
AlphaEvolve
A Gemini-Powered Coding Agent for Scientific and Algorithmic Discovery

AlphaEvolve: A coding agent for scientific and algorithmic discovery
Authors: Alexander Novikov, Ngân Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli and Matej Balog
Paper
Blog
DeepMind's latest innovation, AlphaEvolve, represents a significant advancement in AI-assisted algorithm development. It is a coding agent that orchestrates a pipeline leveraging large language models (LLMs) to produce algorithms solving user-defined problems.
How AlphaEvolve Works
At its core, AlphaEvolve runs an evolutionary algorithm that gradually creates programs improving performance metrics for a given task. Users must provide an evaluation mechanism—a Python evaluate() function that maps solutions to scalar metrics to be maximized. This evaluation can range from lightweight functions executing in milliseconds to complex distributed neural network training operations. This works for anything that can be automatically evaluated, all the things which require manual evaluation are outside of the scope.

The system provides an API where users can submit code with sections marked for improvement between # EVOLVE-BLOCK-START and # EVOLVE-BLOCK-END comments. Somewhere in the code there is also the evaluate() function, as everything else that ties the evolved pieces together.
The evolved program doesn't have to be the final result—it can be a means to achieve it. For example, the solution might be a string, a specific function defining how a solution should be created, a unique search algorithm, or something more complex. Task specifics influence approach selection; for problems with highly symmetric solutions, the authors recommend generating constructor functions as they tend to be more concise.
Key Components
AlphaEvolve's evolutionary cycle comprises several components:

Prompt Sampler: Manages prompt templates, including system instructions, and incorporates previously discovered solutions sampled from the program database. This component is highly customizable—users can add explicit instructions, stochastic formatting with externally defined distributions, evaluation result rendering, or evolve the meta-prompt itself.
LLM Ensemble: The paper describes a combination of Gemini 2.0 Flash and Gemini 2.0 Pro for creative generation. This mix enables rapid hypothesis generation through Flash and higher-quality recommendations from the slower Pro model. The system is model-agnostic, accommodating various LLMs. The models generate code changes as a series of diffs, specifying which code blocks to replace, though entire code replacement is also possible.
Evaluation: Contains a set of evaluators. In simple cases, it calls the user-provided
evaluate()function. Real-world applications include optional enhancements: cascades from simpler to more complex examples; feedback from LLMs when describing desired solution properties is easier than evaluation; and parallel evaluation. Multiple metrics can be calculated simultaneously, and the authors claim that optimizing across multiple metrics yields better results, even when only a single metric is important—a surprising finding given that multi-criteria optimization typically involves trade-offs.Program Database: An evolutionary database storing discovered solutions and quality assessments. Balancing exploration and exploitation is crucial here, so the database implements an algorithm inspired by a combination of MAP elites and island-based population models.

Implementation and Architecture
The entire system is implemented as an asynchronous pipeline (thanks to Python's asyncio), where multiple tasks operate in parallel and await results from previous steps when needed. The pipeline includes a controller, LLM samplers, and evaluation nodes, optimized for throughput rather than execution time of specific calculations. The system maximizes the number of ideas tested within a fixed computational budget.
Compared to previous systems like AlphaTensor, AlphaDev, and FunSearch, AlphaEvolve delegates more "intelligence" to the LLM. A direct comparison with FunSearch highlights three key differences: AlphaEvolve works at the level of the entire codebase rather than a single Python function; it supports multi-criteria optimization instead of a single objective function; and it employs state-of-the-art frontier models instead of smaller code-trained LLMs.

