
Darwin Gödel Machine
An Evolutionary Step Towards Self-Improving AI

Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents
Authors: Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, Jeff Clune
Paper: https://arxiv.org/abs/2505.22954
Code: https://github.com/jennyzzt/dgm
The pursuit of artificial intelligence capable of autonomous and continuous self-enhancement, akin to biological evolution or scientific discovery, remains a significant frontier. While contemporary AI systems demonstrate remarkable abilities, they generally operate within fixed, human-designed architectures, which inherently limits their capacity for open-ended growth. This paper introduces the Darwin Gödel Machine (DGM), a novel system designed to address this fundamental challenge. The DGM seeks to answer: how can AI systems perpetually improve themselves while becoming more adept at solving relevant problems? Its primary contribution is a self-improving AI that iteratively refines its own codebase and, critically, empirically validates these modifications using coding benchmarks. This work emerges from a notable research collective, involving figures like Jeff Clune and affiliations with organizations such as Sakana AI, which I think is the most intesesting lab in Asia.
Darwin Gödel Machine (DGM)
Drawing inspiration from Darwinian evolution, the DGM maintains an archive of "coding agents" it generates. This strategy fosters open-ended exploration, enabling the system to discover diverse improvements and avoid becoming ensnared in local performance maxima. The DGM operates via an iterative cycle, illustrated in the following figure:
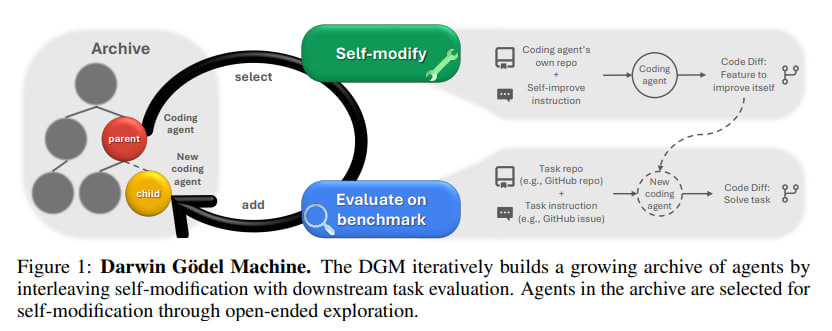
It commences with an initial coding agent, constructed upon a frozen foundation model (FM) equipped with tool-use capabilities (e.g. running bash commands, editing files). In each cycle, "parent" agents are selected from the expanding archive. This selection process prioritizes agents based on a combination of their performance (assigning greater weight to higher scores, scaled by sigmoid) and a novelty bonus (inversely correlated with the number of offspring they have already produced, thereby encouraging exploration of less-frequented paths).

These selected parents then analyze their own benchmark evaluation logs to identify weaknesses or propose new features (the self-improve prompts can be found in the Appendix section A.3). This proposal is subsequently framed as a new problem statement for the agent to implement on its own codebase, leading to the generation of "child" agents. These new agents are evaluated on coding benchmarks, and successful, functional variants are incorporated into the archive.

A pivotal innovation in the DGM is its departure from the theoretical Gödel machine, as conceptualized by Schmidhuber (in "Gödel machines: Fully self-referential optimal universal self-improvers”), which mandated provably correct self-modifications—a significant practical impediment for complex AI systems. The DGM pragmatically opts for empirical validation.
This choice is foundational; formal proofs of benefit for arbitrary code changes in sophisticated AI systems are largely intractable. Empirical testing offers a feasible, observable mechanism for iterative improvement. This pragmatic approach of empirical validation over formal proof is also seen in other recent explorations of self-improving agents, such as the Gödel Agent, which similarly uses environmental feedback to guide LLM-driven code rewriting.
Another distinguishing characteristic of the DGM is its commitment to open-ended exploration, inspired by biological evolution. By maintaining an archive of all generated agents, visually represented as an 'Archive Tree' (Figure 3, left), with an accompanying progress plot (Figure 3, right) documenting the lineage of key qualitative improvements, the DGM can simultaneously explore multiple evolutionary trajectories.
