
Generative Agents 2.0
Simulating 1,052 real people

Authors: Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, Michael S. Bernstein
Paper: https://arxiv.org/abs/2411.10109
Post: https://hai.stanford.edu/news/ai-agents-simulate-1052-individuals-personalities-impressive-accuracy
A fascinating study by Stanford researchers shows how AI can accurately simulate human personalities.
Last year, we missed discussing an intriguing paper from Stanford that builds upon their previous work on Generative Agents.
Generative Agents: Interactive Simulacra of Human Behavior

Authors: Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein
Now, the researchers simulated 1,052 real people and achieved an impressive 85% accuracy in replicating their responses and actions in experiments conducted two weeks later. They also developed a helpful AI interviewer agent.
Here's what they did.

🎤 The Interview Process
The researchers conducted in-depth interviews using a combination of predetermined questions and adaptive follow-ups based on respondents' answers.
They recruited 1,052 participants through stratified sampling to create a representative sample of the US population, accounting for age, gender, race, region, education, and political ideology. Each participant completed a voice interview averaging 6,491 words (standard deviation 2,541). Additionally, participants completed two questionnaires: General Social Survey (GSS), and 44-item Big Five Inventory (BFI-44), participated in five economic games and five behavioral experiments.

The interviews would later serve to prime the agents, while the surveys and experiments would evaluate the agents' accuracy. A self-consistency interview was conducted two weeks after the initial assessment.
Initially, they recruited 1,300 people through Bovitz (aiming for 1,000 participants to ensure sufficient statistical power for the behavioral experiments). Participants were compensated with $60 for the initial survey, $30 for the self-consistency check after two weeks, and potential bonuses of $0-10 based on their performance in economic games. With some attrition before the second phase, they ended up with 1,052 participants.
The team developed a custom platform where participants could register, create an avatar, provide consent, and complete interviews, surveys, and experiments in a specified order and timeframe.

To scale the interviews, they employed an AI interviewer following a semi-structured protocol. They chose interviews over surveys to capture richer information with valuable nuances. The protocol was based on the American Voices Project methodology, though shortened from three hours to two hours while maintaining core topics ranging from life history to views on current social issues.

The AI interviewer dynamically generated follow-up questions based on participants' responses. Built on the original Generative Agent architecture, it processed recent participant responses and the interview script to either generate follow-up questions or move to the next scripted question. Questions were organized in blocks with specified time allocations. The agent would ask the first question of each block verbatim, then dynamically decide on follow-ups based on remaining time and participant responses.

To handle the challenge of context degradation in current language models, they implemented a reflection module that summarizes conversations and records insights about respondents. For example, if a respondent mentioned their birthplace's natural environment, the agent might inquire about outdoor activities and record something like:
{
"place of birth": "New Hampshire",
"outdoorsy vs. indoorsy": "outdoorsy with potentially a lot of time spent outdoors"
}
These notes would later replace the full interview transcript when passing to the AI interviewer, with only the latest 5,000 characters of transcription retained.
The interviewer was implemented as a web application using OpenAI's TTS and Whisper for voice communication, though some details about their use of the Audio model remain unclear (there is the gpt-4o-audio model, but if they used it, no need to use Whisper).
🤖The Simulacrum Architecture
Like its predecessor, the agent-simulacrum has a text-based "memory stream" and a reflection module that synthesizes memory elements into reflections.
The researchers found that simply prompting an LLM with interview transcripts to predict respondent reactions using single chain-of-thought (CoT) reasoning might miss latent information not explicitly stated in the text. To extract this hidden information, they introduced an innovative "expert reflection" module that acts as a domain expert.

Specifically, they generate four sets of reflections from different expert perspectives:
Psychologist
Behavioral economist
Political scientist
Demographer
Using GPT-4o, they prompt each expert perspective to generate up to 20 observations or reflections per respondent. These reflections are generated once and stored in the agent's memory.
When the simulacrum needs to predict a respondent's answer, it follows a two-step process:
First, it classifies (through prompting) which of the four experts would be best suited to answer
Then it pulls that expert's reflections and combines them with the interview transcript to generate the answer (using GPT-4o)
All the questions are multiple-choice or numerical questions, the model is prompted to use chain-of-thought reasoning. (It would be interesting to see how newer reasoning models like o1/o3/R1 might change these results.)
For behavioral experiments requiring context maintenance, the agent's stimuli and responses are appended as text to the transcript and reflections.
🏋️♀️ The Experiment
The researchers tested their agents with the same battery of tests and experiments (GSS, BFI-44, economic games, and behavioral experiments) and compared them with the original respondents' answers.
They used two baselines for comparison:
An agent with only demographic attributes (extracted from GSS responses)
A text paragraph summarizing the specific person (respondents wrote brief self-descriptions)
For GSS, BFI-44, and the five games, they calculated normalized accuracy as the ratio of agent prediction accuracy to internal consistency (how well humans replicated their own answers after two weeks). They used standard accuracy metrics for categorical tasks and mean absolute error (MAE) for numerical ones.