Applications and Results
AlphaEvolve has been applied to various tasks with impressive results:
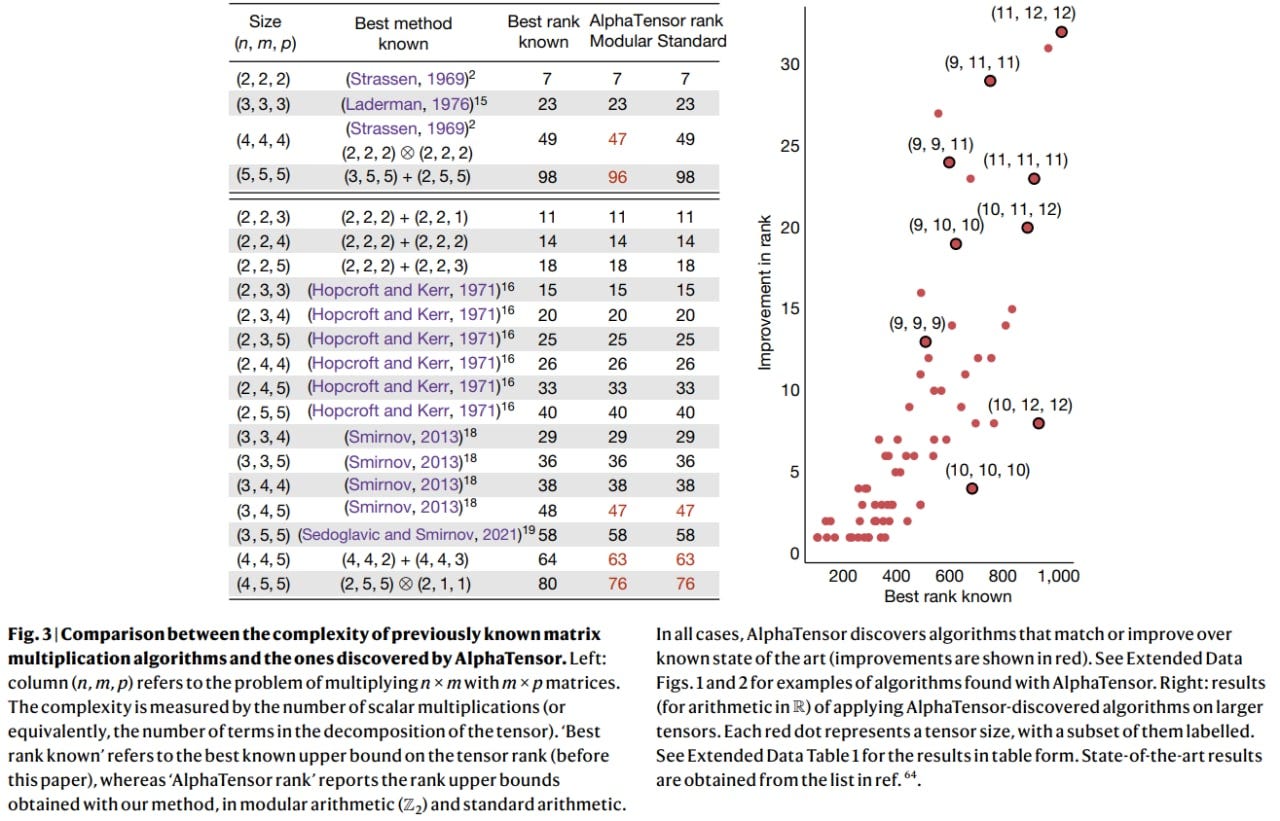
Tensor Decomposition: The same task addressed by the specialized AlphaTensor system. Starting with a standard gradient algorithm (including initializer, loss function for tensor reconstruction, and Adam optimizer), AlphaEvolve developed a new algorithm that improved state-of-the-art results for matrix multiplications of 14 different dimensions ⟨𝑚, 𝑛, 𝑝⟩.
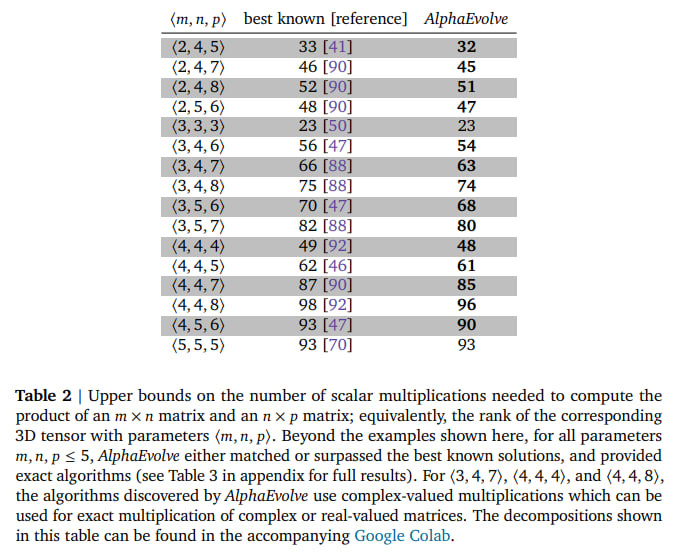
Notably, it achieved 48 scalar multiplications for size ⟨4, 4, 4⟩, compared to the previous 49 (though AlphaTensor achieved 47 using modular arithmetic, while this result is for complex arithmetic).
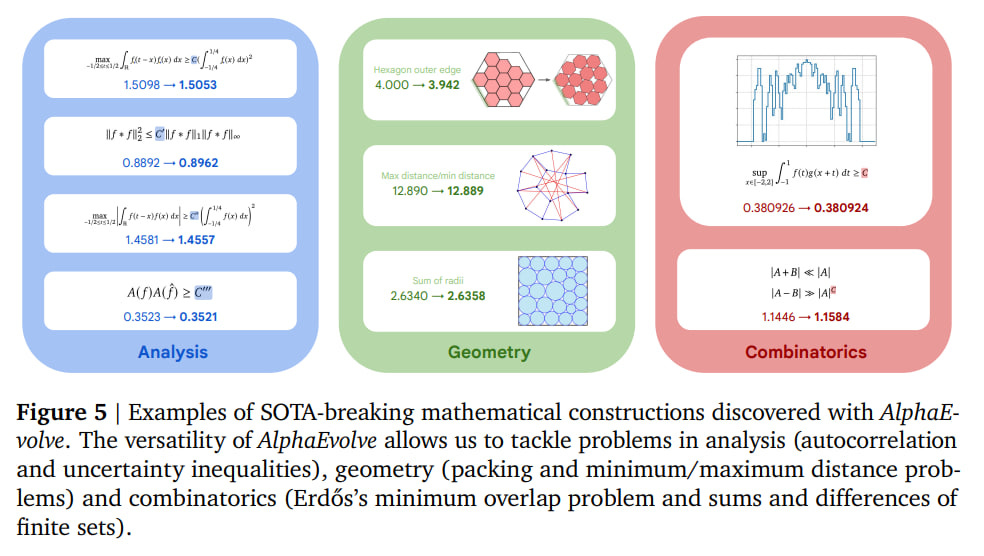
Mathematical Problems: Applied to 50 problems from analysis, combinatorics, number theory, and geometry, involving finding objects or constructions with specific properties, optimal or near-optimal by some measure. AlphaEvolve rediscovered known best solutions in 75% of cases and improved upon them in 20%. All tests started from random or simple solutions. Compared to classical approaches, AlphaEvolve offers greater versatility without requiring task-specific customization, autonomously discovering effective search patterns.

