As is typical now, continuing the "best" traditions of GPT-4 and PaLM 2, the article is scant on technical details.
The current version of Gemini 1.0 has been released in 4 sizes: the largest Ultra, and the medium Pro of unknown sizes, and two small distillates from larger models targeted for on-device deployment called Nano-1 (1.8B parameters) and Nano-2 (3.25B).
Architecture is still a traditional transformer decoder. Some architectural improvements and optimizations are claimed for stable training and better inference on TPU.
The context size is 32k, which is average by current standards (fresh GPT-4 has 128k, Claude recently increased it from 100k to 200k). But the devil, of course, is in the details. The larger context does not necessary mean the model uses it effectively. I hope we will see more models tested in this repo.
The model is multimodal.
It takes as input text mixed with audio, images, and videos of different resolutions. Video is encoded as a sequence of frames. Most likely, the model can work with relatively short videos that fit into 32k tokens. Sound is accepted in the form of features from the Universal Speech Model (USM) from a 16 kHz signal. Examples of multimodal prompting here.
The output can produce text and images (with discrete pictorial tokens).
Thus, its multimodality is a level higher than that of competitors like GPT-4V, where, besides text, only images are allowed only at the input.
Gemini is trained on TPUv4 and TPUv5e clusters. The scale is said to be larger than that of PaLM 2, and additional technical challenges were faced due to an increase in failures. Interestingly, for training the largest Ultra model, cubes of processors (4x4x4) were kept in each TPU Pod for hot swapping. It's claimed that optical switches can reconfigure cubes into any arbitrary 3D-torus topology in less than 10 seconds. Training was also distributed among different data centers. Google’s network latencies and bandwidths were sufficient to support the commonly used synchronous training paradigm. Inside super-pods they used model parallelism, and between them, data parallelism.
Together with Gemini, Google also announced TPUv5p, their newer and the most performant TPU. Compared to TPUv4, it has twice as many FLOPS and three times more HBM memory. It seems the time has come to update my old post about ASIC for Deep Learning.
At such a scale, new failure modes appear, here it was Silent Data Corruption (SDC), where data quietly corrupts and is not detected by hardware. This could happen not only in memory or during network transmission but also during CPU computations (which occasionally might calculate 1+1=3 as in wartime). It was estimated this should occur once every one to two weeks. A set of measures was implemented to achieve determinism of the entire architecture, which was said to be a necessary ingredient for stable training at such a scale.
JAX and Pathways were used for training.
Little is known about the dataset, but it is multimodal and multilingual. It includes the web, books, code, images, audio, and video.
SentencePiece was used for tokenization, giving a higher-quality vocabulary and improving overall quality when trained on a large part of the dataset.
The number of tokens for training was chosen according to the Chinchilla recipes. For smaller models, many more tokens were used to achieve higher quality at inference. During training, the proportion of datasets in the mix was changed, so domain-specific ones had more influence towards the end of training. The authors also confirm that data quality is critical.
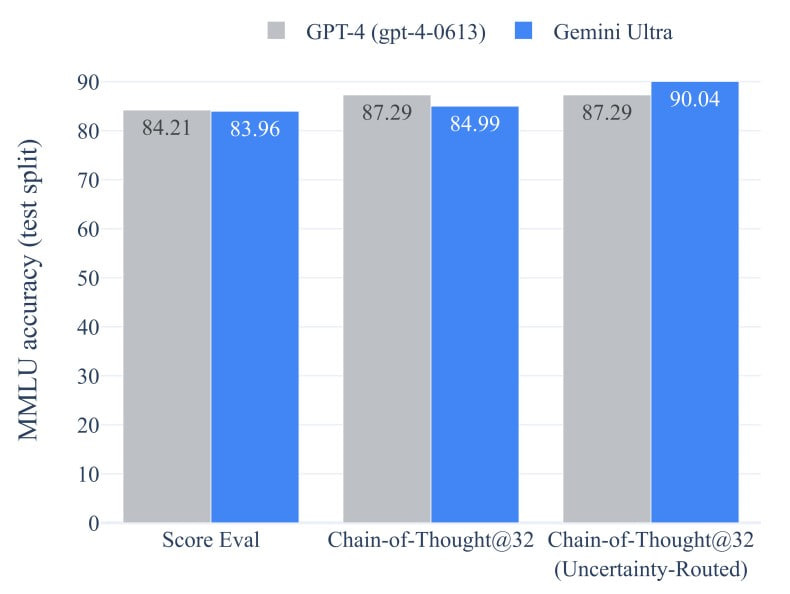
The largest version, Gemini Ultra, achieved SOTA on 30 out of 32 selected benchmarks and was the first to reach human-expert performance (89.8%) on MMLU (>90%).
However, maximum quality there is not achieved with vanilla model output but with what's called uncertainty-routed chain-of-thought. Here, the model generates k samples, say 8 or 32, and selects the majority vote if the model is confident above a certain threshold. Otherwise, it reverts to greedy sampling without CoT. This is similar to the upgraded CoT-SC. To achieve quality comparable to this CoT@32, you still need to write your code for orchestration. With GPT-4, if implemented, quality increases from 86.4% to 87.3%. However, on pure greedy decoding, Gemini performs worse than GPT-4:
Model scaling still works, delivering better quality along all the dimensions:
Nano on-device models also looks pretty good:
For benchmark figures, see the beautiful tables in the article. On multimodal benchmarks, a confident victory over GPT-4V is declared. In text, slightly less so.
The report contains many cherry-picked examples of solving different tasks. I recommend you to look! I love the following example the most. Previous models can potentially do such things only with external tools or plugins:
Also of interest, very high performance in speech recognition on various datasets, quality higher than USM and Whisper v2/v3. An interesting case with one universal model beating specialized ones. But, of course, the question is about size, whether they can be compared at all. Even in the case of Nano-1, it's better, and it's comparable in size.
Another interesting thing is that the largest model performs well on the Machine Translation (MT) task. Remembering, that the original PaLM 2 paper stated that the largest PaLM 2 model performed on MT better that the production Google Translate, the brand new Gemini Ultra should be even better. Can’t wait for testing it!
Google also prepared a beautiful demo of Gemini capabilities (though, remember, that it’s edited and in reality communication was not real-time):
Incidentally, the new AlphaCode 2 system was assembled on Gemini Pro (here’s the tech report on it).
It plays at the level of the 87th percentile, if compared on the same dataset as the first version (which was 46%).
Copilot had an interesting alternative in Google's Duet AI, but I haven't had time to compare them in practice. Surely the new code model will also be added to Duet, as it was with the text model added to Bard.
From a practical point of view, the most important question is when and what exactly will be available through the API. It seems that the Pro version will appear on Vertex AI on December 13. But it may turn out like with PaLM 2, that the largest Ultra model will still be unavailable for a long time. Google's PaLM 2 text-unicorn model only appeared on November 30, while since June, only the smaller and less interesting bison model was available.
Hopefully, this time Google will be a bit quicker.