
Chronos: Learning the Language of Time Series
Pretrained Language Models for Probabilistic Time Series Forecasting

Authors: Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, Yuyang Wang
Paper: https://arxiv.org/abs/2403.07815
Code & Models: https://github.com/amazon-science/chronos-forecasting
TLDR: Chronos is a pre-trained transformer-based language model for time series, representing the series as a sequence of tokens. It builds on the T5 architecture and varies in size from 20M to 710M parameters.
Time series forecasting
Time series is a vast and intriguing area. While less prolific than fields like NLP or CV, it regularly features new works. Previously, RNNs were highly popular (with a resurgence now through SSMs), and even before that, models like ARIMA were common. Facebook’s Prophet library is another well-known example. There have been many approaches with specialized architectures, such as Temporal Convolutional Networks (TCN) used for weather forecasting and beyond, or the transformer-like Informer. Surely, there’s much more.
In the past couple of years, there have been numerous attempts to apply large language models (LLMs) in various forms, from straightforward applications through GPT-3, Time-LLM, and PromptCast, to more specialized ones like Lag-Llama or TimesFM, among many others.
There is a recent review on the topic.
This current work takes a step back from LLMs and introduces modifications specific to time series. These changes are focused mainly around tokenization and training augmentations.
Enter Chronos
Chronos is essentially a framework for adapting LLMs to probabilistic time series prediction. The aim is to achieve this with minimal modifications.
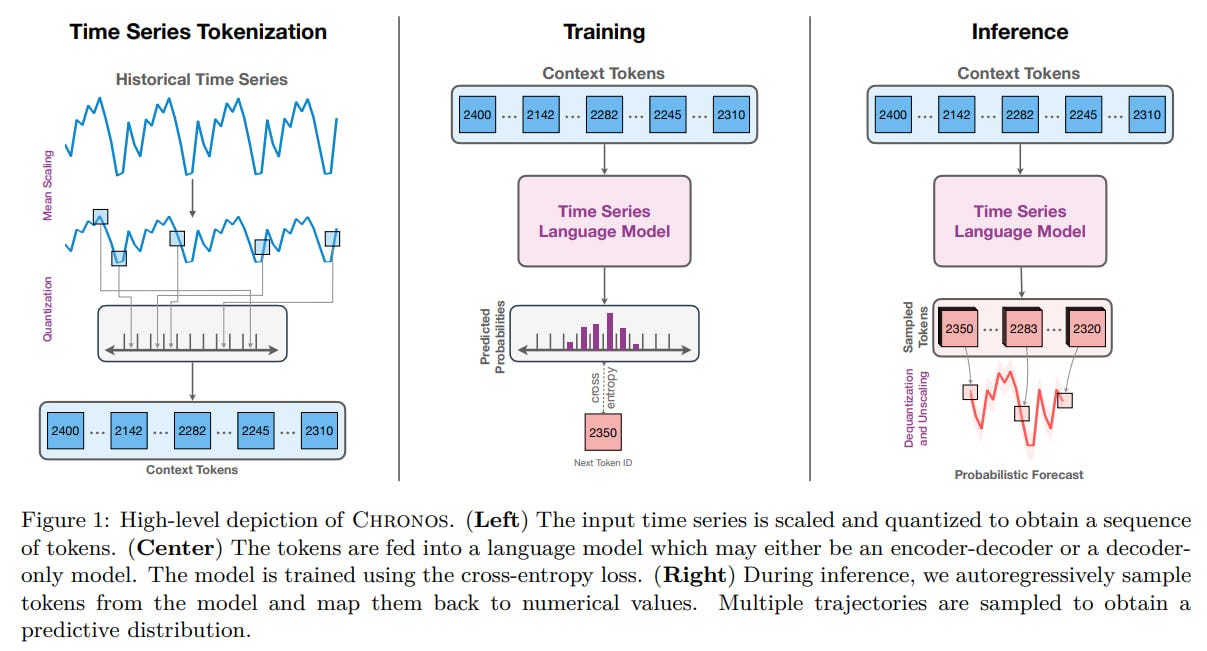
One obvious issue is that time series usually consist of real numbers, not tokens from a finite vocabulary. Thus, to work with LLMs, the series must be tokenized. This involves initially scaling the series (dividing by the mean, though other schemes are possible) and then quantizing it into B bins (using B = 4094), with the center of each bin returned during de-quantization. Bins can be uniformly distributed or data-dependent. In addition to the B temporal tokens, two special tokens, PAD (for missing values and padding) and EOS (for the end of the sequence), are added. No additional information (such as time or frequency) is included in the data.
The focus is primarily on the T5 encoder-decoder, although purely decoder-based models like GPT-2 are also experimentally explored. The target function is standard cross-entropy for predicting the quantized token. It's important to note that this approach effectively does regression through classification, and this function does not account for the proximity of adjacent bins. The benefit here is that the architecture or training procedure of LLMs does not change, allowing the use of off-the-shelf code. This also does not impose any restrictions on the output distribution, which can vary between datasets from different domains.
The model predicts using a typical autoregressive method: sampling the next token, de-quantizing it, and scaling it back.
Data
For training time series models, there isn't as much quality data as there is for NLP. Therefore, the authors actively used synthetic data through mixup augmentation in addition to real data.
Mixup was used for images, creating a synthetic picture through the weighted combination of two real ones. The authors proposed TSMix, extending Mixup to more than two points—here, a weighted combination of k sequences. Weights are sampled from a symmetric Dirichlet distribution, Dir(α).


