


NVIDIA's Vision for AI
My takes from the Jensen Huang's CES 2025 Keynote

NVIDIA CEO Jensen Huang's CES 2025 keynote is worth watching:
First, it's beautifully done (as usual). Second, I believe this company will shape our lives more significantly than its TOP-2 market cap neighbor, Apple. Don't rely entirely on news summaries (including mine) — form your own impressions. There aren't many keynotes this globally significant in a year — maybe Google, OpenAI, and probably Apple, though I'm less certain about the latter.
By the way, I didn't understand why the video on CNBC's channel is 12 hours long — it seems they looped the broadcast and recorded it several times. I was initially scared it would be a one-man show for 12 hours. Fortunately, it was just under two hours. Still, Jensen energetically bounces around the stage the whole time, wearing his upgraded leather jacket.
It's an impressive founder-led company, what can I say. Other non-founder-led companies (I won't point fingers) can't match this. Who even knows their CEOs? Usually nobody. Or even if you do know them, what's the most important thing you can say about them? Again, usually nothing meaningful. Well, there's your answer about market cap and market prospects.
RTX Blackwell
The history of universal and programmable GPUs, and later CUDA, is somewhat similar to the story of the first programmable microprocessor, Intel 4004. Someone first had to realize that universality matters. And the market only came to understand this innovation years later. And now we are where we are, thanks to games and calculators.
Games are also upgrading, with rendering becoming different. Only a small number of pixels are actually rendered, while the rest are calculated by pre-trained neural networks directly on the chip. Huang gave an example where only 2 million pixels out of 33 are calculated through rendering, while the rest are generated by AI. This neural rendering story is comparable to MLSys, where heuristics are replaced by learning, or even more similar to scientific simulations, where complex and time-consuming computational models are replaced by fast neural networks — everywhere, hard-coded software is being replaced by neural predictions (I should really finish writing about neural operators... I remember, Kamyar, I promised… 🙂).
The new RTX Blackwell is a powerful chip with enormous memory bandwidth (1.8TB/s) and 4000 AI TOPS, which is three times more than the previous Ada generation.

There's always a question about what exactly these AI TOPS mean, as it's different each time. I hoped it wasn't FP4, but I suspect it is. First, because it makes the numbers bigger :) And second, because he uses them in other places later.
For those who want to know what FP_something means, here is my old post on the subject. It stopped on FP16, but you’ll get the idea.
The gaming cards are pretty impressive:
High-end 5090: 3400 AI TOPS $1999
Entry-level 5070: 1000 AI TOPS $549

For half a thousand dollars, we get what amounts to a (kind of) petaflop on our desk. For context, the first teraflop supercomputer (1000 times weaker) was ASCI Red from 1997, and the first petaflop computer was IBM Roadrunner in 2008. But this comparison isn't entirely fair, as teraflops were "greener" in the past. In TOP500, these were FP64, not some FP4. Still cool, though.
When I wrote my hardware overview for deep learning in 2018, FP32 was the standard in this field, with top cards reaching up to 20 TFLOPS. FP16 and tensor cores were just emerging then, pushing performance to around 130 TFLOPS. And now we have 3 PFLOPS in a single high-end desktop card.
But nobody trains on a single card anymore... Real training requires enormous clusters. And besides compute, you need lots of memory, which gaming cards barely have. The current record is 32GB in the 5090, right? There were some Quadro RTX 8000s that had up to 48GB, but those were exotic and non-gaming expensive cards. AMD is interesting with their MI series; their top model, MI325x, currently has 256GB, but that's also not for gaming.
There's not much you can do with gaming cards here. Sure, you can build a cheap DGX alternative, but it's all suboptimal. NVIDIA long tried to separate these two markets, and now it seems they've naturally arrived at this separation.
Back to Blackwell, it claims 4x performance per watt and 3x per dollar compared to the previous series, which is a big deal for data centers. There are energy issues, and training costs are growing, so if you can save 3-4 times on these parameters, that's significant. I'm afraid, though, that within these coefficients, x2 comes from switching from FP8 to FP4 evaluation...