For GSS, the mean normalized accuracy was 0.85 (std = 0.11), calculated from 68.85% agent accuracy divided by 81.25% human self-consistency.
The interview-based agent significantly outperformed baselines on GSS and BFI. No significant difference was found in economic games.
They also created a composite agent with the compilation of all the answers to GSS, BFI, and games, but without the interview. The interview-based approach remained superior even when randomly removing up to 80% of the transcript or using only a brief bullet-point summary.
In the five behavioral experiments (including studies like the "allocator's illusion"), both humans and agents replicated 4 out of 5 experimental results, suggesting that agents can serve as reliable proxies for behavioral research.
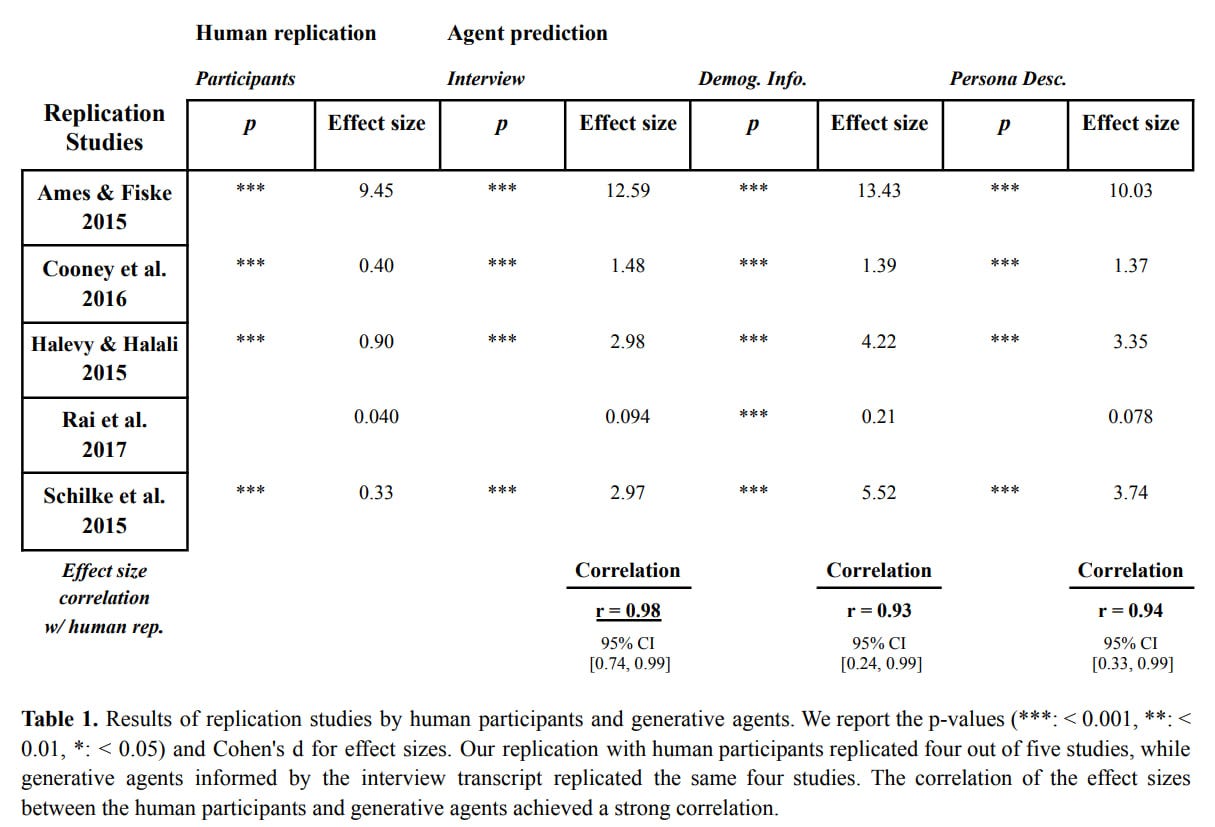
The authors tested if there are biases related to gender, race or ideology, quantifying bias using the Demographic Parity Difference (DPD), which measures the difference in performance between the best performing and worst-performing groups. The interview-based agents were better than demographic-based or persona-based ones.

This research opens exciting possibilities for social science research and policy testing. These virtual agents could be used to:
Simulate responses to policy changes
Predict survey and voting outcomes
Create digital representations of decision-making bodies
The accuracy of these simulations suggests we're moving closer to more sophisticated forms of digital personality replication. However, this also raises important questions about identity protection and the potential for personality replication misuse.
For a long time I wanted to create a digital parliament, replicating some real one. I’m sure it would be good enough. Though, still have more important things to do. Maybe these authors are already doing something like Generative Agents 3.0, or Political Agents 1.0. I wouldn’t be surprised.
Digital immortality seems just around the corner. And text-based immortality is even closer. The identity personality theft is as well.