In addition to TSMix, KernelSynth is used, generating artificial data through Gaussian processes, where a library of kernels (linear kernel for trend, RBF for smooth local changes, periodic kernels for seasonal trends) is specified. Kernels are sampled (with replacement) from the library and combined through addition or multiplication. The final kernel is used to generate a sequence of a given length.
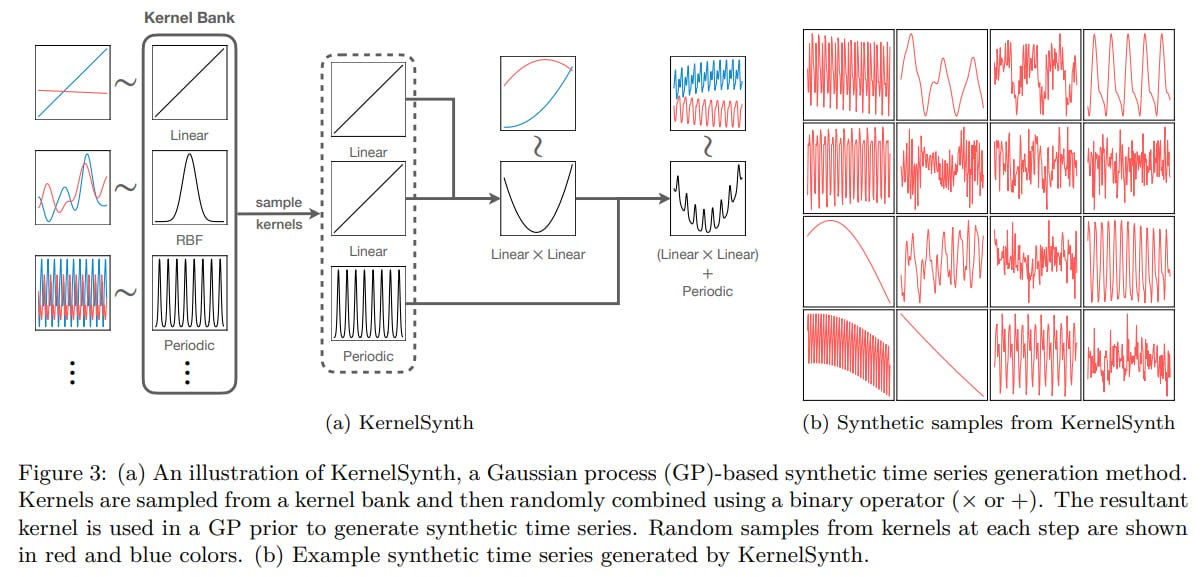

Many datasets (a total of 55) of various natures were collected. Some are used for training, others for evaluation.

There is a detailed list in the Table 2 of the paper.
Models and baselines
Models of T5 in four sizes (there’s also a fifth Tiny one at 8M in the repo) were trained: Mini (20M), Small (46M), Base (200M), and Large (710M), plus a GPT-2 base (90M).
They were trained on 10M TSMix augmentations from 28 training datasets and 1M synthetic sequences generated through Gaussian processes. They are mixed in a 9:1 ratio. Original data was included in TSMix with a probability of ⅓.
The training batch was 256 sequences. The context size for the models is 512, with a prediction length of 64. They trained for 200K steps using AdamW. This is one of the first works where I see a report on the real cost of training, from about $250 and ~8 hours on a p4d.24xlarge (8xA100 40GB) for the mini model to $2066 and 63 hours for the large.