They announced NVLink72, and Huang stood on stage with a shield shaped like a wafer-giant chip, similar to Cerebras, but I understood this was a metaphor for what such a chip would look like if the current NVLink72-based system with 72 GPUs were placed on a single chip.

Project Digits
Huang is quite the magician (watch this moment in the video), almost like Buster Keaton a hundred years ago. By the way, if you don't know Keaton, I highly recommend him — my kids are huge fans of both Chaplin and Keaton.
Project Digits is a very interesting announcement. It's a miniature DGX with a complete AI software stack, based on the new GB10 chip with 1 PFLOP FP4, 20 ARM cores, 128GB DDR5X memory, and 4TB SSD. Interesting to see how much power it consumes and how quickly it'll be adapted for mining. And all this for $3000. I want one!

Gaming cards have long become a suboptimal solution for practical models — the top card of the new generation has only 32GB of memory, which is only suitable for not-very-large models, as many medium-sized LLMs won't fit without quantization and other memory-saving tricks. Now 128GB is pretty good. You can connect a couple together and then you can even infer Llama 405B, I assume with quantization.

It's also great because we've all massively moved to laptops and clouds, and having a desktop system with a GPU might just be inconvenient. But here's a small portable network device. In short, I want one!
This is actually a very interesting topic, and I'm sure it shows the contours of the future. Having a local home device for inference is becoming increasingly sensible, especially with the approaching agent-based present.
Just as we had NAS (Network-attached Storage), we should have NAG (Network-attached GPU). Local inference of LLMs and other tasks will happen there, in the home AI computing center. Smart home, people recognition at the door, home agents... — much of this would make sense to do right on-site. But there wasn't really a mass convenient place for it.
ASI may start up one day in a dusty corner. Or this is how Joi from Blade Runner will appear. 🙂
There's clearly room for a new player here, and I think many such solutions should emerge. I wouldn't be surprised if they come from Chinese companies.
What does such a device need? Not that much:
Store large models and be able to keep them in memory, ready for fast inference
Efficient inference
Ability to scale test-time compute (should be out of the box with efficient inference, but I admit it could be done suboptimally)
Good network, but without going crazy
Full training isn't needed (not those scales), but fine-tuning (LoRA) might make sense
As a bonus/different important niche, there is local model training and small-scale AI development. This might need a separate type of device closer to Digits, and with a focus on higher-precision formats required for training, FP4 is definitely not enough.
Interesting to see who will make it and when.
Special chips seem to be becoming easier and cheaper to design.

Maybe someone will create one on ARM or RISC-V? And with tons of memory. Cerebras, by the way, could release a Cerebras mini, for example 😁
World models and agents
I saw many thoughts from Huang that I've been thinking about myself. Just recently wrote about agents, that it's the same test-time compute, and about the importance of world models. Nice to be on the same wavelength.
Scaling continues. Moreover, three scaling laws are now acting simultaneously:
pre-training scaling (as usual)
post-training scaling (RLHF, RLAIF, ...)
test-time scaling (reasoning)

