
Many-Shot In-Context Learning
What happens if you provide thousands of examples inside a prompt?

Authors: Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Stephanie Chan, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
Paper: https://arxiv.org/abs/2404.11018
Building on the theme of very large contexts, models now support many-shot in-context learning (ICL) or ICL with a very large number of examples (hundreds, thousands or more). In times when context sizes were 2-4k tokens, it was hard to imagine, as even a few examples didn't always fit well. However, with 1M context (like with Gemini 1.5 Pro), life changes. Unlike fine-tuning, ICL mode does not require optimizing model parameters and can be adapted to the task during inference. However, the cost and speed of inference might remain an issue.
Many-shot ICL
The authors demonstrated that many-shot ICL scales well, and the quality of solving various tasks increases with more examples in the prompt.

They used Gemini 1.5 Pro, employing greedy decoding. For more reliable results, they sampled examples with different seeds multiple times for each prompt, ensuring each K-shot prompt included all examples from smaller K prompts.
For the task of machine translation into low-resource languages (Kurdish or Tamil), the improvement is negligible from 1 to 10 examples in few-shot mode. However, as the number increases to nearly a thousand (997) examples, the quality (by chrF metric) increases by 4.5% for Kurdish and 1.5% for Tamil compared to 1-shot mode. As a result, they surpassed production Google Translate and achieved new state-of-the-art (SoTA) for these languages.

This doesn't differ much from examples from the work on Gemini 1.5 (source), where the more you feed it parts of the Kalamang language textbook, the better it translates (see the example here).
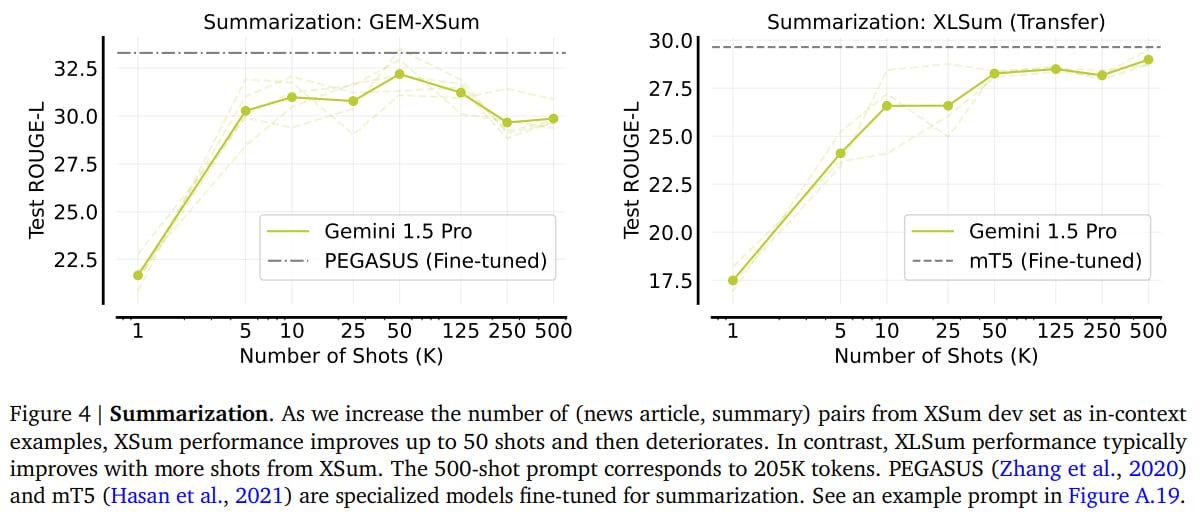
In abstractive summarization and evaluation on XSum, the final quality is quite close to specialized fine-tuned models (PEGASUS and mT5). On XSum, the quality increases up to about 50 examples, then deteriorates (the model starts inventing dates and times). On XLSum evaluation with in-context examples from XSum, quality increases monotonically up to 500 examples, indicating a positive transfer.
In generating logistic plans (they created a dataset with tasks involving 2-3 cities, 1-2 packages, one truck, and one plane per city), there is a significant improvement up to ten examples, then a slight one up to 400, and a jump at 800. It's far from specialized planners, but the result is interesting.

