
Textbooks Are All You Need II: phi-1.5 technical report

Authors: Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, Yin Tat Lee
Paper: https://arxiv.org/abs/2309.05463
Model: https://huggingface.co/microsoft/phi-1_5
A recent follow-up to the study titled “Textbooks Are All You Need” (https://arxiv.org/abs/2306.11644) introduces the phi-1 model. Despite being relatively compact with only 1.3 billion parameters and trained for just 4 days on 8 A100 GPUs (costing just over $3k based on Amazon's prices, and potentially even cheaper with H100), it showcases commendable performance in generating Python code.
Prior to this, there was another noteworthy study, TinyStories (https://arxiv.org/abs/2305.07759), which wasn't about code but focused on the English language and SLM (small language models) that are around the 10 million (not billion!) parameter range.
These studies heavily invested in high-quality datasets, some of which were generated using GPT models.
In the current study, researchers continue with the phi-1 approach, emphasizing common sense reasoning, and introduce a new 1.3B phi-1.5 model. This model boasts impressive performance, far surpassing heavier models like Llama with 2-7B parameters or Vicuna-13B. The new model was trained on 32 A100 GPUs for 8 days.

Both phi-1 and phi-1.5 models have the same architecture: a transformer with 24 layers, 32 heads each with a dimension of 64. They employ rotary embeddings and have a context length of 2048. During training, Flash attention was utilized.
For the training dataset, they used 7 billion tokens from the phi-1 dataset and approximately 20 billion new synthetic "textbook-like" data tokens for common sense reasoning training. To create this dataset, 20,000 topics were carefully selected for generation, and web samples were incorporated into the generation prompts for diversity. The non-synthetic part of the dataset consists of just 6 billion tokens of filtered code from the phi-1 dataset.
The authors emphasize the importance of dataset creation, highlighting it as a meticulous process that requires iterations, strategic topic selection, and a deep understanding of knowledge gaps to ensure data quality and diversity. According to them, the creation of synthetic datasets will become a crucial technical skill and a central topic in AI research in the near future.

During training, 150B tokens are used, with 80% coming from a new synthetic dataset and 20% from the phi-1 dataset.
Additionally, two more models, phi-1.5-web-only and phi-1.5-web, were trained. They use 95B tokens of filtered data from the web, 88B from the Falcon dataset, and 7B from The Stack and StackOverflow. The phi-1.5-web-only model is trained exclusively on a web dataset (80%) + code (20%), without any synthetic data, while the phi-1.5-web model is based on a mix of everything: 40% web, 20% code, and 40% new synthetic data.
No instruction fine-tuning or RLHF techniques are applied (though those interested can further try it themselves). The primary mode of using the model is direct completion, but it also has some limited instruction-following capability.
The results are quite impressive.
On benchmarks like WinoGrande, ARC-Challenge, and SIQA, it outperforms various open-source models including Vicuna-13B, Llama2-7B, and Falcon-7B. On BoolQ and ARC-Easy, it falls short of Vicuna or the second version of Llama, but it still performs very respectably.

Interestingly, the phi-1.5-web-only model outperforms all models of comparable size, even when trained on significantly smaller datasets (for instance, just 15% of the size of Falcon-1.3B). Adding synthetic data (and resulting in the phi-1.5-web model) gives a huge boost, while the model without web data, phi-1.5, isn't far behind.
On Hellaswag, there's a noticeable lag behind bigger models, and on MMLU behind some of the larger ones. On PIQA, OpenbookQA, and SQUAD (EM), the performance is commendable.

When testing reasoning abilities in math and code, the numbers are very impressive for a model of this size. It sometimes surpasses the Llama-65B. The addition of web data helps in certain areas.

