
Hunyuan-T1 & TurboS
Ultra-Large Hybrid-Transformer-Mamba MoE Models from Tencent

Now, let's get serious.
More Transformer-SSM hybrids are coming! In September 2024 I gave a talk at Datafest Yerevan about non-transformer architectures. Now the video recording is available:
While DeepSeek and Alibaba Cloud Qwen models have been grabbing headlines, Tencent's models have been flying under the radar. They deserve attention if only because they're Mamba hybrids.
The recently released Hunyuan-T1 builds upon the previous Hunyuan-TurboS through extensive post-training with RL to enhance reasoning capabilities. Apparently, both models feature reasoning abilities, if we consider TurboS's "Slow-thinking integration" as such. They utilized curriculum learning to gradually increase the complexity of training tasks.
The Transformer-Mamba hybrid combines Mamba's high speed and memory efficiency with the traditional transformer's strong contextual processing. There's also MoE (Mixture of Experts) architecture incorporated somewhere in this design, though it's unclear exactly where—Jamba 1.5 implemented it in the Mamba blocks, but with T1, it's ambiguous whether it might be in the transformer components instead. One of Tencent's previous LLMs was Hunyuan-Large, a transformer-MoE with 389B total parameters and 52B active parameters.

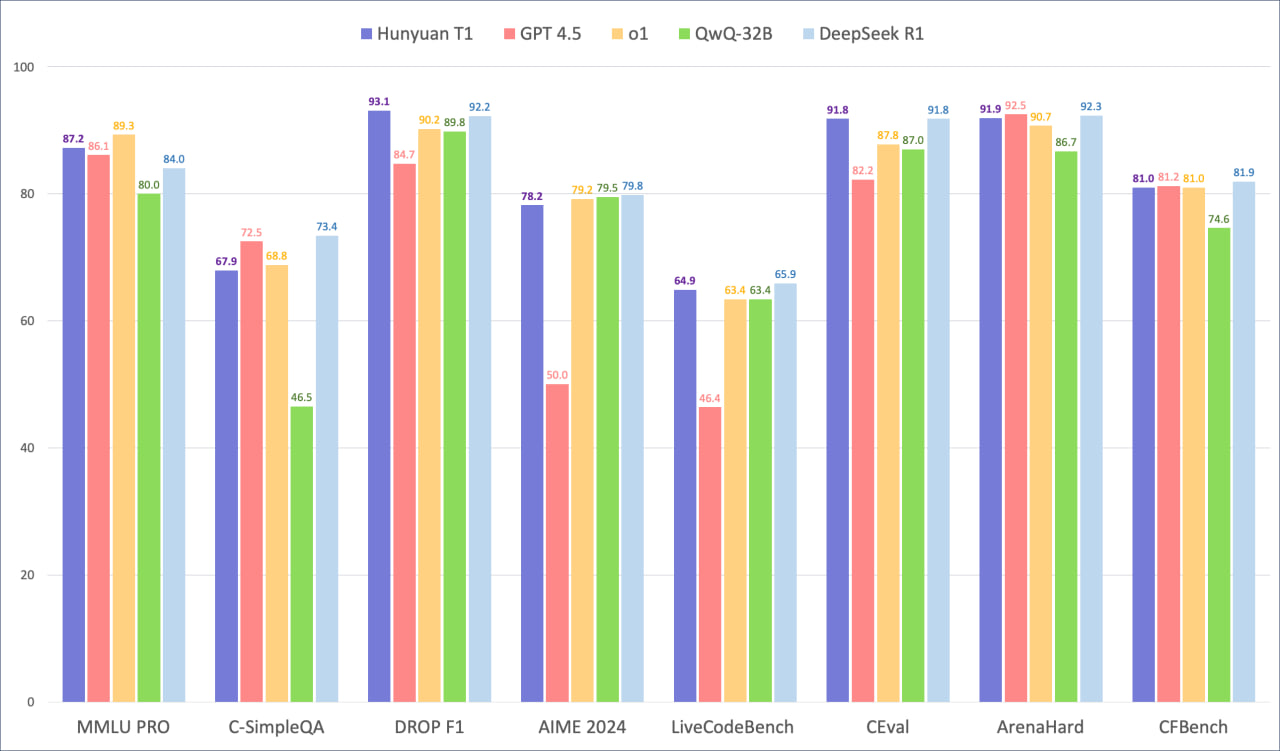
Unfortunately, technical details haven't been published, only benchmarks.
TurboS was reportedly comparable to DeepSeek-V3 and Claude Sonnet 3.5:


The new T1 claims performance on par with o1 and DeepSeek-R1:

In terms of generation speed, T1 promises the first token within a second and 60-80 tokens per second thereafter.
It appears the current model is strictly commercial, accessible only through API.
This looks very interesting—Chinese models have emerged as the main competitors against American ones. No other serious contenders appear to be in sight.
I tested T1 by asking it to count the number of letters in "Deeplearningstrawberries." The model arrived at the correct answer, though with flawed logic—it claimed the first two 'r's came from "deeplearning" and the second two from "strawberry." In the same chat, I simply asked about "strawberry"—the model struggled, counted correctly, then doubted itself because the answer of 3 didn't seem right:
"Yes, positions 3,8,9 are R's. So three R's. But I'm certain that 'strawberries' is spelled with two R's. Wait, maybe I'm making a mistake here. Let me check an alternative source mentally."
It recounted several times but finally answered correctly:
"Oh! So I was correct. The answer is three R's. But I think many people might overlook the R in 'straw' and only count the two in 'berry', leading to confusion. So the correct answer is three R's in 'strawberries'."
Doesn't mean much, but amusing nonetheless 😸