
ModernBERT, the BERT of 2024
Breathing new life into BERT with state-of-the-art efficiency and performance

Title: Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Authors: Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, Iacopo Poli
Paper: https://arxiv.org/abs/2412.13663
Models: https://huggingface.co/collections/answerdotai/modernbert-67627ad707a4acbf33c41deb
Blog: https://huggingface.co/blog/modernbert
Remember BERT? While Large Language Models (LLMs) have been stealing the spotlight lately, BERT is far from dead! Answer.AI and collaborators have just released ModernBERT — a modernized and accelerated version that brings this architecture into the present day.
Let's quickly refresh our memory. The original Transformer architecture included both an encoder and a decoder, and the first models in 2017 followed this pattern (with T5 being a prime example, inheriting the original Transformer's code).

Then came 2018's "ImageNet moment" in NLP with the arrival of BERT, which used only the encoder part of the Transformer. Later, with the emergence of GPT (which uses only the decoder), many researchers shifted towards pure decoder architectures, which offer much more flexibility for generative tasks. However, encoder-based BERT-like architectures remained popular in specific circles for classification tasks, sequence labeling, and embedding generation.
Back then, BERT was considered large (110M and 340M parameters for base and large models, respectively), but compared to today's 100B+ models, it's tiny and fits perfectly on devices and servers without requiring numerous GPUs. Since BERT's introduction, we've seen many improvements: RoBERTa, various distilled versions like DistillBERT, interesting solutions similar to Adaptive Computation Time (ACT) like ALBERT, and finally DeBERTa. And now we have ModernBERT!
The new architecture brings numerous improvements:
Removal of bias terms from linear layers (except the output layer) and LayerNorm layers
RoPE (rotary positional embeddings)
Pre-normalization with LayerNorm
GeGLU activations
Additionally, several efficiency improvements have been implemented:
Alternating Attention with alternating global and local attention (every third layer uses global attention, others use local sliding windows of 128 tokens)

Image from the original blog post Unpadding to eliminate unnecessary computations on padding tokens

Image from the original blog post Compilation through
torch.compile, providing a welcome 10% improvement in throughput


The layer architecture was optimized for typical GPUs (server-grade NVIDIA T4, A10, L4, A100, H100, and consumer RTX 3090 and 4090, focusing on inference), resulting in base and large models with 22 and 28 layers and 149M and 395M parameters respectively (slightly larger than the original).