And NVIDIA will continue to thrive in this world.
We also talked a lot about agent onboarding and HR stories for them at Intento once, that all this ultimately leads to hybrid teams. Now, we're closer to this than ever. Huang says that company IT departments will become HR departments for agents.
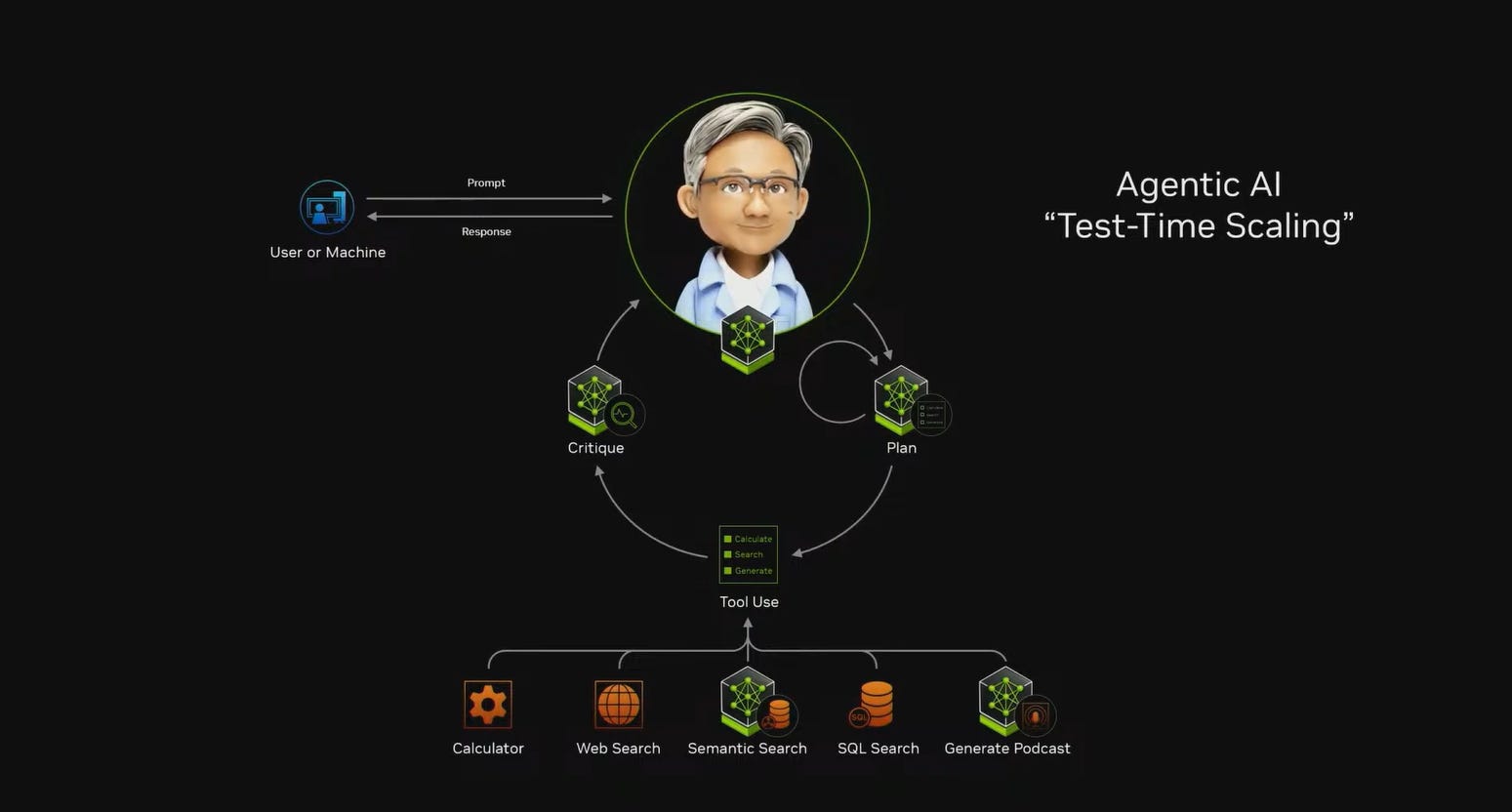
NVIDIA is now trying to create AI libraries similar to CUDA libraries. This will be an ecosystem around NIM, NeMo, AI Blueprints. It's a good theme, but honestly, I believe less in NVIDIA's dominance here because it's no longer tied to their chip architecture, but on the other hand, NVIDIA is such a system player operating at different stack levels that maybe no one else can approach the issue as systematically. We'll see if this works, or if individual components and their interfaces will come to good architectural solutions on their own (through others' efforts). I tend to believe in the latter.
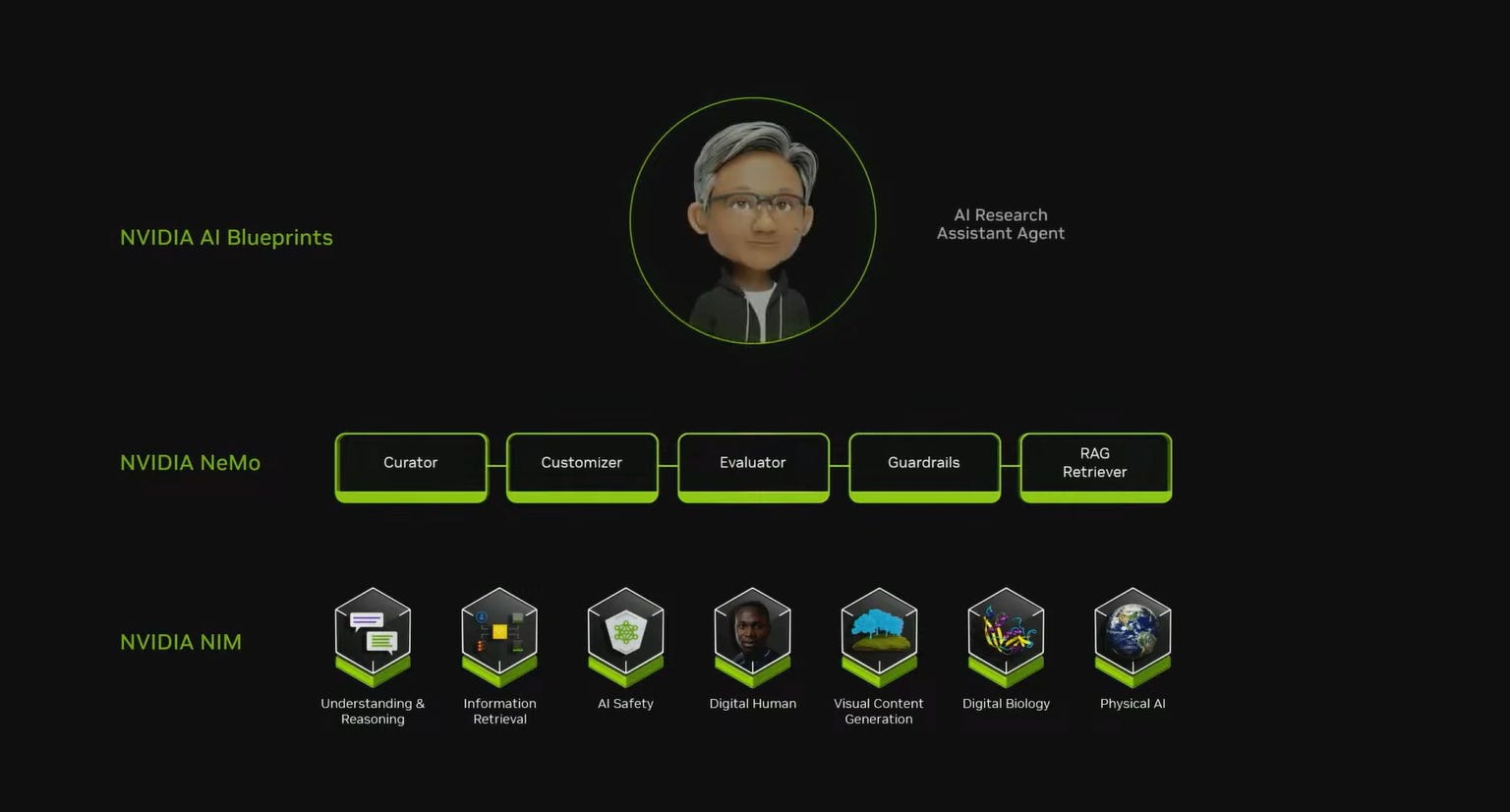
They announced optimized Llamas, the Llama Nemotron family: Nano, Super, Ultra. It's pretty cool how Zuckerberg (with another founder-led company) disrupted everyone. The most interesting things are still ahead, we'll see how the ecosystem develops in a year or two.

