

TextGrad: Automatic "Differentiation" via Text
TextGrad: Automatic "Differentiation" via Text
"Backprop" for multi-agent systems!

Authors: Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, James Zou
Article: https://arxiv.org/abs/2406.07496
Code: https://github.com/zou-group/textgrad
We've become very good at training large networks or differentiable combinations of networks through backpropagation. However, with the evolution of LLMs, multi-agent systems now consist of combinations of LLMs and tools that do not form a differentiable chain. The nodes of such a computational graph (the LLMs and tools) are connected via natural language interfaces (communicating through text) and often belong to different vendors residing in different data centers, accessible only through APIs. This means that backpropagation is no longer applicable. Or is it?
Enter TextGrad!
Internals
TextGrad essentially implements an analogue of backpropagation, but through text and with text-based gradients. What does this look like?
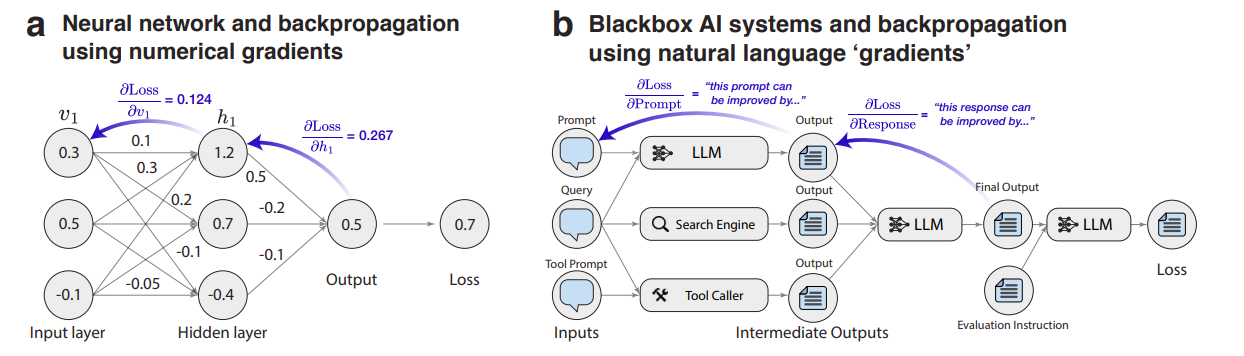
Let's consider a simple example. There are two LLM calls, and we want to optimize the prompt in the first call:
Prediction = LLM(Prompt + Question) (1)
Evaluation = LLM(Evaluation Instruction + Prediction) (2)
For this chain, we can assemble an analogue of backpropagation using the gradient operator ∇LLM, assuming LLM was called in the forward pass. This operator itself is based on an LLM and generally resembles the Reflexion pattern (see the Pattern Catalogue), returning feedback (criticism, reflection) on how to modify a variable to improve the final objective. It outputs something like ‘This prediction can be improved by...’
Inside ∇LLM, we show the "forward pass of the LLM" through a prompt like "Here is a conversation with an LLM: {x|y}", then insert criticism (the previous gradient operator in the chain) "Below are the criticisms on {y}: {∂L/∂y}" and finally "Explain how to improve {x}."
In the example with two calls, we first compute
∂Evaluation/∂Prediction = ∇LLM(Prediction, Evaluation),
meaning we get instructions on how to change the variable Prediction to improve Evaluation.
Then, we find out how to change the Prompt through
∂Evaluation/∂Prompt =
∂Evaluation/∂Prediction * ∂Prediction/∂Prompt =
∇LLM(Prompt, Prediction, ∂Evaluation/∂Prediction).
This forms the basis of a gradient optimizer called Textual Gradient Descent (TGD), which works on the principle:
Prompt_new = TGD.step(Prompt, ∂Evaluation/∂Prompt).
The TGD.step(x, ∂L/∂x) optimizer is also implemented via an LLM and essentially set by a prompt like “Below are the criticisms on {x}: {∂L/∂x}. Incorporate the criticisms and produce a new variable” yielding a new variable value (in our case, Prompt).
In reality, the operators' prompts are more elaborate (and perhaps could be found using textual gradient descent, but apparently not).

