

I have to talk about DeepSeek. These folks have absolutely crushed it — few have managed to disrupt the entire field like this. Well, there was OpenAI with ChatGPT, then Meta with open-source Llama, and now DeepSeek.

DeepSeek has managed to train high-quality models at costs an order of magnitude lower than their competitors.
DeepSeek-V3
First, there's DeepSeek-V3 (https://github.com/deepseek-ai/DeepSeek-V3), which includes two models: DeepSeek-V3-Base and the chat version DeepSeek-V3. Both are MoE models with 671B total parameters and 37B active parameters. These aren't models for the average user — you need a serious multi-GPU setup, something like 8 H200s (though there are compressed versions available from various contributors).

Quality-wise, they're somewhere around the level of GPT-4 0513 and Claude-3.5-Sonnet-1022, and above LLaMA-3.1 405B.

There are various estimates of how much it cost to train Llama 3.1 405B. The Llama paper itself (https://arxiv.org/abs/2407.21783) mentions using up to 16,384 H100s and refers to 54 days of pre-training (though there were other training phases too). One of the more conservative estimates suggests it should have cost around $60M.
For DeepSeek-V3, we have more specific information (if it’s true). They used H800s, a China-export restricted variant of H100, and they explicitly state that full training required 2.788M H800 GPU-hours, which translates to $5.576M at an H800 rental price of $2 per hour.
That's like an order of magnitude cheaper. The difference is probably even bigger when compared to OpenAI.

It's similar to how India sent spacecraft to Mars and the Moon cheaper than Hollywood makes movies about space: the Martian Mangalyaan for $74M and lunar Chandrayaan-3 for $75M versus the movie "Gravity" at $100M.
DeepSeek-R1
Second, there's DeepSeek-R1 (https://github.com/deepseek-ai/DeepSeek-R1), models with reasoning capabilities similar to OpenAI o1 or Google Gemini Thinking. The family includes two models: DeepSeek-R1-Zero and DeepSeek-R1, both built on DeepSeek-V3-Base and of similar large size.
DeepSeek-R1-Zero (similar to AlphaZero) was trained purely with RL (Group Relative Policy Optimization, GRPO — a PPO variant from another paper of DeepSeek, https://arxiv.org/abs/2402.03300), without SFT. I think this is a very significant result — just as with Go, where it turned out you could do without human games, the same is gradually proving true here.
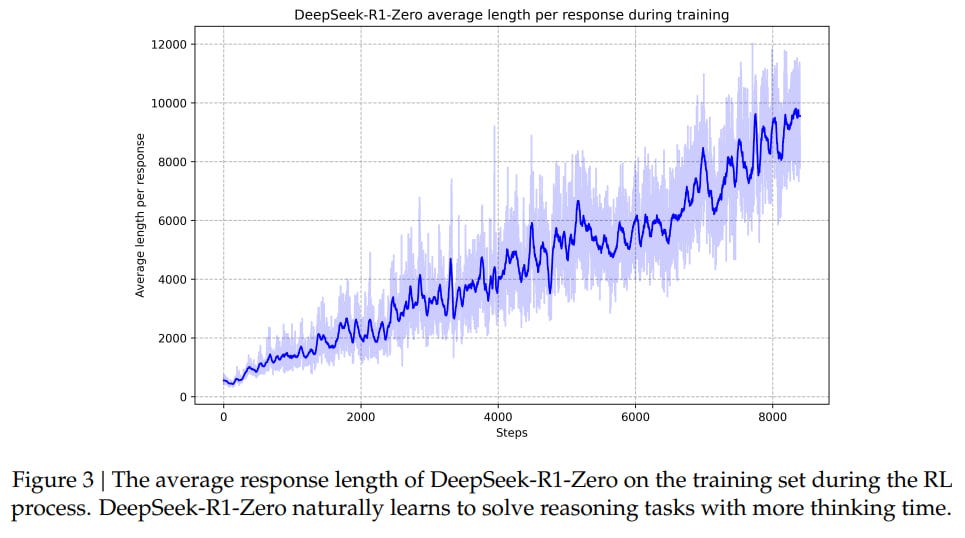
Interestingly, during training, the model had an "aha moment" where in a chain of reasoning it output "Wait, wait. Wait. That's an aha moment I can flag here." and revised its initial approach to solving the problem.

Zero is good, but sometimes gets stuck in repetitions, mixes languages, and isn't very readable. DeepSeek-R1 was trained on a small number (thousands) of CoT examples before RL, which they call Cold start data, to provide a better starting point for RL. Then the same Reasoning-oriented RL as Zero. Then SFT on reasoning (600k) and non-reasoning (200k) data. And then an additional RL phase. This model is comparable to OpenAI-o1-1217.