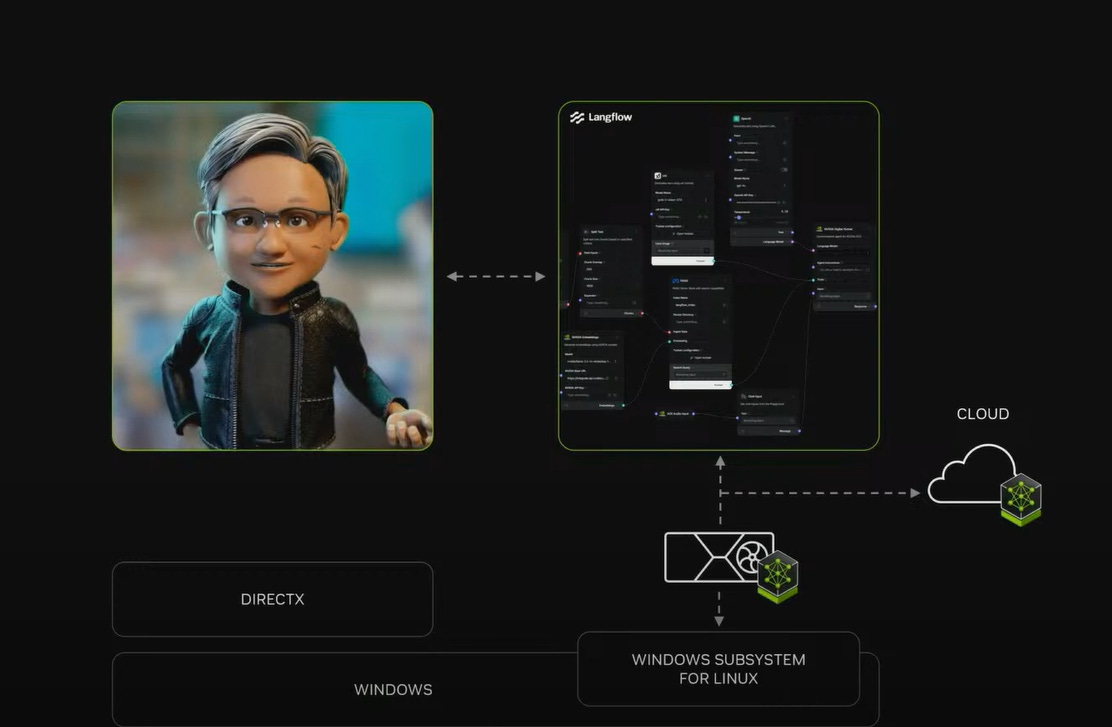
Went through Windows with the desire to turn Windows PC into AI PC based on WSL2, the second version of Windows Subsystem for Linux (a system integrating Linux into Windows). NVIDIA is going to focus on WSL2, so AI PC will emerge from here. I understand this is an alternative path to what Microsoft proposed with their Copilot in Windows.
Another big topic is Physical AI and (surprise-surprise) world models. NVIDIA Cosmos is a platform for such models, where among World Foundation Models there are autoregressive and diffusion models, video tokenizers, and video processing pipelines.