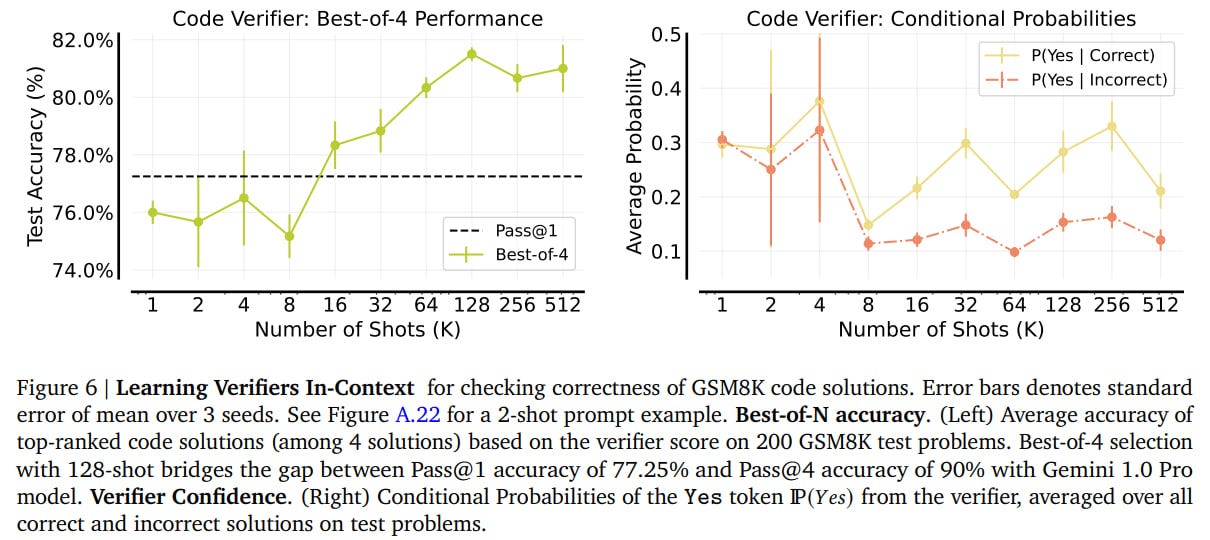
They also tried creating an LLM-verifier for predicting the correctness of solutions from GSM8K. With 16 and more examples, best-of-4 begins to surpass pass@1.
The issue with such many-shot ICL is that gathering a lot of good human examples can be difficult, for example, for tasks with complex reasoning like GPQA (Google-Proof Q&A Benchmark, source). The authors proposed two approaches that might help.
Modified ICL
Reinforced ICL generates explanations through a chain-of-thought prompt and retains only those that yield the correct answer. There might be issues with false positives when an incorrect reasoning leads to the right result.
Unsupervised ICL goes further and removes generated explanations, leaving only examples of tasks without answers. In this case, the prompt consists of three parts: 1) a preamble such as "You will be provided questions similar to the ones below:", 2) a list of tasks without solutions, and 3) zero-shot instructions or a few-shot prompt with the desired answer format.
They tested these methods on the MATH dataset. Both reinforced and unsupervised ICL beat ICL with ground-truth solutions. Interestingly, the method with only tasks works well, probably because the model had learned such tasks during pretraining. Moreover, prompts obtained on MATH lead to better solutions for GSM8K, particularly with Reinforced ICL.

For GPQA, there is an improvement up to 125 examples, then a decline. Unsupervised ICL behaves very differently, sometimes better, sometimes worse, and usually worse than Reinforced ICL. Claude-3 Opus is claimed as SoTA here (I just didn't understand if it's in zero-shot mode?), with the best from 125-shot approaching it.

They also tested on eight tasks from Big-Bench Hard. Reinforced ICL surpassed a human 3-shot CoT prompt on nearly all tasks, and overall quality monotonically increases with the number of examples.

Analysis
The work includes an analysis of model behavior in ICL mode as it transitions from few-shot to many-shot mode.
For instance, many-shot allows for the unlearning of biases from pretraining due to the multitude of examples. The work replicated a setting from another study where class labels were changed by rotation (['negative', 'neutral', 'positive'] to ['neutral', 'positive', 'negative']) or replaced with abstract ones (['A', 'B', 'C']). In few-shot mode, quality significantly drops compared to the original labels, but with the increase in the number of examples, it greatly improves and catches up. Model confidence also aligns.