Things that didn't lead to success: Process Reward Model (PRM) and Monte Carlo Tree Search (MCTS).

They've also released many dense distillates (1.5B, 7B, 8B, 14B, 32B, 70B) from R1 based on Qwen and Llama. These are comparable to OpenAI-o1-mini.

Jay Alammar, who created excellent visual explanations for transformers, a hundred times better than the original transformer paper, just released an illustrated guide to DeepSeek-R1. Highly recommended!

HuggingFace has taken on Open R1 (https://github.com/huggingface/open-r1), a fully open reproduction of DeepSeek R1. For once, it's not Chinese researchers catching up to Western ones, but the other way around!
There's another replication from Hong Kong, by NLP Group @ HKUST (https://github.com/hkust-nlp/simpleRL-reason).
Janus-Pro
But DeepSeek wasn't satisfied with just that, and today they also released Janus-Pro, an evolution of the previous Janus (https://github.com/deepseek-ai/Janus) with improved training, data, and larger size. This is a multimodal model with 1B and 7B parameters that can take text and images as input and output both text and images.

In generation tasks, they apparently beat Dalle-3, SDXL, and SD3-Medium.

DeepSeek-VL2
And by the way, they also have DeepSeek-VL2 (https://github.com/deepseek-ai/DeepSeek-VL2), a llava-style VLM with MoE. It takes text and images as input and outputs text.
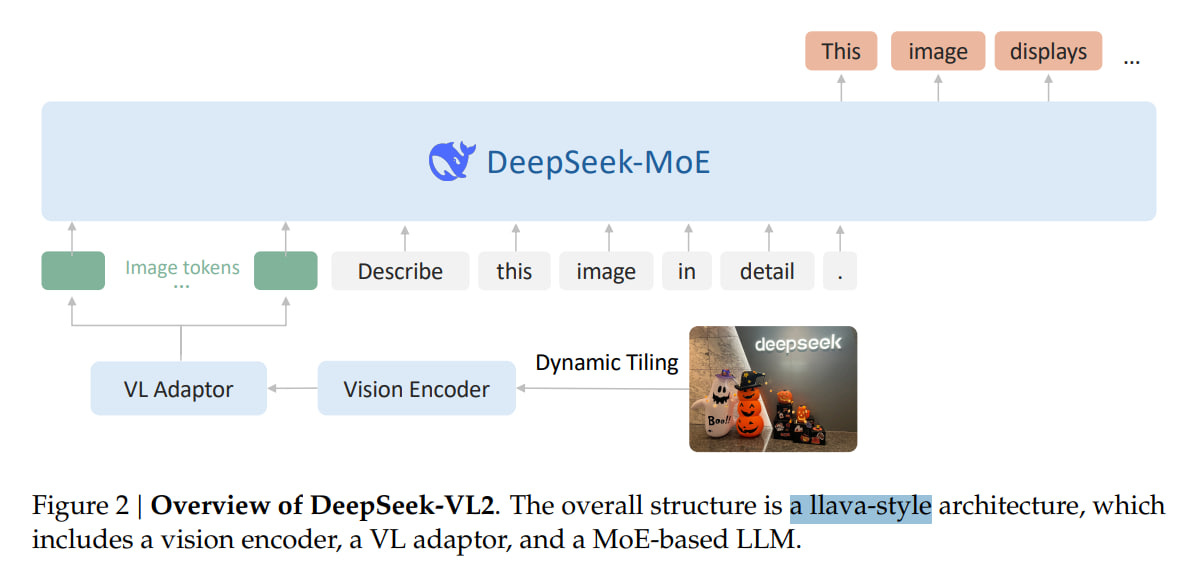
The family includes three models: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2 with 1.0B, 2.8B, and 4.5B active parameters respectively.

Video generation will probably be next 🙂
Everything is under the open MIT license.
The excitement today is like Pokemon Go in its time. NVIDIA and co. stock prices quickly dropped, though I don't think this radically changes anything — they'll recover.

I don't know what's happening inside the teams at OpenAI, Gemini/Gemma, Llama, but it's probably not the easiest time. The Economist published articles about Chinese AI (here and here), and of course it's interesting to see how this will all reflect on the Project Stargate.
We're living in interesting times.
Good summary! Needs to mention that stocks image is not actual one and confusing since it has BABA (Alibaba) red too which is def not the case today
The whole AHA moment is pretty surreal for me. I do think this starts a moment of reflection in the way that those teams should be thinking <<Are overengineering stuff?>>
Also, looks like we can squeeze both in terms of data and computing.