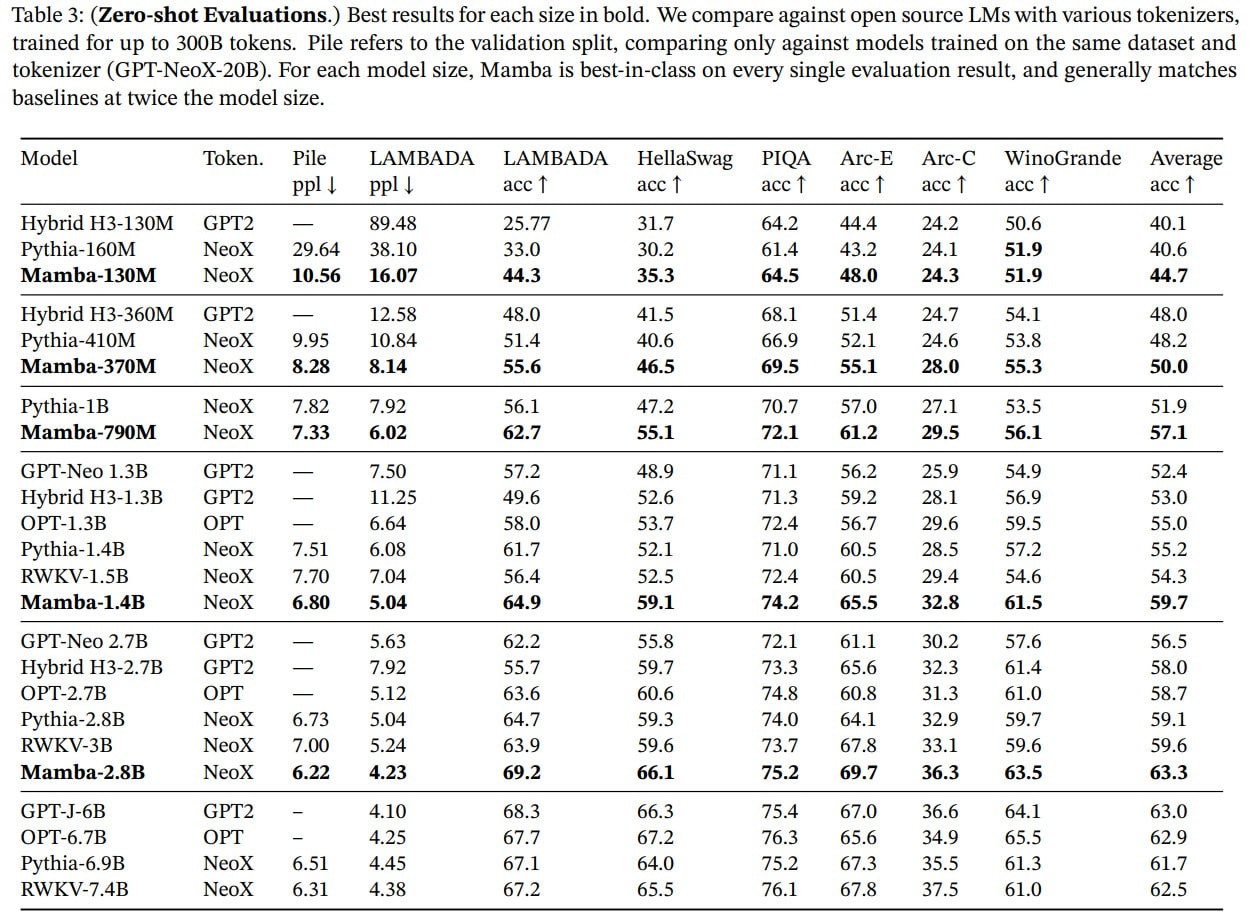
Tested on language modeling trained on Pile and using recipes from the GPT-3 paper. Compared with standard architecture (here GPT-3), and advanced transformers (designated as Transformer++), based on PaLM and LLaMa architectures. Tested on sizes from 125M to 1.3B parameters.

Ultimately, Mamba is the first non-attention model to reach the quality of strong transformer recipes.

On various downstream zero-shot tasks, it performs better than comparable-sized models like Pythia, GPT-Neo, OPT, RWKV (a separate post coming soon). Sometimes even better than models twice its size.
In DNA sequence modeling tasks, the scaling curves are excellent, and performance on downstream tasks is commendable.
In audio, it competed with SaShiMi (https://arxiv.org/abs/2202.09729), which was SoTA in autoregressive training. Beat it. In speech generation (SC09 dataset), it surpassed both SaShiMi and WaveNet with WaveGAN.

Performance-wise, the SSM scan implementation is very good, better than the best transformer implementation (FlashAttention-2) and 20-40 times better than the PyTorch scan. In inference, the throughput is 4-5 times higher than a comparable transformer (because of not needing a KV cache, allowing larger batches). Thus, Mamba-6.9B has higher throughput in inference than Transformer-1.3B.

Many interesting ablations were conducted. Both S6 blocks and the Mamba architecture rule. S6 is clearly better than S4, and Mamba compares favorably with H3 and is simpler.

Overall, a remarkable architecture! Awaiting something very large to be trained.
Incidentally, the non-transformer StripedHyena-7B (also from the SSM cohort) was recently released. We haven't written about the Hyena yet, but might get to it (as well as about Hippos). It appears comparable to Mistral 7B on benchmarks, which is cool. Mamba is probably even cooler, beating the regular Hyena (though this one is not regular).

I predict that 2024 should be the year of SSM LLMs.