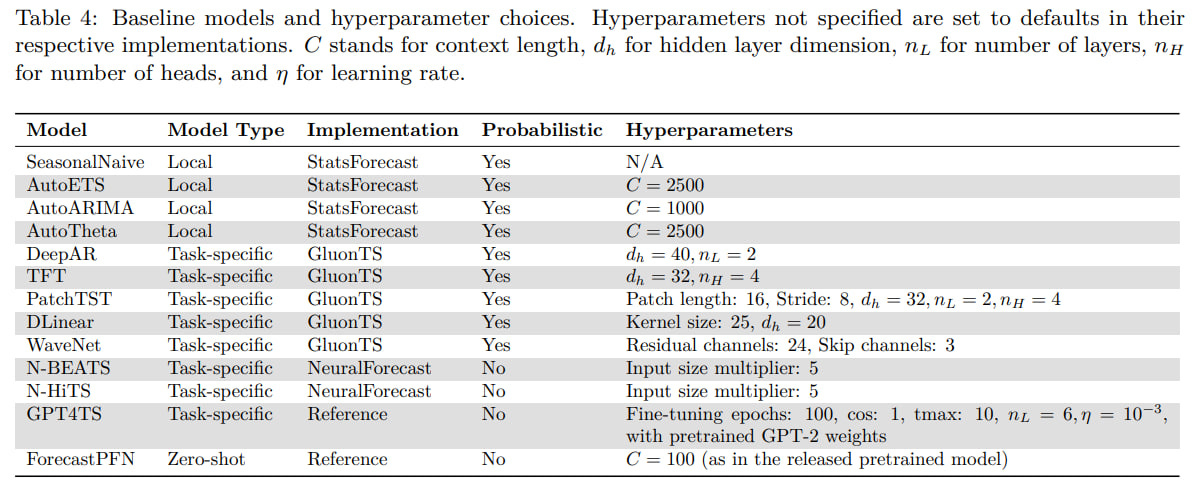
Many baselines were compared, both statistical and neural network-based. The baselines were divided into groups:
Local models, estimating parameters for each sequence individually
Task-specific models, trained (or fine-tuned) for each task separately
Pretrained models without task-specific fine-tuning, one model for everything.
Evaluation
They evaluated both probabilistic (weighted quantile loss, WQL) and point predictions (mean absolute scaled error, MASE).
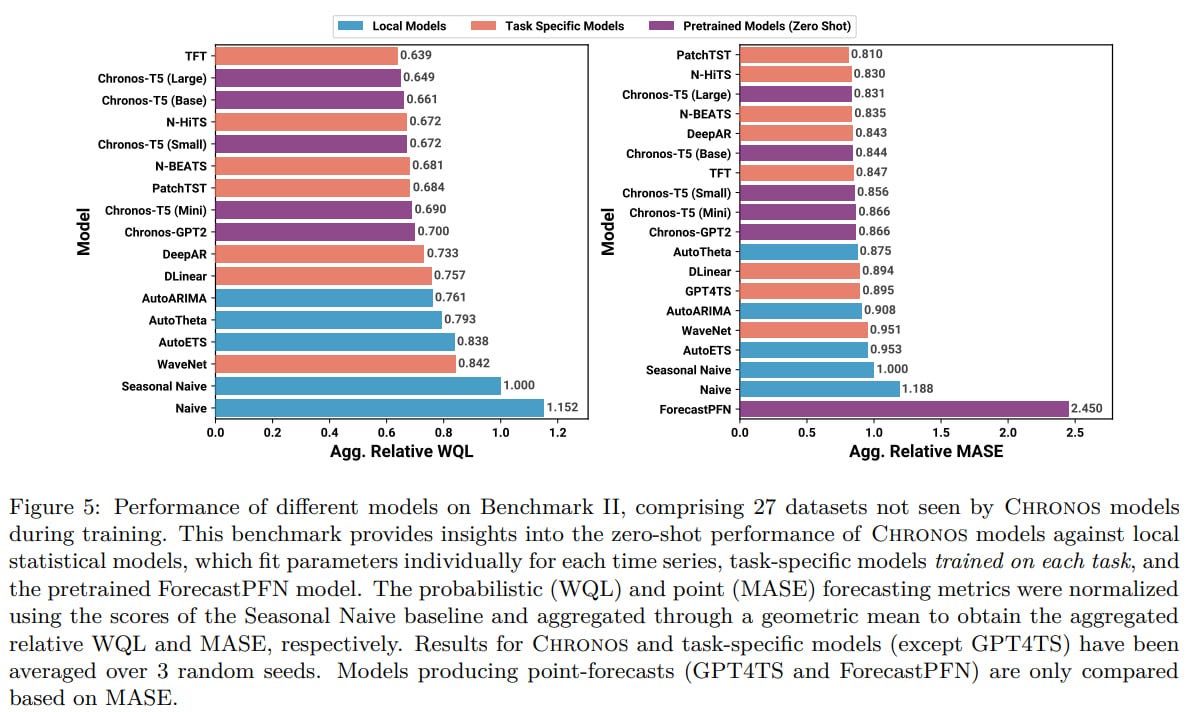
A total of 42 datasets were assessed, divided into Benchmark I (In-domain, 15 datasets) and Benchmark II (Zero-shot, 27 datasets).
Chronos performs very well in-domain, not only better than local models but also better than task-specific ones.

