
s1: Simple test-time scaling
Can you surpass o1 with a 25$ budget?

Authors: Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, Tatsunori Hashimoto
Paper: https://arxiv.org/abs/2501.19393
Repo: https://github.com/simplescaling/s1
Continuing our discussion on Test-time compute: supervised fine-tuning (SFT) on a tiny dataset of 1k examples + simple strategies to make the model think longer — and voilà, we're beating o1-preview on MATH and AIME24!
While DeepSeek-R1 was undoubtedly an achievement in training a model with reasoning through RL, and in this sense, the open-source world has caught up to or even surpassed OpenAI's o1, that work wasn't aimed at demonstrating test-time scaling behavior. The current work combines both strong reasoning (but without RL) and scaling.
TL;DR
The recipe is simple and cost-effective.
Create a dataset s1K containing 1000 carefully selected question-answer pairs with reasoning traces, distilled from Gemini Thinking Experimental.
Perform SFT (PyTorch FSDP, 5 epochs, BF16) on an open model (Qwen2.5-32B-Instruct) using this dataset, taking 26 minutes on 16 H100 GPUs (estimated cost around $25). This produces the s1-32B model.
After training, control the amount of test-time compute through a straightforward budget forcing strategy, which involves: 1) if the model has generated too many tokens, forcefully end the process by adding an end-of-thinking token, and 2) if the model has generated too few tokens, prevent it from adding this end token, instead adding "Wait" to encourage more thinking.
Success! The graph demonstrates test-time scaling. We even get a model on the Pareto frontier for sample efficiency, better than o1-preview.

The model is fully open: weights, data, and code.
Now let's dive deeper into each step.
📔Dataset
The dataset was collected in two stages. First, they gathered 59K (59,029) questions from 16 sources.
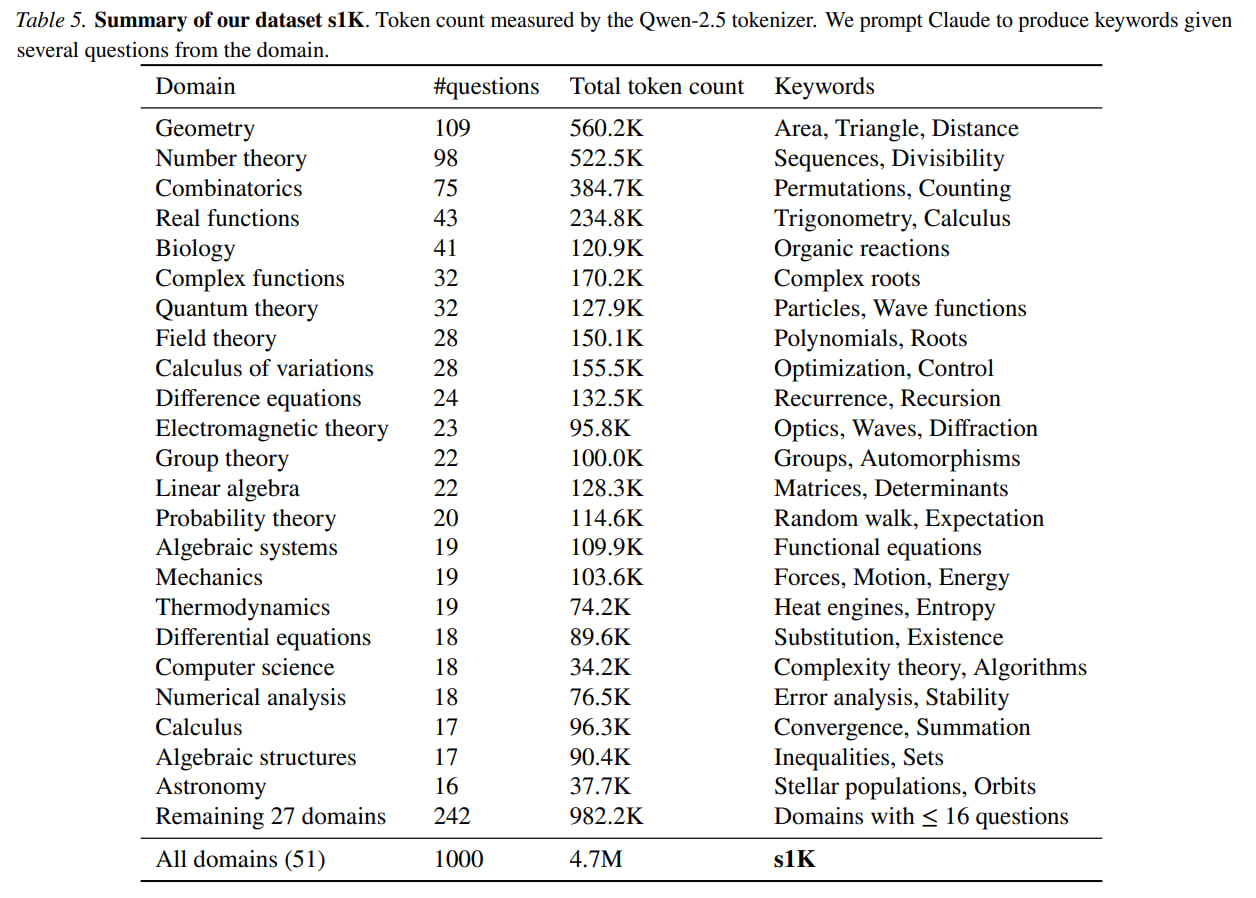
They took problems from existing datasets (NuminaMATH, AIME, OlympicArena, OmniMath, AGIEval) and created a couple of their own: s1-prob with probability theory questions (182 items) and s1-teasers with puzzles (23 items). It's quite unusual to hear about datasets with just 23 examples...
For each question, they generated a reasoning trace and solution using Google Gemini Flash Thinking API, resulting in 59K triplets of <question, reasoning, solution>. They cleaned this set against existing evaluation questions using 8-grams and deduplication.
They could have trained on these 59k examples immediately, but they wanted to find the minimal configuration, so they implemented three filtering stages:
Quality had to be high. They reviewed samples and removed problematic examples, such as those with poor formatting. This reduced the dataset to 51,581 examples, from which they selected 384 for the final 1k dataset.
Difficulty had to be appropriate and require reasoning. They removed examples that were too easy (solved by Qwen2.5-7B-Instruct or Qwen2.5-32B-Instruct). Claude 3.5 Sonnet evaluated correctness against references. Difficulty was assessed by reasoning chain length, assuming more complex questions require longer chains. This reduced the dataset to 24,496 examples.
Diversity: datasets needed to span different areas and tasks. Sonnet classified tasks using Mathematics Subject Classification (MSC), then they randomly selected one domain, sampled a task preferring longer reasoning chains, and repeated until reaching 1000 examples. This resulted in 50 different domains.
⚒️Test-time scaling
The authors distinguish between sequential methods (where results depend on previous reasoning) and parallel methods (like majority voting). They focused on sequential methods, believing they should scale better.
They proposed the aforementioned Budget forcing method, where minimum and maximum token counts can be set at test time. For forcing answers, they use an end-of-thinking token delimiter and "Final Answer:" string; for forcing reasoning, they suppress end-of-thinking token delimiter generation and use "Wait".

