
GPT-4V is coming!
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)

Authors: Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, Lijuan Wang
Paper: https://arxiv.org/abs/2309.17421
Microsoft has released a 166-page article on the analysis of GPT-4V's capabilities, conceptually similar to their widely recognized 155-page article on "Sparks of Artificial General Intelligence: Early experiments with GPT-4" (https://arxiv.org/abs/2303.12712).
GPT-4 with vision and other visual-language models
As many are aware, GPT-4 was originally trained in 2022 as an image-text model, capable of accepting images in addition to text. The original research even showcased several impressive demonstrations:

By March 2023, selected entities gained access to it, including Microsoft, which penned the article about Sparks of AGI. Notably, they even had access to earlier versions of the model. While it hasn’t been incorporated into the API yet, OpenAI recently announced image and sound support for ChatGPT and finally revealed the model card for GPT-4V (GPT-4 with vision).
It's reasonable to expect its introduction to the API soon. Moreover, it's not far-fetched to predict that 2024 will be the year of image-text (and possibly audio) models: GPT-4, Gemini (rumored to be under testing by select clients), open-source reimplementations of Flamingo of which at least a couple exist (OpenFlamingo, IDEFICS), Microsoft's Kosmos-1 and 2, and surely more to come. When these models can generate multimodal outputs like images + text, it will be revolutionary. This seems to be just around the corner.
GPT-4V model card
Looking into the GPT-4V model card, there's a focus on the model's safety and its broader deployment. Early testers also included Be My Eyes, which develops tools for visually impaired individuals. By September 2023, 16,000 users from this organization participated in beta testing, aiding in refining the model to reduce hallucinations and errors.
The model underwent extensive scrutiny concerning harmful content, privacy, cybersecurity, CAPTCHA solving capabilities, and potential multimodal exploits. GPT-4V refuses a larger percentage of risky queries compared to GPT-4 at its launch, and in tandem with an undisclosed Refusal System, it achieves a 100% refusal rate for certain internal exploit tests.

There was a comprehensive red teaming focusing on six areas: Scientific proficiency, Medical advice, Stereotyping and ungrounded inferences, Disinformation risks, Hateful Content, and Visual vulnerabilities. The paper provides more details on these issues and the results of their endeavors. It’s evident that a significant amount of work was put in, and the latest version of GPT-4V has improved as a result.
Preliminary Explorations with GPT-4V(ision)
The paper "The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)" (https://arxiv.org/abs/2309.17421) seems even more intriguing.

GPT-4V can handle multiple images, effortlessly alternating between pictures and text. This model introduces a range of prompting techniques.
1. For starters, it can respond to textual instructions. This includes Constrained prompting (e.g., asking for a JSON output for a driver's license photo) or Condition on good performance. The latter tunes the LLM for task success. Think of it as saying, "You're an expert in counting items in an image. Let’s tally the apples in the picture below, row by row, to ensure accuracy." – it reminds me of the other one NLP (a little wink to Grinder and Bandler)!
2. There's Visual Pointing. Users can input coordinates within an image or point to specific regions using arrows, rectangle, circle highlights, etc.

The researchers have named this interaction method Visual referring prompting.
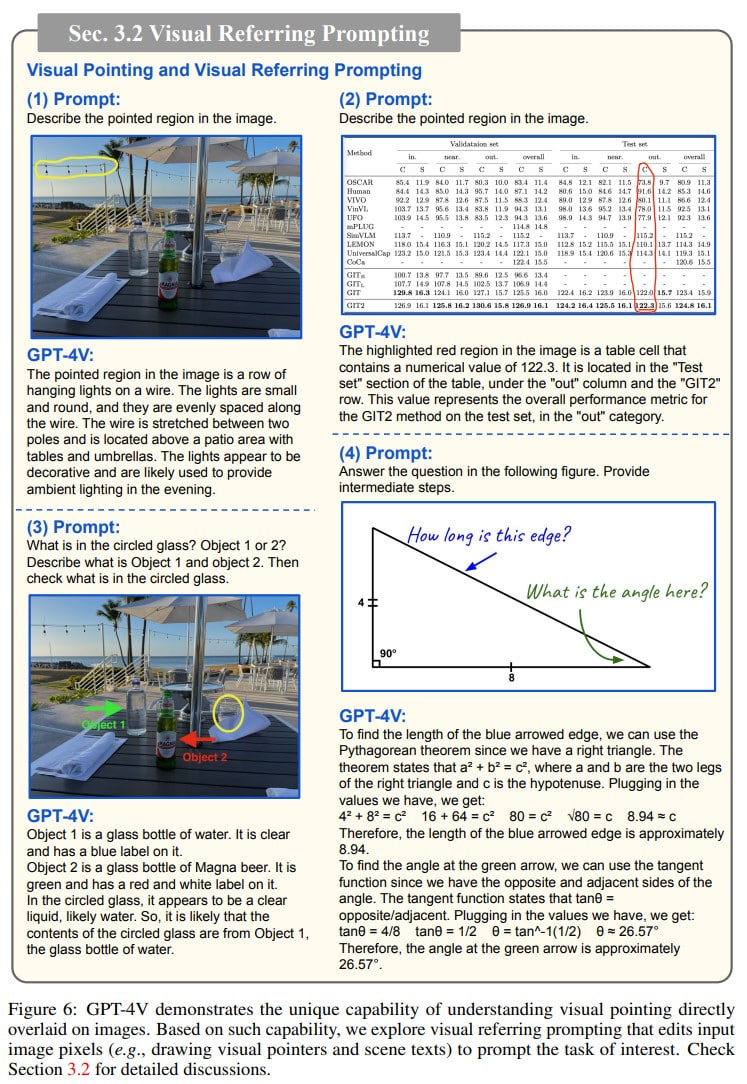
3. Combining text and visuals, the prompts can be hybrid.