Also planned is a Nano, Super, Ultra lineup. Interestingly, Ultra models are positioned as teacher models, for distillation for example. The model (not sure which one exactly) in Cosmos is trained on 20 million hours of video.
Now there's Omniverse for rendering and Cosmos for neural rendering. Interesting if Zuckerberg is planning to disrupt here? First, they were doing similar things about Omniverse/Metaverse, now some have LLM while others have optimized the same LLM + World Models — there feels like a slight asymmetry in such configuration. The void must be filled 🙂

Omniverse is essentially physics-based and serves as the ground truth for Cosmos. This is a cool configuration, I like it. Huang compares this to RAG for LLM. Here is another approach to how game engines of the near future might look (we touched on this in the World Models section of the Quick Reflection on AI in 2024 post).
The Cosmos platform is available on GitHub under an Apache 2.0 license, and the models are on Huggingface under NVIDIA's open license (haven't looked deeply into the details yet, but at least "Models are commercially usable. You are free to create and distribute Derivative Models. NVIDIA does not claim ownership to any outputs generated using the Models or Model Derivatives.").

Huang talked a lot about digital twins, robots, and automobiles, there are many announcements here too, including processors, Drive OS, Isaac GROOT. NVIDIA is targeting three types of robots: Agentic AI, Self-driving cars, humanoid robots.
They're really pushing tokens everywhere, tokens all around. We're waiting for utility bills with sections showing payment for tokens.

If you really can't watch all one and a half+ hours, at least watch the brief five-minute summary at the end. First of all, it's simply beautiful.