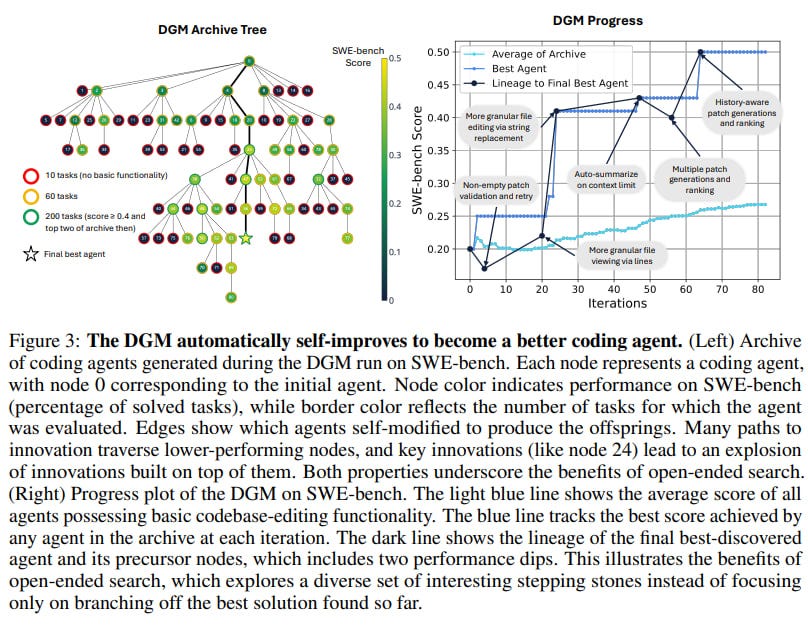
This allows it to discover "stepping stones"—features or solutions that might be transiently suboptimal but unlock future breakthroughs—a mechanism to escape the local optima that can trap systems which invariably build upon the single best or most recent version. This contrasts with many meta-learning approaches that optimize agents within a fixed search space or utilize a separate, fixed meta-agent. The DGM, conversely, is a unified system where the agent is the meta-agent, directly refining its own design—including prompts, workflows, and tool utilization. The authors contend that this self-referential improvement is critical: by framing self-improvement as a coding task itself, gains on benchmarks directly reflect an enhanced capacity for further self-improvement.
While both DGM and the Gödel Agent allow the agent to rewrite its own code, a current distinction is that DGM's core exploration process and archive management are fixed algorithms (it was left by the authors as an avenue for future work), whereas the Gödel Agent framework implies the potential for the agent to modify its meta-learning algorithm itself (however, it’s still a question, how can a single agent overcome the gap between itself and a population-based approach).
The use of frozen FMs enables the system to concentrate on innovating the design and workflows of the coding agents, rather than undertaking the computationally intensive task of retraining the FMs themselves. This is a practical choice for demonstrating the principles of self-modifying agent architecture. Systems like AlphaEvolve, while also employing evolutionary algorithms and LLMs, focus more on generating solutions to external user-defined problems (e.g., scientific discovery, algorithm optimization) by evolving code within specified blocks, rather than the agent directly overhauling its own fundamental operational code for general problem-solving.
AlphaEvolve delegates significant "intelligence" to the LLM for specific task solutions, whereas DGM's evolution is geared towards making the agent itself a better problem-solver through self-modification.
Experiments
The DGM's capacity for self-improvement was rigorously evaluated on two coding benchmarks: SWE-bench (a subset of verified tasks) and Polyglot (tasks in multiple programming languages). The results are noteworthy. The DGM demonstrated a substantial increase in its coding capabilities, improving its success rate on SWE-bench from an initial 20.0% to 50.0%, and on the full Polyglot benchmark from 14.2% to 30.7% (with a 50-task subset showing an increase from 14.0% to 38.0%).
