


Chain-of-Thought → Whiteboard-of-Thought
When visual reasoning helps

We once wrote about the Chain-of-Thought (CoT) extension and the transition to Tree-of-Thought (ToT), and somewhere around there was a bunch of works on more complex Graph-of-Thoughts (GoT, https://arxiv.org/abs/2308.09687) and even Everything-of-Thoughts (XoT, https://arxiv.org/abs/2311.04254).
The approaches listed above use text to enhance reasoning. However, there is another development specifically for multimodal models, particularly visual language models (VLM), involving the use of drawings to aid "thinking."
Recently, two similar works were released (though there are surely more):
Visual Sketchpad
“Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models” (https://arxiv.org/abs/2406.09403 and https://visualsketchpad.github.io/) by authors from the University of Washington, Allen Institute for AI, and the University of Pennsylvania came out a week earlier.

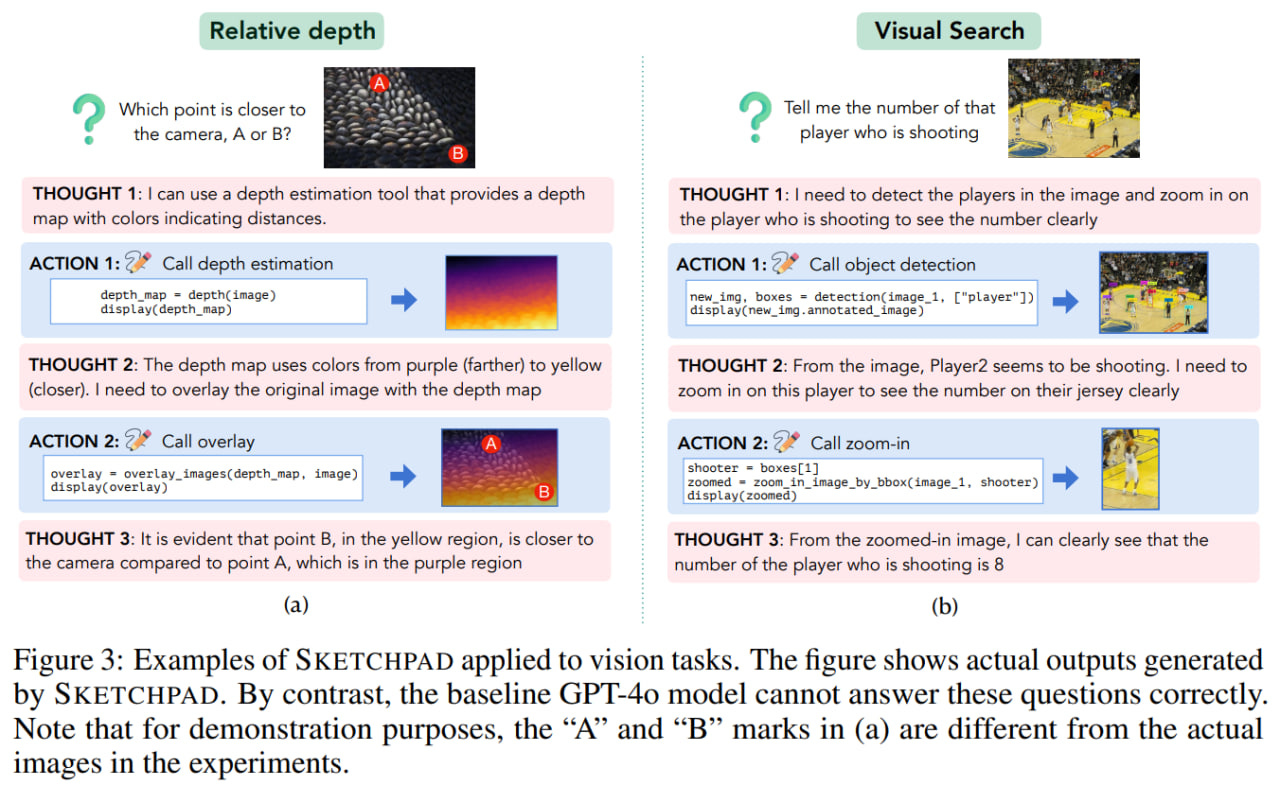
In this approach, the model is given access to a sketchpad and tools for drawing intermediate "thoughts" that the model can further use. This is reminiscent of the ReAct approach, where an agent generates thoughts, performs acts, and receives observations. In Sketchpad, these three components are also present, and the model doesn’t need to be trained to use all this; everything is achieved through prompting.
For example, in a geometric task with an existing image as input, the model might decide (thought) to draw an auxiliary line, generate Python code to modify the input diagram (act), and receive context (observation) with the updated diagram. The model can repeat this process until it generates a special Terminate action—then it provides the final answer.