On other non-linguistic tasks, abstract mathematical functions with numerical inputs need to be learned. The authors focused on parity functions and linear classification in high-dimensional space.
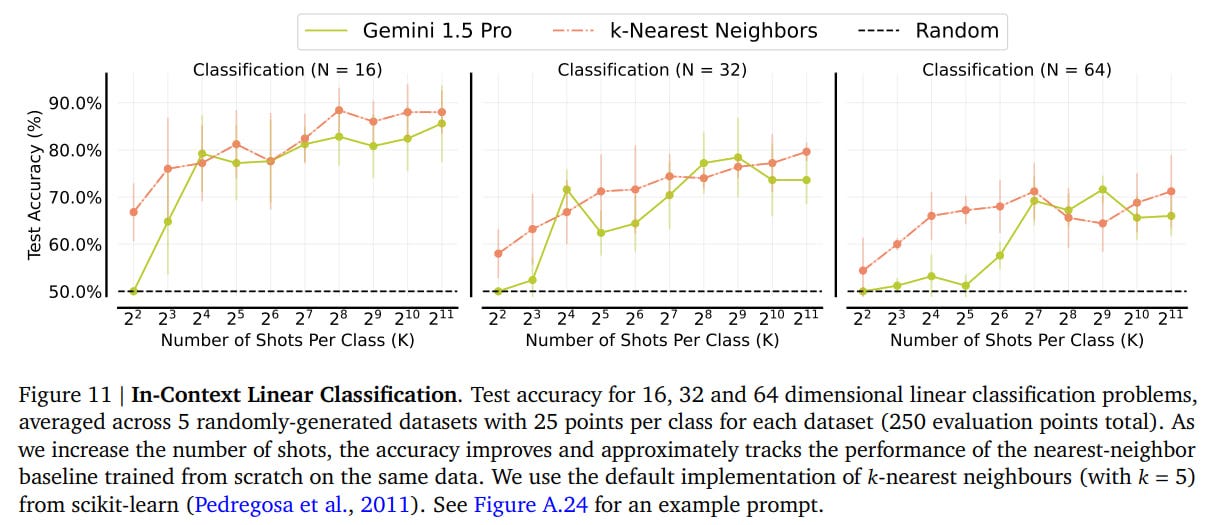
Classification approaches the baseline, kNN, with the number of examples increasing. Parity also significantly improves.

Among interesting observations is that the order of examples in the prompt matters a lot. And the best order on one task may not be the best on another.

They also studied how negative log-likelihood correlates with model performance in ICL mode. No significant results useful for predicting outcomes were found.

A remaining unclear question is why sometimes quality decreases as the number of examples increases.
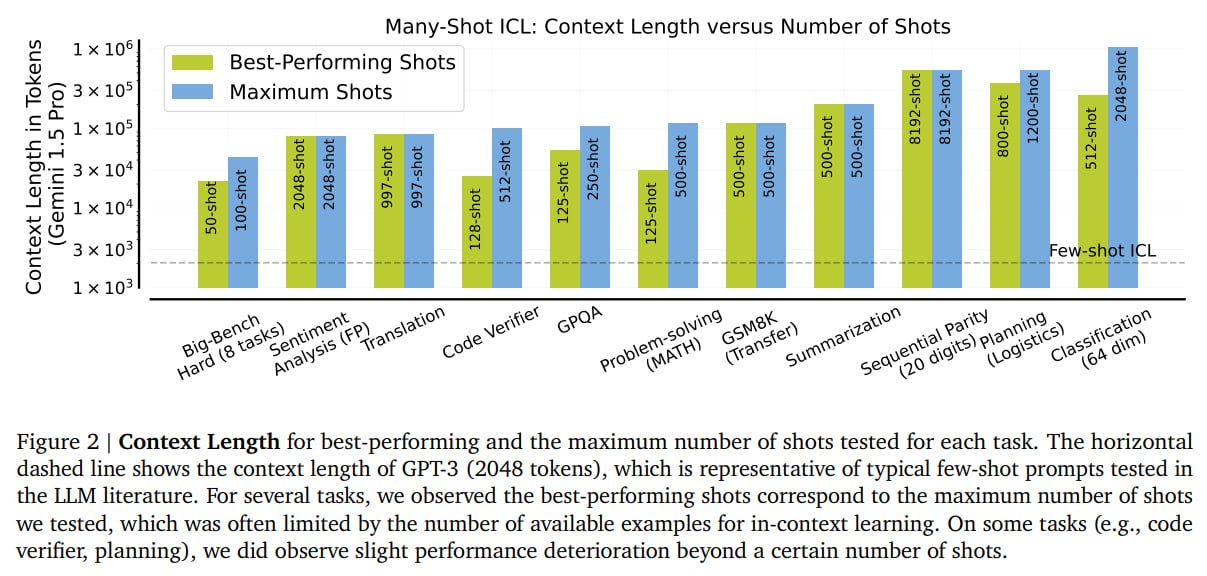
Such are the matters. On one hand, the result is expected; on the other hand, it's good that it's widely confirmed and substantiated. In real life, a lot will likely be determined by economics (how the costs of retraining compare against the costs of a large context) and performance (where you need to be closer to real-time, long contexts will lose out because they require more processing time—though many optimizations might emerge here). Possibly, this will be a good method for synthetic generation, where one-time costs are okay, and then you fine-tune another model. Reinforced ICL and Unsupervised ICL might also be useful somewhere.
In any case, ICL provides additional flexibility and universality, which should pave the way for new applications of models.