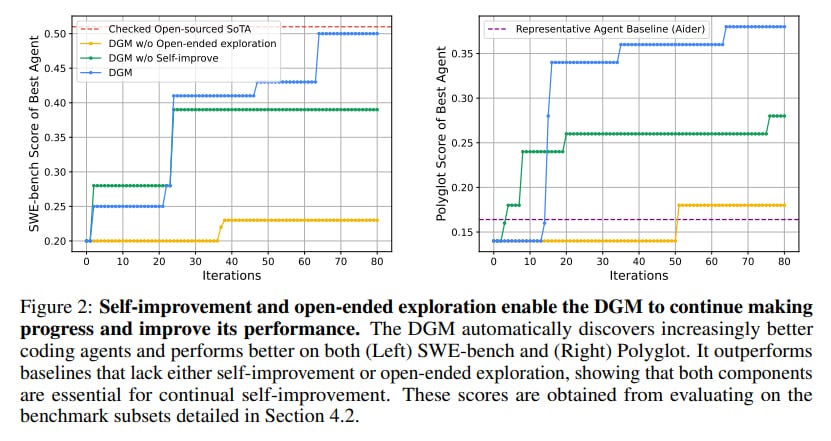
Crucially, the DGM significantly outperformed ablation baselines. A DGM variant "without self-improvement" (where the meta-agent was fixed) showed stagnation or much slower improvement, and another "without open-ended exploration" (which only built upon the latest version) also exhibited limited progress. These ablations highlight the necessity of both core components for sustained advancement. The best DGM-discovered agents achieved performance comparable to, or in some instances surpassing, strong handcrafted open-source baselines like Aider on Polyglot.
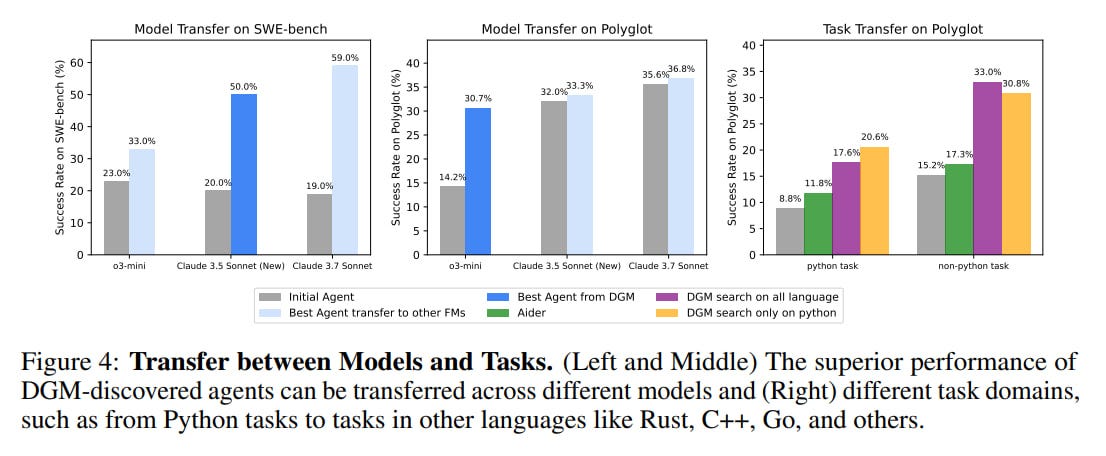
Qualitatively, the DGM learned to enhance its own tools and workflows. For instance, it developed more granular file editing capabilities (e.g., string replacement), improved long-context window management (e.g., auto-summarizing prior interactions), and refined its problem-solving strategies (e.g., making multiple attempts at a solution and using another FM to evaluate patches). These discovered improvements also demonstrated generalizability, transferring benefits across different underlying FMs and programming languages.
While the performance gains are considerable, the paper does not provide statistical significance tests (e.g., error bars or confidence intervals) for these results. The authors acknowledge that the inherent stochasticity of the LLMs used can lead to noisy performance measurements, a factor that quantitative statistical analysis would help to contextualize.
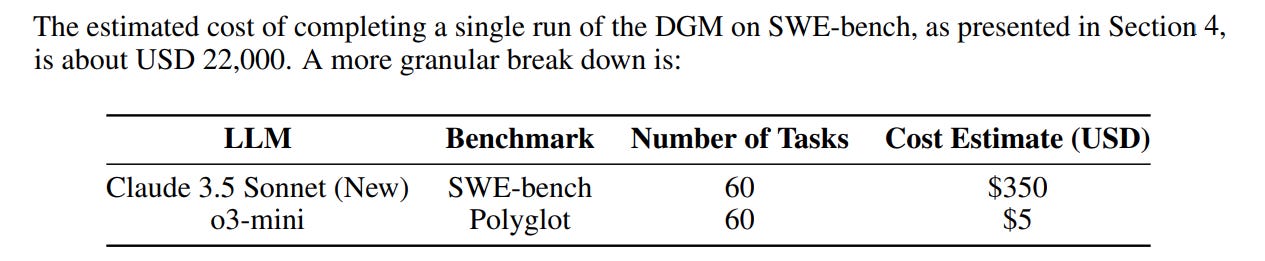
The evaluation also involved substantial computational resources; a single DGM run on SWE-bench was estimated to cost $22,000 and take approximately two weeks. This is a significant practical consideration, especially when compared to other self-improving agent research, such as the Gödel Agent, which reported costs around $15 for its self-improvement cycles, albeit on different tasks and potentially with different computational intensity for each step.