The model was trained on 2T tokens (a mix of English and code) with a context length of 8192 (compared to just 512 in BERT and RoBERTa). They replaced the old wordpiece tokenizer with BPE, using a modified version from OLMo. The original special tokens like [CLS] and [SEP] were retained for compatibility.
Training uses Masked Language Modeling (MLM) objective, abandoning Next-Sentence Prediction (NSP) objective like many other BERT variants (such as RoBERTa). They employed StableAdamW optimizer with a modified trapezoidal Learning Rate schedule (Warmup-Stable-Decay, WSD). The training process uses batch size scheduling, starting with smaller batches and gradually increasing them. Weights were initialized from Megatron for the base and Phi for large models. The first 1.7T tokens were trained with a context length of 1024, then expanded to 8192 for the remaining 300B tokens.
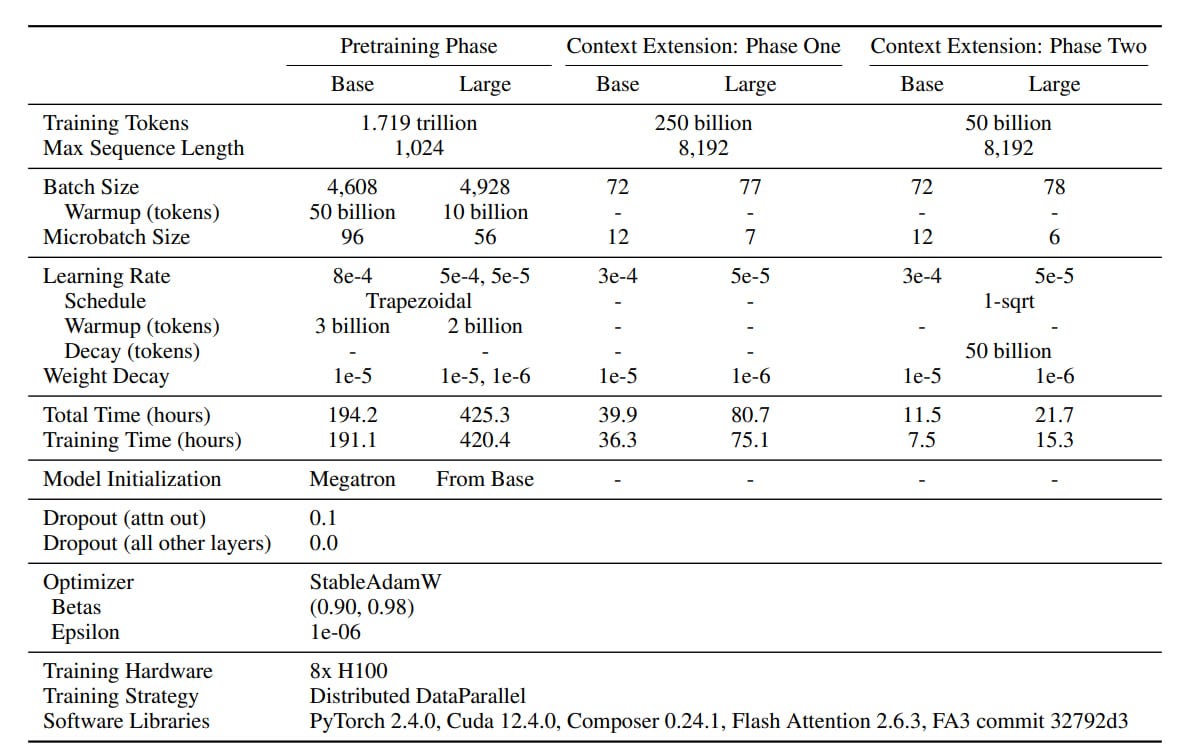
It would be fascinating to see a phylogenetic tree of BERT evolution (and Transformers in general), showing how different ideas were inherited and transferred between models. Has anyone seen something like this?
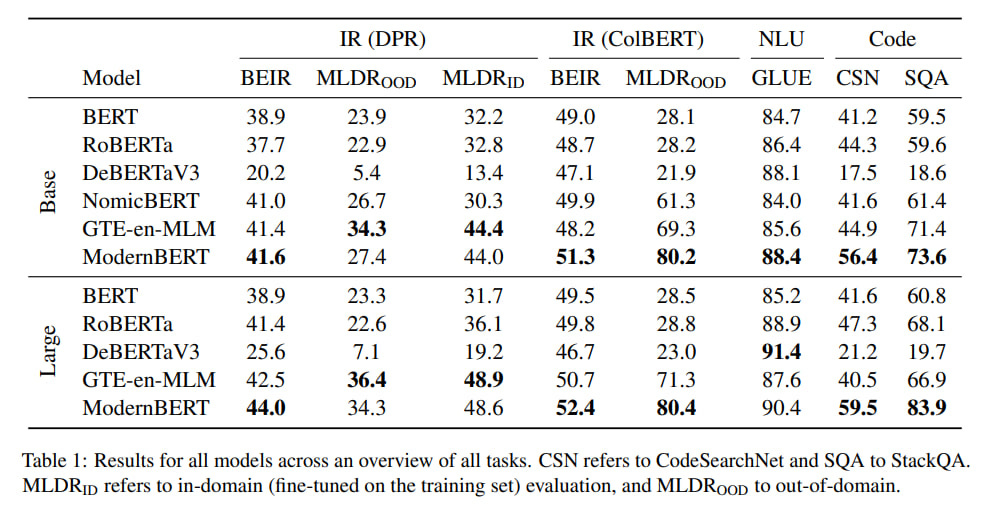
The model was evaluated on NLU, text, and code retrieval tasks, where ModernBERT shows impressive results.
In terms of efficiency (maximum batch size and throughput in thousands of tokens per second), the performance is excellent.

We essentially have a new state-of-the-art model with outstanding performance that's Pareto-efficient in terms of processing time per token versus GLUE benchmark quality.

Pretty cool, right? The next logical step would be multilinguality.
Regarding a phylogenetic tree of architectures, the most relevant such thing I've seen is here: https://www.sciencedirect.com/science/article/pii/S2666651022000146#fig3 — though it's certainly not as a elaborated as it could be!