The key methodological innovation here is the ability to evolve heuristic search algorithms, rather than directly evolving the constructions themselves. In particular, the team used an iterative improvement strategy where at each step, the algorithm was given the best solution from the previous step and a fixed budget (1000 seconds), and the model had to find a better construction. This approach selected for heuristics capable of improving already good solutions, and the final construction was the result of a chain of various specialized heuristics—early ones specialized in improving simple or random initial states, while later ones focused on fine-tuning near-optimal solutions. The discovered mathematical results and tensor decomposition results are collected in a Colab notebook.
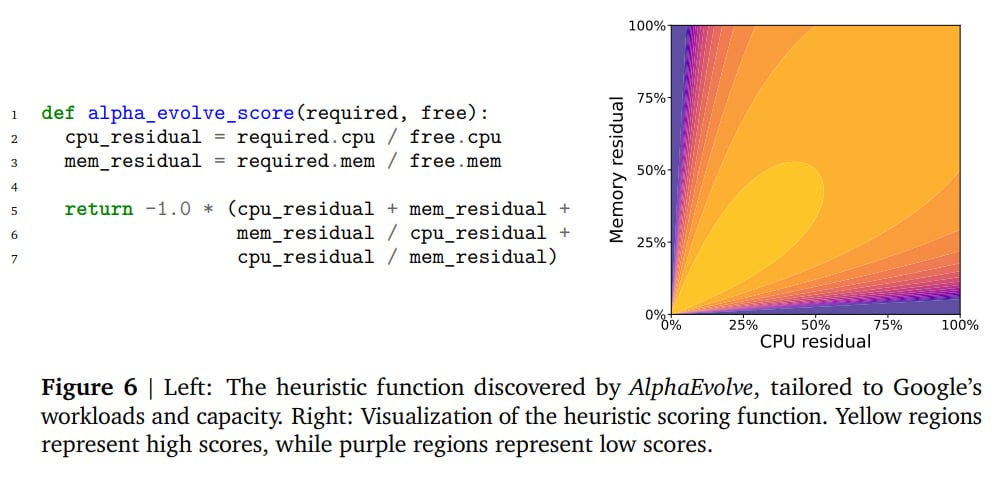
Google's Infrastructure Tasks: Used for scheduling tasks on Google's Borg-managed clusters, where jobs needed to be distributed across machines considering availability and CPU/memory requirements. AlphaEvolve found a heuristic improving Google's production heuristic, saving 0.7% of resources. Unlike deep reinforcement learning results, this solution is simpler and more interpretable.
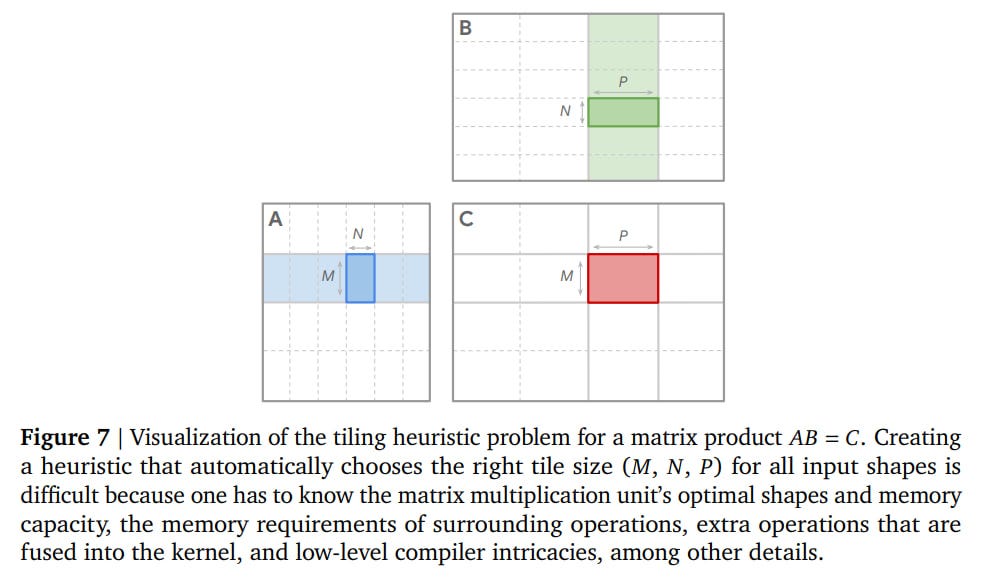
Matrix Multiplication Tiling: Applied to find heuristics for tiling in matrix multiplication used in Gemini kernels, which need to efficiently process input matrices of various sizes. The result was a 23% speedup compared to manual kernels and a 1% reduction in Gemini training time—significant at Google's scale. Instead of months of manual optimization, the process took days of automated work. This is an example of how good AI enables even better AI to be created faster, accelerating the exponential curve.
TPU Arithmetic Block Optimization: Working with highly optimized Verilog code, AlphaEvolve eliminated unnecessary bits, with results slated for integration into the upcoming TPU version.
FlashAttention Implementation: Applied to Pallas+JAX implementation, working directly with low-level XLA intermediate representations (IR). The optimization was verified for correctness and achieved a 32% speedup on the core and an additional 15% on pre/post-processing. This generally paves the way for eventually incorporating AlphaEvolve into compilers.