In general, the computation can be more complex and defined by an arbitrary computational graph where nodes can involve calls to both LLMs, tools or numerical simulators as transformations. If a node has multiple successors, all gradients from them are collected and aggregated before proceeding.
There's still the question of the objective function, which for backpropagation is something differentiable, like L2-loss or cross-entropy. Here, it can be non-differentiable and described in human language, computed via an LLM call with a prompt. For example, for code, it might look like this:
Loss(code, target goal) =
LLM(“Here is a code snippet: {code}. Here is the goal for this snippet: {target goal}. Evaluate the snippet for correctness and runtime complexity.”
This is quite universal and flexible. A natural language loss function is cool.
Experiments
The work explores two classes of tasks: instance optimization (finding a solution to a problem, a piece of code, or a molecule, for example) and prompt optimization (finding a prompt that improves results across multiple requests for a specific task).
This approach can also implement batch optimization (with loss aggregation across the batch), optimization with constraints (e.g., requiring a specific response format), and momentum-like optimization (where the optimizer sees previous iterations).
The authors tested it on several task classes: Coding, Problem Solving, Reasoning, Chemistry, Medicine.
Coding tasks: Generate code solving problems from LeetCode Hard.
The setup looks like this:Code-Refinement Objective = LLM(Problem + Code + Test-time Instruction + Local Test Results), where the Code in bold is optimized through TextGrad.

Result: 36% Completion Rate.
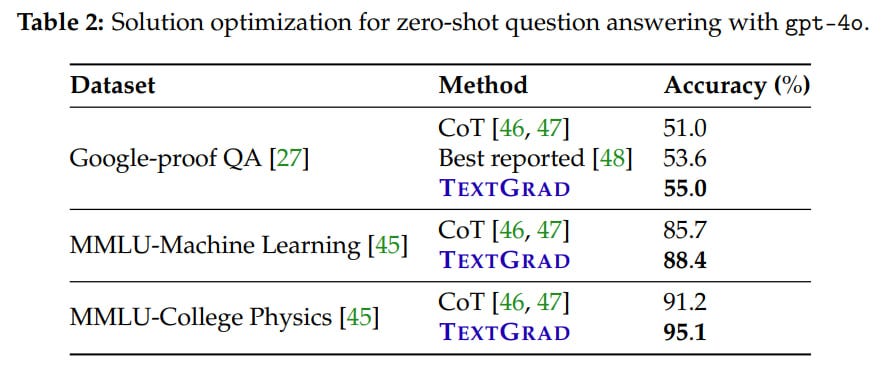
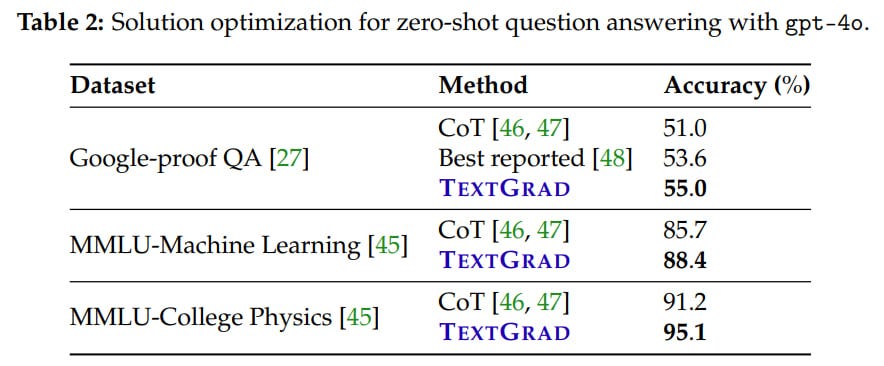
Solution optimization: Improve the solution to a complex problem from Google-proof Question Answering (GPQA), e.g., a question from quantum mechanics or organic chemistry.
The task is set as follows:Solution Refinement Objective = LLM(Question + Solution + Test-time Instruction)


