
Optimizing Distributed Training on Frontier for Large Language Models
Training LLMs on AMD GPUs!

Authors: Sajal Dash, Isaac Lyngaas, Junqi Yin, Xiao Wang, Romain Egele, Guojing Cong, Feiyi Wang, Prasanna Balaprakash
Paper: https://arxiv.org/abs/2312.12705
This interesting paper discusses how large Language Learning Models (LLM) were trained on the Frontier supercomputer, ranked number 1 in the TOP500 list.

AMD GPUs are finally coming to Deep Learning
Frontier is unique in that it is built on AMD CPUs and GPUs, EPYC and MI250X, respectively. The second supercomputer in the TOP500, Aurora, is entirely built on Intel (both CPUs and GPUs). Only the third, Eagle, uses NVIDIA H100 and Intel Xeon.
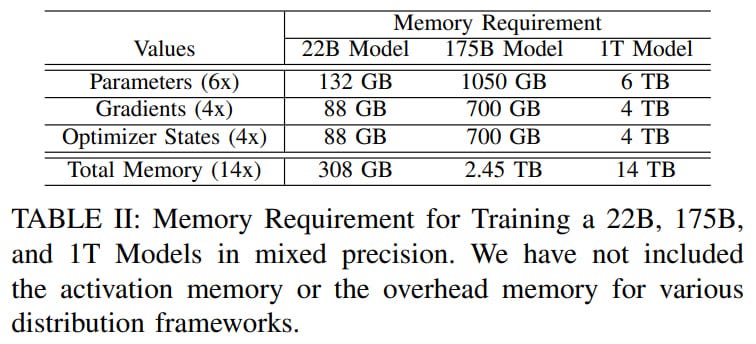
Models of 22B, 175B (the size of GPT-3), and 1T parameters were trained. The latter two used 1024 and 3072 MI250X GPUs (out of a total of 37,888).

For me, the most interesting part of this story is exactly how they trained these models on these cards, as for a long time using anything other than Nvidia and CUDA was not very feasible. Now, there's a surge of work on training large networks on AMD GPUs. This can be seen with the Finnish supercomputer LUMI (used 512 AMD MI250X GPUs), support in HuggingFace Transformers (with AMD's ROCm GPU architecture is now supported across the board and fully tested with MI210/MI250 GPUs, and more), and training RetNet at MicroSoft (used 512 AMD MI200 GPUs). Finally, it seems there's some real competition.
Of course, the large scale and the problems that arise there are also interesting.
Training LLMs
In mixed precision training, each model parameter needs 6 bytes (4 for the model in fp32, 2 for computations in fp16), 4 bytes per optimizer parameter (to save the momentum in Adam in fp32 – it's unclear here, Adam should have two different moments), and 4 bytes for the gradient of each parameter (fp32). Thus, for a 1T model, 14T parameters are required.
Each Frontier node contains 8 MI250X GPUs, each with 64 GB HBM, making model parallelism necessary.

There are several options. In tensor parallelism, large weight matrices are split by rows or columns. In pipeline parallelism, the model is divided by layers into several stages, each living on one GPU, with several layers per stage. Sharded data parallelism is similar to classic data parallelism, but instead of hosting copies of the entire model on each device (which is unrealistic with these sizes), only the currently computed layer is hosted on each device.

Different methods can be combined to create a hybrid (a moment of advertising, in my upcoming “Deep Learning with JAX” book by Manning, there's an example of mixing data and tensor parallelism for neural network training, and in general, the largest chapters are about parallelism, there are three of them). In the current work, 3D parallelism is used for better resource utilization, including tensor, pipeline, and data (both regular and sharded) parallelism.

They used the Megatron-DeepSpeed framework with support for different types of parallelism (tensor, pipeline, data, sharded data parallelism). Originally, it was focused on NVIDIA (and is a fork of their Megatron-LM with added features), but in this work, it was adapted for AMD ROCm.
The adaptation included:
Converting CUDA code to HIP code via the
hipifyutility, compilingsofiles throughhipcc, and binding to Python viapybind.Preparing DeepSpeed Ops (CUDA extensions originally obtained through JIT compilation) for ROCm and disabling JIT just in case.
Initializing the PyTorch Distributed Environment with a host from SLURM.
Working with AMD to obtain ROCm versions of necessary libraries, like APEX for mixed precision, FlashAttention, and FlashAttention2 (for these, they used the Composable Kernel library).
They experimented with different parallelization strategies and their parameters, as well as with training hyperparameters, to find the optimum.

For details and observations, welcome to read the article.

In the end, they achieved a working configuration, reaching 32-38% of peak FLOPS. Through Roofline Analysis (I wrote about this at here), they showed that the training is not memory-bound. They tested scaling, achieving 100% weak scaling and 87.05% strong scaling efficiency for the 1T model.

No trained models were released, as that was not the goal.
I hope all this progress leads to open-source availability and that AMD support eventually reaches a commendable level across the board. We wait and hope.