They compared against baselines: (I) Conditional length-control methods, specifying desired answer length in the prompt (including several methods about token length, step count, and general recommendations for longer or shorter generation), and (II) Rejection sampling, generating until meeting the budget.
🏁Evaluation
During evaluation, they considered not just accuracy but also controllability. On a fixed benchmark, they varied test-time compute and obtained a piecewise linear function showing the relationship between accuracy and reasoning length.
They measured several metrics:
Control — proportion of responses fitting within the budget (min/max token count).
Scaling — slope of the piecewise linear function, with positive slope being good and steeper being better.
Performance — maximum quality achieved on the benchmark.
Testing was conducted on AIME24, MATH500, and GPQA Diamond.

They compared against OpenAI's o1 series, DeepSeek R1 (original and 32B distilled), Qwen QwQ-32B-preview, Sky-T1-32B-Preview, Bespoke32B, and Google Gemini 2.0 Flash Thinking Experimental.

Overall, the model shows impressive results, with quality approaching Gemini. Performance increases with more reasoning steps. On AIME24, saturation occurs after six "Wait" prompts. Majority voting doesn't scale as well as forcing longer reasoning chains.

Ablation studies showed significant dataset dependency. Sacrificing any of the three principles results in lower quality. Training on the full 59K dataset yields slightly better quality, but at the cost of significantly more resources — 394 H100 GPU hours versus just 7.
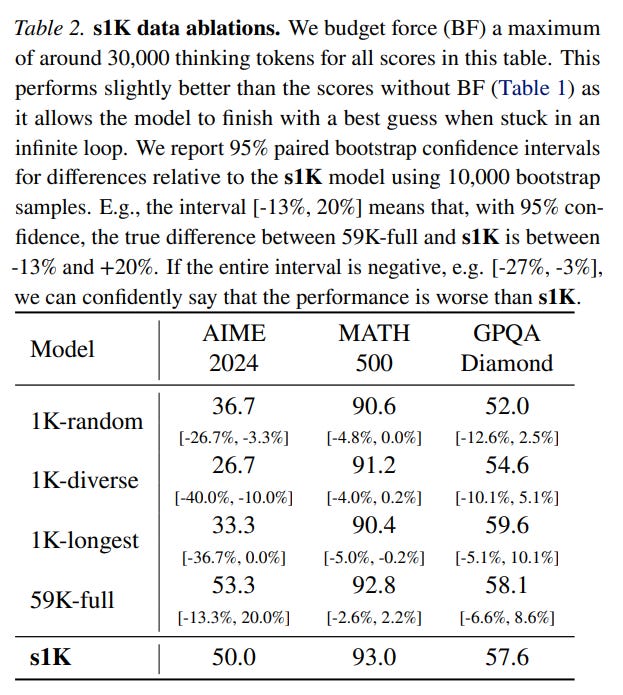
Among different length control methods, budget forcing achieves maximum quality on AIME24, excellent (100%) controllability, and good scaling (though class-conditional control shows slightly better scaling).

Attempting to simply sample answers of the desired length and discard those that don't fit (Rejection sampling) doesn't work — the scaling trend becomes negative, with the model producing better results with shorter answers (though this requires sampling many more times).

🗞️Update: s1.1
Interestingly, the team released an update (model s1.1), trained on the same 1k questions but using DeepSeek-R1 traces instead of Gemini. This yields even better quality.

The R1 traces show much more variety in length.

This is a fascinating result, achieved purely through SFT on a very small dataset. It would be interesting to see what combining this with subsequent RL might achieve.