
TinyLlama: An Open-Source Small Language Model
More SLMs!

Authors: Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu
Paper: https://arxiv.org/abs/2401.02385
Code: https://github.com/jzhang38/TinyLlama
The ranks of Small Language Models (SLM) have expanded! Introducing TinyLlama - a compact model with 1.1 billion parameters, trained on a massive 3 trillion tokens!

SLMs on the rise!
For comparison, the much larger 70 billion parameter Chinchilla (https://arxiv.org/abs/2203.15556) was trained on a smaller 1.4 trillion token dataset. According to Chinchilla’s training guidelines, an optimal training for a 1 billion parameter model would be 20 billion tokens, so 3 trillion tokens is a significant leap! This seems to be a first for such a small model.

Other recent SLMs include Phi 1 and 1.5 with 1.3 billion parameters, Phi 2 with 2.7 billion parameters, and Gemini Nano with 1.8 and 3.2 billion parameters.
This is an interesting direction, as the focus generally has been on larger models. The niche of small models is under-explored, yet given the importance of inference, they are equally crucial. It has been observed that training a model well beyond the compute optimal guidelines of Chinchilla continues to yield fruitful results.
Technical Details
The architecture is classic, using a transformer decoder based on the Llama 2 (https://arxiv.org/abs/2307.09288) recipe with its tokenizer.

Data was collected from SlimPajama (a cleaned variant of RedPajama) and Starcoderdata, totaling 950 billion tokens, so the model was trained for approximately 3 epochs. The datasets were sampled in a 7:3 ratio.
Advanced techniques were employed, including RoPE encodings, RMSNorm pre-norm, SwiGLU, and grouped-query attention.
For scaling and acceleration, Fully Sharded Data Parallel (FSDP) from PyTorch, the latest Flash Attention 2, and fused SwiGLU from xFormers was replaced by the original implementation, saving memory (surprisingly, as I initially expected the fused implementation to be better). This allowed fitting the model into 40Gb of memory.
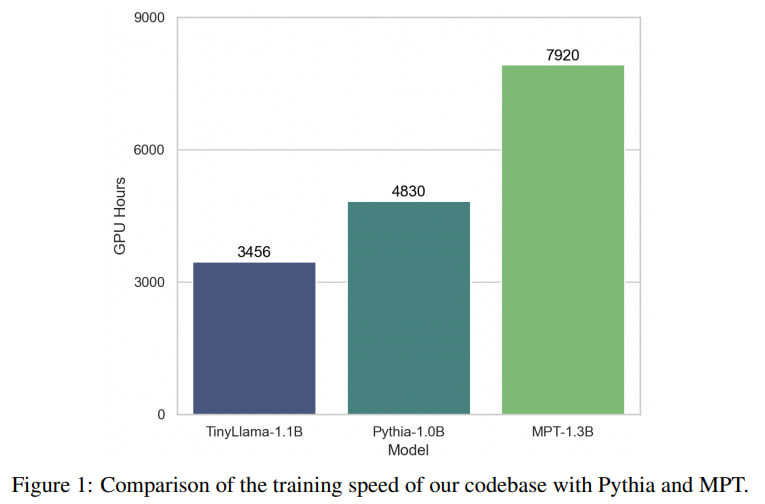
As a result, on an A100-40G GPU, they achieved a training throughput of 24,000 tokens per second. Training TinyLlama-1.1B on 300 billion tokens requires 3,456 A100 GPU hours, compared to 4,830 for Pythia and 7,920 hours for MPT’s.
Lit-GPT (https://github.com/Lightning-AI/lit-gpt) was used for training, which is based on nanoGPT. Training techniques included AdamW, cosine learning rate, warmup, and gradient clipping.
The training took 90 days on 16 A100-40G GPUs. Using AWS's p4d prices, this would cost approximately $140k.
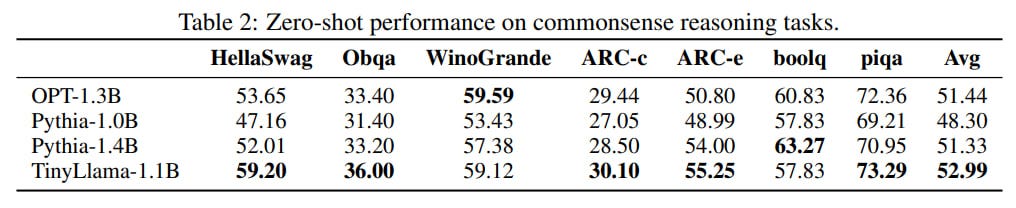
The results significantly outperform the baselines of OPT-1.3B, Pythia-1.0B, and Pythia-1.4B, though they are slightly behind on MMLU.
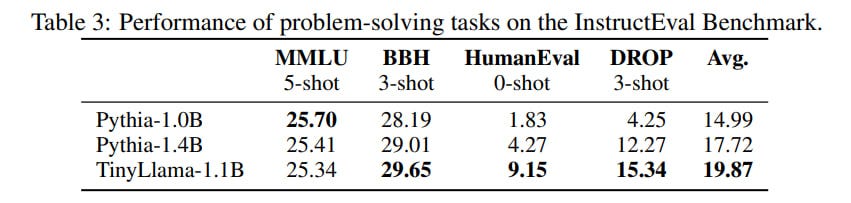
With an increased computational budget, performance continues to grow, though it becomes noisier for reasons not entirely clear.

This work exemplifies transparency. All training code, intermediate checkpoints, and detailed training processes are publicly available.
Respect!