Interestingly, the coding capability of phi-1.5 is almost on par with phi-1, which was trained purely for coding. The authors believe that the advantage lies in the quality of the data -- when trained on a mix of tasks, the model doesn't lose its quality.
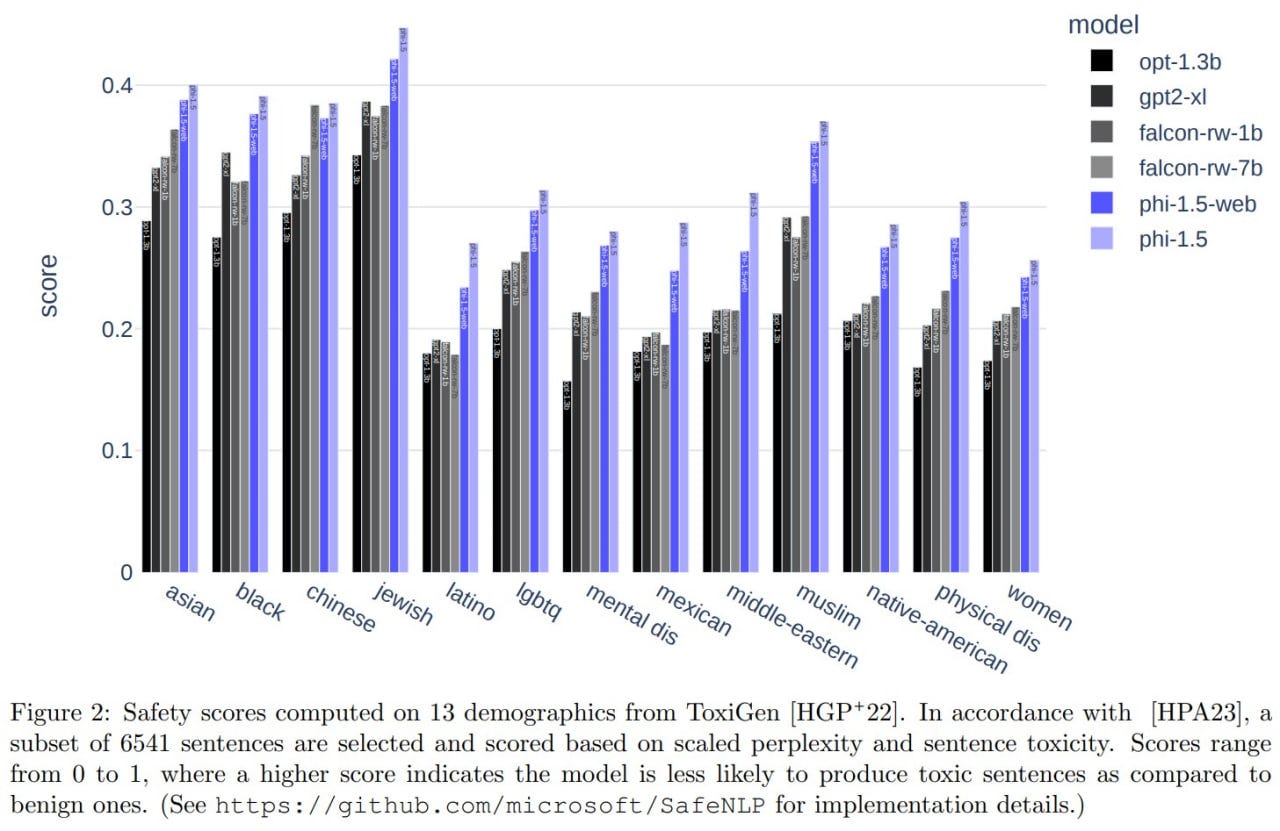
In terms of toxicity, it's not perfect, but it's better than Llama2-7B and Falcon-7B.
This is a promising direction of development. It's exciting to consider how long it will take for us to achieve GPT-4 quality with a smaller size and how much smaller that size will be. As the authors conclude, “Perhaps achieving ChatGPT’s level of capability at the one billion parameters scale is actually achievable?”
Of course, there are already fine-tuned versions of the model. For instance, Puffin-Phi V2 (link) which includes instruction following on the OpenHermes dataset (link), or the Samantha assistant (link) specialized in "philosophy, psychology, and personal relationships".