In zero-shot as well, it's very good, placing 2nd or 3rd. It beats models that have seen these tasks during training. This is really cool for zero-shot, when the model hasn't seen anything like it before.
And if you fine-tune it on these tasks, it's even better, better than the rest.

Interestingly, the decoder-only Chronos GPT-2 with 90M parameters consistently falls slightly behind the encoder-decoder models Small (46M) and Mini (20M).
From the loss curves and metrics, even larger models will likely improve results.

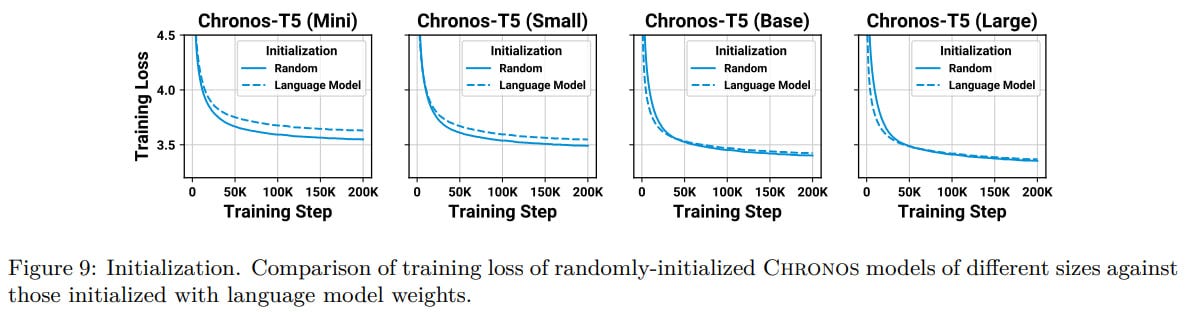
Random initialization slightly outperforms starting from pretrained (on the C4 dataset) weights.
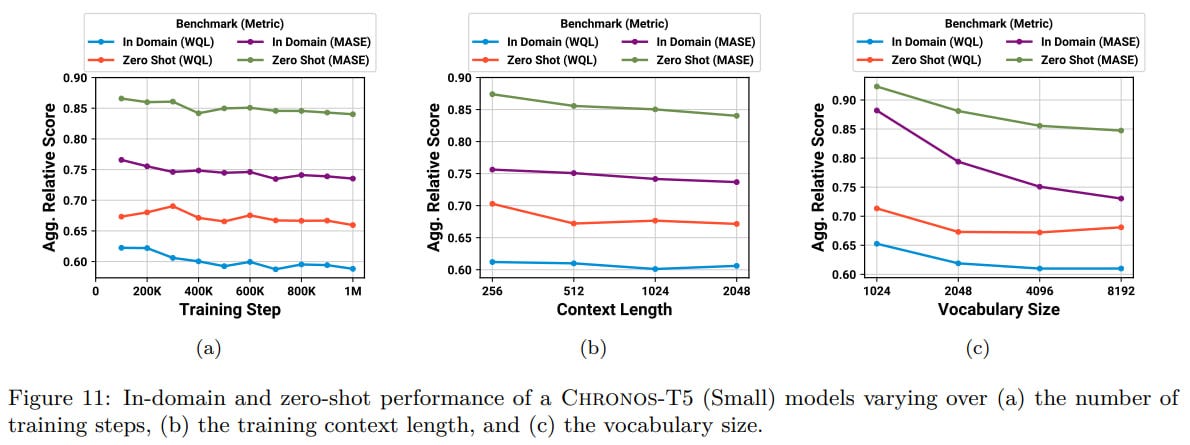
TSMix + KernelSynth in training is better than without one or both, especially on zero-shot.

With an increasing context, the model predicts better. Increasing the vocabulary size also helps.
The model predicts various patterns well: noise process, trend, seasonality, combined pattern, AR process.
There might be a loss in precision due to quantization or scaling (e.g., on sparse data with low mean but outliers, or on heavily shifted data with low variance), but on real data, the model performs well.


There are limitations: the model focuses on univariate time series and doesn't take any additional information that might be available into account. Also, a separate issue is inference speed. Here, Chronos significantly loses out to specialized lightweight models. But there's no need to deploy countless separate models if something comes up.

Overall, it's an interesting model, worth trying on a real task. It looks useful. It's great that any fresh architectural developments from NLP can be easily transferred here, as no architectural changes are needed. It's also interesting to see what's valuable in the learned representations and where they might be useful.