
OLMo: Accelerating the Science of Language Models

Paper: https://arxiv.org/abs/2402.00838
Authors: Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
Models: https://huggingface.co/allenai/OLMo-7B
Code: https://github.com/allenai/OLMo
Data: https://huggingface.co/datasets/allenai/dolma
Evaluation: https://github.com/allenai/OLMo-Eval
Adaptation: https://github.com/allenai/open-instruct
W&B Logs: https://wandb.ai/ai2-llm/OLMo-7B/reports/OLMo-7B--Vmlldzo2NzQyMzk5
Truly Open
Allen AI, primarily, along with representatives from four universities, announced the truly open model OLMo. As they state, “a state-of-the-art, truly Open Language Model”.
It seems everything is open: beyond the usually published weights, sometimes published training code and dataset, here the entire framework is open, including logs, checkpoints and evaluation scripts, all under the Apache 2.0 License. OLMo is primarily aimed at language model researchers.
Before this, a similar level of openness was demonstrated by the BigScience consortium with their BLOOM model, but their models, by size (176B), were not for the average user, and by today's standards, are no longer top-tier. More accessible models included Pythia and LLM360.
OLMo
The family includes three models: 1B, 7B, and 65B (still in training).

OLMo is a classic transformer decoder (like GPT) with some improvements: no biases, a non-parametric formulation of layer norm (without adaptive linear transformation), SwiGLU, RoPE embeddings, and a BPE tokenizer (modified GPT-NeoX-20B) with a vocabulary of 50,280, including separate tokens for hiding personal identifiable information (PII).

A comparison with the recent Gemma can be found here.
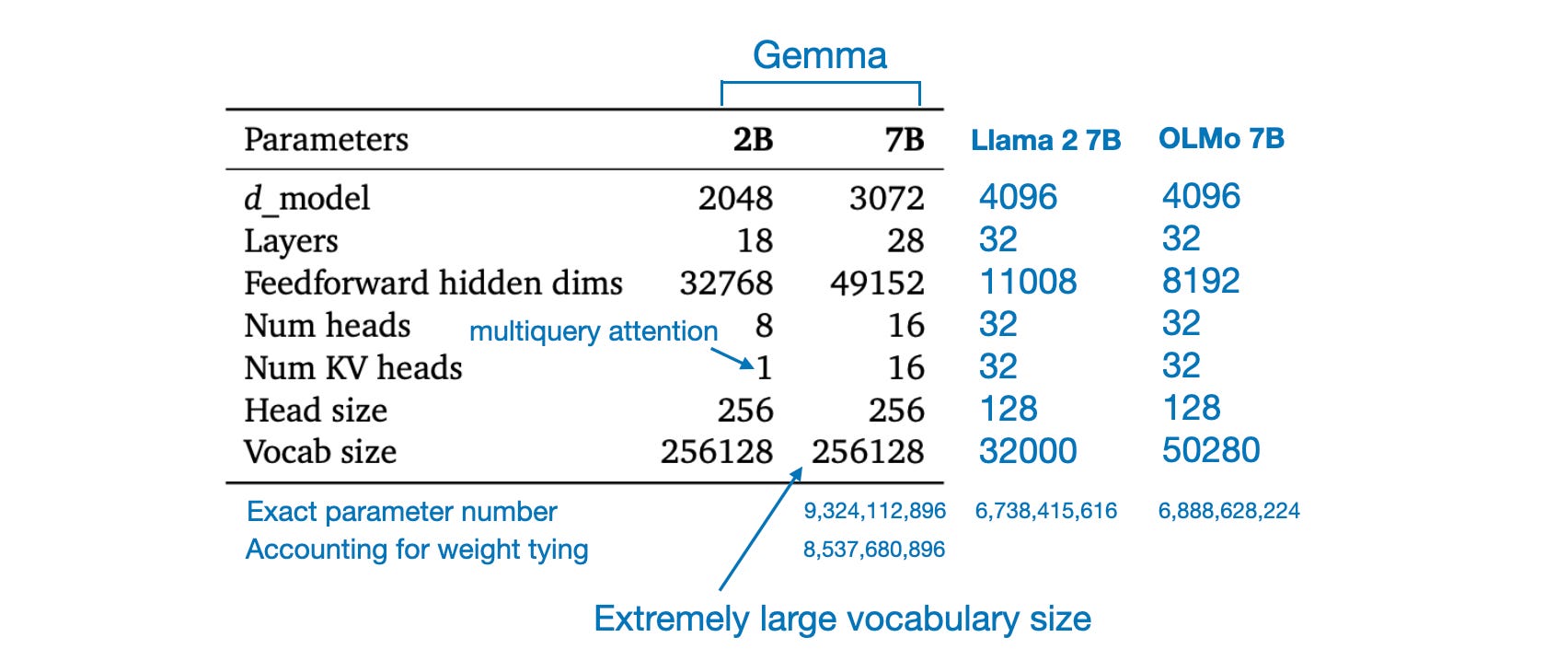
The 1B and 7B OLMo were trained on 2T and 2.46T tokens, respectively. These numbers are roughly the same as those for Llama 2 7B and Gemma 2B -- they had 2T, more than Phi-2 2.7B with 1.4T, but less than Gemma 7B with 6T.
The dataset is their own open Dolma with 3T tokens and 5B documents. By the way, Olmo-1b was first announced in the paper on this dataset.

Currently, the dataset is primarily in English, but there are plans to expand it to other languages. For those needing more than just English, one option is here.
The pre-trained models were fine-tuned for chat on Open Instruct (TÜLU, https://arxiv.org/abs/2311.10702) through instruction fine-tuning + DPO on preferences.
For model checkpoint evaluation, they used their own benchmark Paloma (Perplexity Analysis For Language Model Assessment, https://arxiv.org/abs/2312.10523) and the evaluation framework Catwalk (https://arxiv.org/abs/2312.10253).
They trained with PyTorch FSDP using mixed-precision training. The optimizer was AdamW, and it trained for one epoch on 2T tokens selected from 3T.

Interestingly, they tested on two different clusters: LUMI (we mentioned it here) with AMD MI250X (up to 256 nodes with 4 GPUs each with 128GB) and MosaicML with NVIDIA A100 (27 nodes with 8 GPUs and 40GB). With minor differences in settings (batch size), the final performance of the models was nearly identical. It would be interesting to compare the efficiency of the clusters themselves and their costs. By GPU count, LUMI used almost 4 times more hardware, and in terms of memory, it was 15 times more (131TB versus 8.6TB). It's unclear why this was the case.
In zero-shot results, OLMo was slightly below Llama (first and second), Falcon, and MPT.

Compared to instruction-tuned versions, it was about on par with Llama-2-Chat. Overall, it noticeably lags behind the top models of today, like Gemma 7B, but Gemma is not as open; it's open but not open source.

As is now customary, they calculated the carbon footprint. In the LUMI cluster, it was zero (because it runs on hydroelectric power), while in the NVIDIA cluster in Australia, it was 70 tCO2eq.

If I understand correctly, a round trip between Boston and London emits one ton per person, and if there are roughly 300 people on that flight, that's equivalent to four such model trainings.
In general, it's cool that everything is open, making research on this straightforward. From a commercial application standpoint, it's probably better to fine-tune Gemma 7B.