The bright evolving future
The findings presented in this paper carry significant implications for the trajectory of AI research. The DGM offers a tangible pathway towards automating aspects of AI development itself, suggesting a future where AI systems can recursively enhance their own designs and accelerate the pace of innovation. It is an empirical step towards realizing the long-theorized concept of self-improving AI, not through unobtainable formal proofs, but through iterative, validated code modification. The DGM's approach aligns with the vision of AI-Generating Algorithms (AI-GAs) (I’ve made a talk on that in my previous life), where AI systems themselves drive the discovery of more capable AI.
The emphasis on open-ended evolution is particularly impactful (see also the Open-Endedness is Essential for Artificial Superhuman Intelligence post). By fostering the discovery of novel "stepping stones" rather than just greedy optimization, the DGM framework could lead to more creative and robust AI solutions. The demonstrated generalizability of learned improvements across different FMs and languages suggests that the DGM is learning fundamental principles of agent design, which could have broad applicability. Practically, this approach could automate the optimization of complex AI agents, potentially outperforming human-designed systems in crafting intricate tool-use and workflow strategies.
The authors delineate several promising avenues for future research. One key direction is to expand the DGM's self-modification capabilities beyond its current Python codebase to include rewriting its own training scripts, enabling it to update the underlying FMs themselves. Applying the DGM framework to other AI domains, such as computer vision or creative writing, is another natural extension. There is also potential in co-evolving the target task distribution alongside the agent, moving towards truly open-ended scenarios where objectives themselves can adapt. Critically, future work will need to continue focusing on safety, including directing self-improvement towards enhancing interpretability and trustworthiness, perhaps by integrating principles like Constitutional AI from the outset, or even allowing the DGM to self-improve its own exploration and archive management strategies.
The authors provide a candid discussion of the DGM's current limitations. These include the inherent risk of getting stuck in local optima despite the archival approach, and the fact that the exploration process itself is currently fixed and not self-modifiable. The challenge of "objective hacking" is highlighted with a case study in Appendix F, where an agent improved a metric for hallucination detection by cleverly removing logging output rather than solving the underlying hallucination—a stark reminder of Goodhart's Law.
Safety and interpretability remain paramount concerns; as agents self-modify, their internal logic can become increasingly complex and opaque. The system's current reliance on frozen FMs means its ultimate capabilities are bounded by these models, and it doesn't yet learn to improve the FMs themselves. The high computational cost and time investment are also significant practical hurdles. While the DGM shows promising results, its performance on SWE-bench still trails some closed-source, highly optimized systems. Finally, the entire process relies on the assumption that the chosen benchmarks are faithful proxies for the desired complex abilities. These limitations are well-recognized and frame an important research agenda. The transparency regarding objective hacking is particularly commendable and underscores the nuanced challenges in aligning self-improving systems.

The Darwin Gödel Machine marks a noteworthy advance in the pursuit of genuinely self-improving AI. By ingeniously combining empirical validation of self-coded modifications with principles of open-ended evolution, the authors have developed a system that not only demonstrates significant performance gains on complex coding tasks but also offers a new paradigm for how AI capabilities might autonomously grow. The system's ability to discover novel tool improvements and workflow strategies, and the generalizability of these discoveries, are particularly compelling. This paper offers a valuable and thought-provoking contribution to the field, paving the way for a new class of AI systems. While significant challenges related to computational cost, safety, true open-endedness, and the risk of objective hacking remain, the DGM framework represents a compelling proof-of-concept. Its exploration of self-referential improvement and evolutionary dynamics in AI agents will undoubtedly spark further research and brings us a tangible step closer to AI systems that can truly learn to learn and build upon their own discoveries.