4. The model’s flexibility allows for text-image few-shot learning with added visual examples.
The GPT-4V model has a diverse set of capabilities:
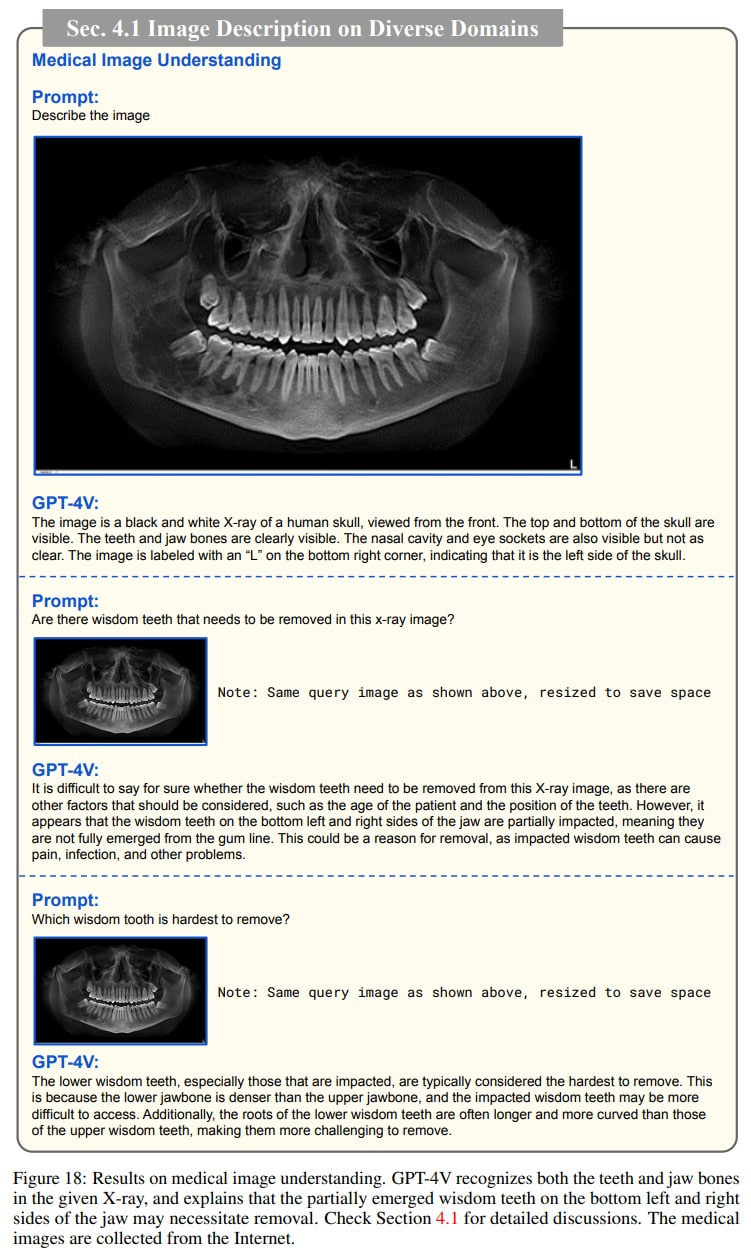
In the realm of picture-text pairs, GPT-4V can describe images, recognizing celebrities, places, food, logos, understanding medical images, various scenes, and even handling counterfactual examples. It's a bummer they didn't include the plane picture from the classic “Building Machines That Learn and Think Like People” (https://arxiv.org/abs/1604.00289). UPDATE: I did it.
The model excels in object localization and counting and is adept at Dense Captioning.

It boasts a degree of common sense and a genuine understanding of the world, recognizing jokes, memes, answering questions related to physics, geography, biology, and even drawing from visual cues.

It can decipher text, tables, graphs, and comprehend documents. Plus, it’s multilingual, effective for non-English prompts, generating text and recognizing content within images. Handy tools like LaTeX, markdown, and Python code generation are part of its arsenal.

The model demonstrates abilities in comprehending multiple languages in image and text modalities.




For the cinematic folks, GPT-4V works with videos, treating them as a sequence of frames.

Tests on Abstract Visual Reasoning and intellect? Check! It can gauge emotions from face photos or predict emotions an image might evoke, leading to Emotion Conditioned Output.


I highly recommend to look at the original paper, there are much more exciting examples!
There's a dedicated section on Emerging Applications. This is ideal if you're looking for inspiration. An exciting prospect is building an Embodied Agent based on GPT-4V. It would be interesting to take it a step further from Generative Agents. Or imagine crafting a frame-by-frame game like Doom using GPT-4V. With its capability to navigate GUIs, perhaps we won't have to wait for the ACT-1 transformer. It'll probably disrupt the Robotic Process Automation (RPA) niche sooner than expected.
The wrap-up has intriguing insights on LMM Powered Agents, discussing multimodal plugins, chains, self-reflection, self-consistency, and retrieval-augmented LMMs. Will Langchain adapt in time, or will another chain take its place? Personally, I'm quite fond of Microsoft's Semantic Kernel.

In summary, the future is here, but it's just not evenly distributed. I can see why giants like OpenAI and Anthropic are securing such massive funding rounds. Accessible cognitive automation will soon scale to unprecedented levels, and those harnessing these technologies will be the frontrunners. The entry price? It's hefty!