Sketching tools can vary depending on the task, for instance, Python with matplotlib and networkx (for graph tasks), special visual models for detection and drawing of bounding boxes, labeling, and segmentation.
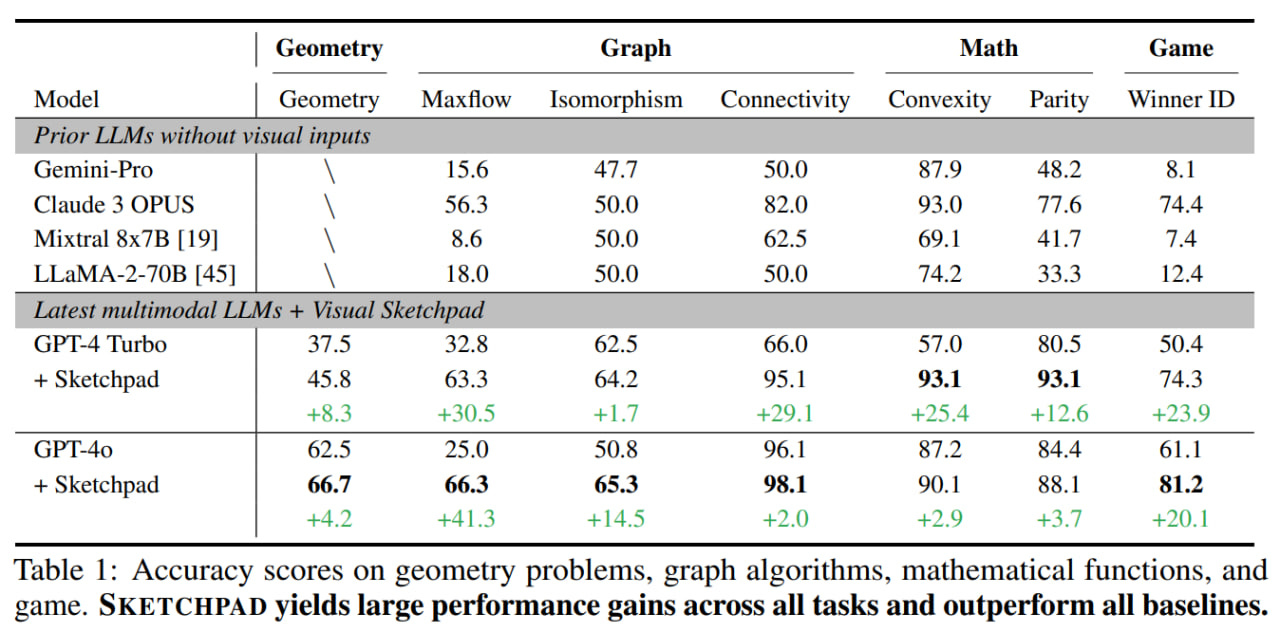
The results are decent; compared to the basic GPT-4 Turbo and GPT-4o, using the sketchpad adds from a few to dozens of percentage points to accuracy on tasks in geometry, mathematics, graphs, and games. The baselines seem very basic; it would be interesting to see comparisons with baselines from CoT/GoT/XoT.
The authors compared the solution plans for geometric problems with human ones, and they largely overlap.
On tasks with various visual reasoning baselines, already with various augmentation frameworks, the results are excellent. GPT-4o with the sketchpad set a new state-of-the-art (SoTA)!

Whiteboard-of-Thought
“Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities” or WoT (https://arxiv.org/abs/2406.14562) is generally very similar but simpler, in two steps.

The model is also given a metaphorical whiteboard, meaning the model can generate images that will be considered in subsequent inference steps. This also uses prompting (e.g., “You write code to create visualizations using the {Matplotlib/Turtle} library in Python, which the user will run and provide as images. Do NOT produce a final answer to the query until considering the visualization.”) and the model’s basic ability to generate Python code (Turtle and Matplotlib), which is then executed through a Python interpreter, and the resulting image is parsed by the model.



They tested it on visual reasoning tasks, including tasks from BIG-Bench on understanding ASCII text graphics (MNIST digit recognition, word recognition, kanji recognition), and spatial navigation based on language descriptions.
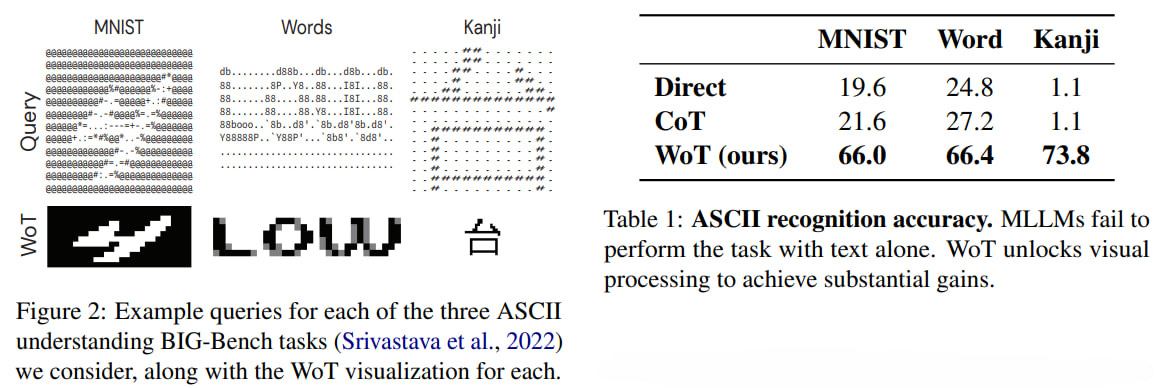
The boost on ASCII tasks is huge; models, by default, perform poorly on such tasks, and CoT doesn’t help much. On spatial navigation, default models do well with 2D grid tasks but poorly with other geometries, where WoT helps.

Overall, the approach works. It’s also amusing to observe works increasingly built on using the OpenAI API.