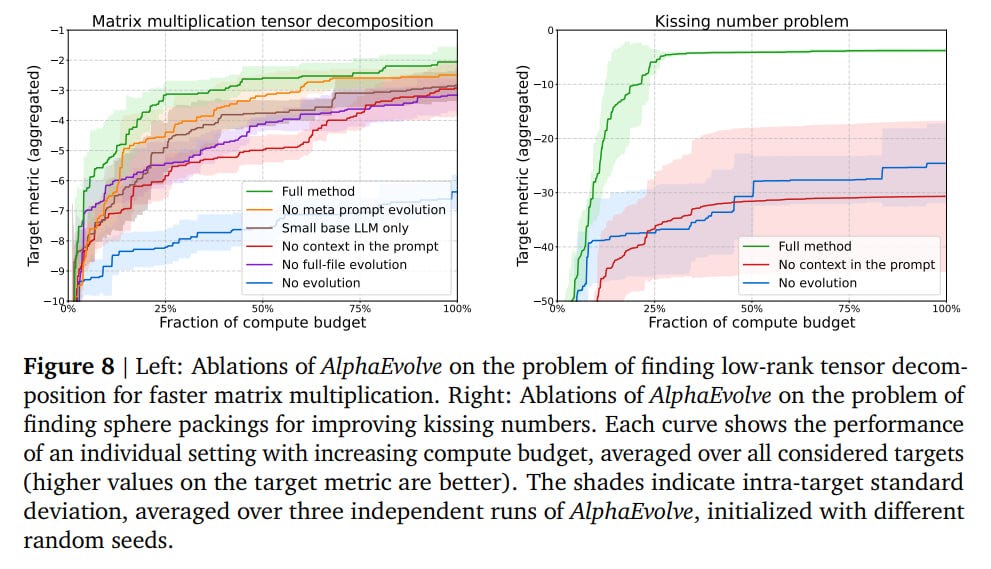
Ablation studies on matrix multiplication and a mathematical problem showed that each component—evolutionary approach, large context addition, meta-prompting, whole-file evolution instead of individual lines, and using larger LLMs in addition to smaller ones—improves results.
See also:

Broader Implications and Future Directions
Overall, this is pretty cool. Early experiments with using LLMs to guide search processes (like FunSearch) weren't as impressive to me, but now the results are genuinely good. We're once again experiencing a level-up in universality. Over the past decade of the deep learning revolution, we've been actively moving from very specialized single-task solutions to increasingly general ones.
For example, image classifiers were initially trained for specific tasks, and we trained all these VGGs and ResNets on closed sets of classes. After some time, it turned out there were models that could already perform classification on open sets of classes and even build classifiers without training on pre-trained models (like CLIP). Then it turned out that dedicated image models weren't even necessary; now VLMs can do many things, and creating new solutions is further simplified—just write prompts and explain what you need in plain English.
The same is happening here with mathematics and optimizations. We had very specialized models (AlphaTensor), then slightly more general ones with LLMs (FunSearch), and in the current iteration, they're even more general (AlphaEvolve).
Expert knowledge and skills in optimization are also continuing to be displaced by intelligent algorithms, as has been the case throughout neural networks' journey into computer vision. It's unclear whether anyone will still need to manually optimize kernels in 3-5 years. How many people on Earth are currently capable of doing this? And how many will there be? This is clearly not the limit—there will be even smarter systems that you simply explain what's needed to, or they might even figure it out on their own. It would be interesting to see how AlphaEvolve's results would change by incorporating Gemini 2.5 instead of 2.0. That would be an interesting substitution rather than an ablation.
All of this can also be viewed as a variant of test-time compute. What's the big difference between running reasoning on top of an LLM, some elaborate Tree-of-Thought, or evolution? Evolution is clearly superior to sampling. What if we distill an AlphaEvolve-augmented LLM into a regular LLM? And simultaneously ask it to optimize all the training and inference processes of this model (as was already done in the current work for Gemini and task scheduling)? The rich get richer, the exponential become more exponential.
And surely it's possible to add more specialized agents to such a system, with better critique capabilities and greater domain knowledge. Wow, the next version of AlphaEvolve could be absolutely revolutionary. It might be a unique merger with AI co-scientist, which didn't have code evolution but was purely language-based (with the risk of hallucinations), though it did feature multi-agent functionality.

The current work is also an interesting development in terms of evolutionary algorithms. Previously, one had to write various custom operators (like crossover or mutation in the case of genetic algorithms, of which I have written a huge number myself). Now none of this is necessary — the LLM itself decides how and where to evolve the solution, implicitly implementing the same operators but utilizing all the world knowledge from pre-training. And I think domain-specific LLMs could be even significantly better here. And they surely will be.
This is all very cool. Long live LLM-guided evolution!
P.S. It's also nice to see many familiar names among the authors or acknowledgments. Hello to everyone!
It would be very interesting how academia and uni labs start using llms as grad students