TextGrad performed three iterations of solution updates followed by majority voting. Achieved 55%, the best-known result at the time. In MMLU with physics or ML, the result is higher than with CoT.
Prompt optimization for reasoning on Big Bench Hard and GSM8k tasks:
Answer = LLM(Prompt, Question)
Evaluation Metric = Evaluator(Answer, Ground Truth)
They optimized the prompt for the cheaper gpt-3.5-turbo-0125 model through feedback from the more powerful gpt-4o. Mini-batches of size 3 and 12 iterations were used, meaning the model saw 36 training examples. The prompt was updated if the validation result improved.
Result: Outperformed Zero-shot Chain-of-Thought and DSPy.
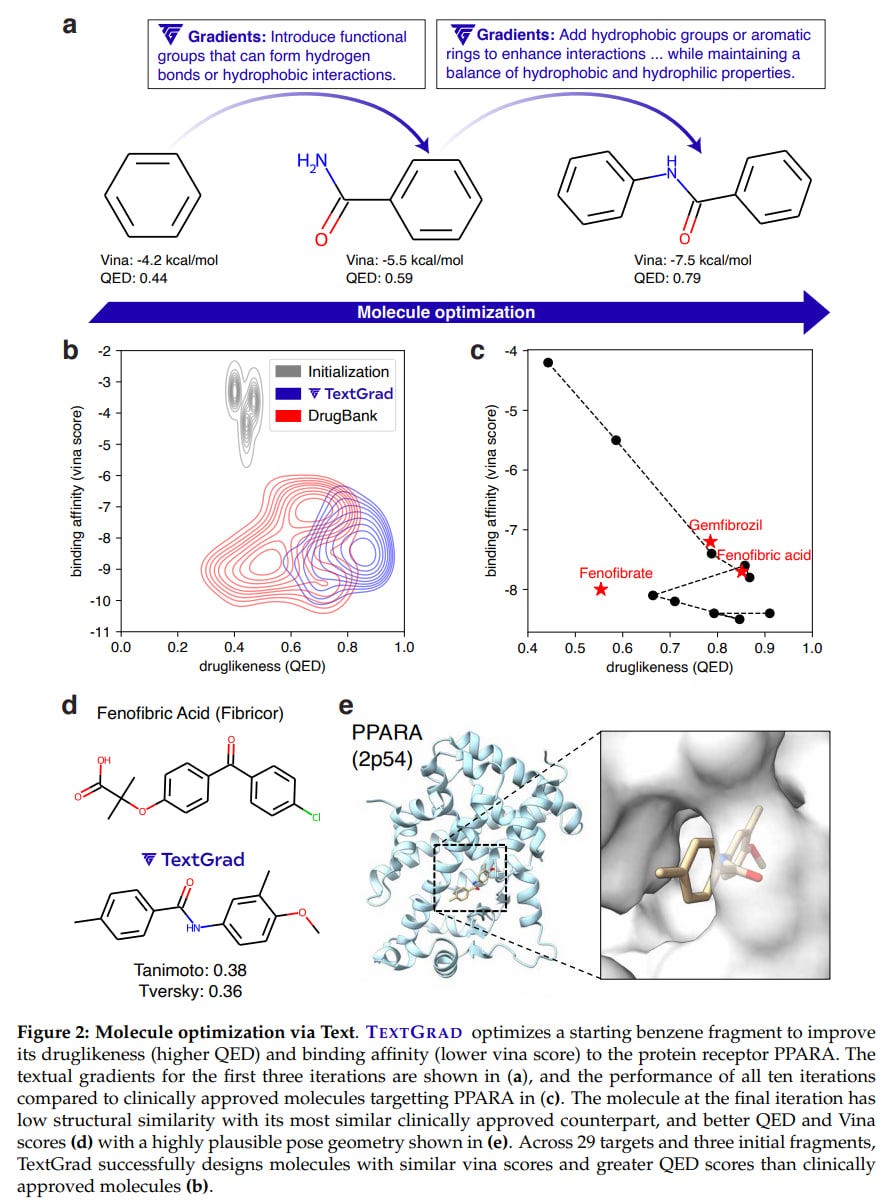
Molecule optimization: Given by SMILES notation with affinity scores from the Autodock Vina tool and druglikeness through Quantitative Estimate of Druglikeness (QED) score from RDKit, i.e., a multi-objective loss:
Evaluation = LLM((Affinity(SMILES_i, target), Druglikeness(SMILES_i))
SMILES_{i+1} = TGD.step (SMILES_i, ∂Evaluation/∂SMILES_i)
The molecule was initialized with a small fragment from a functional group, and gpt-4o was used as the LLM. TextGrad was applied to 58 targets from the DOCKSTRING benchmark.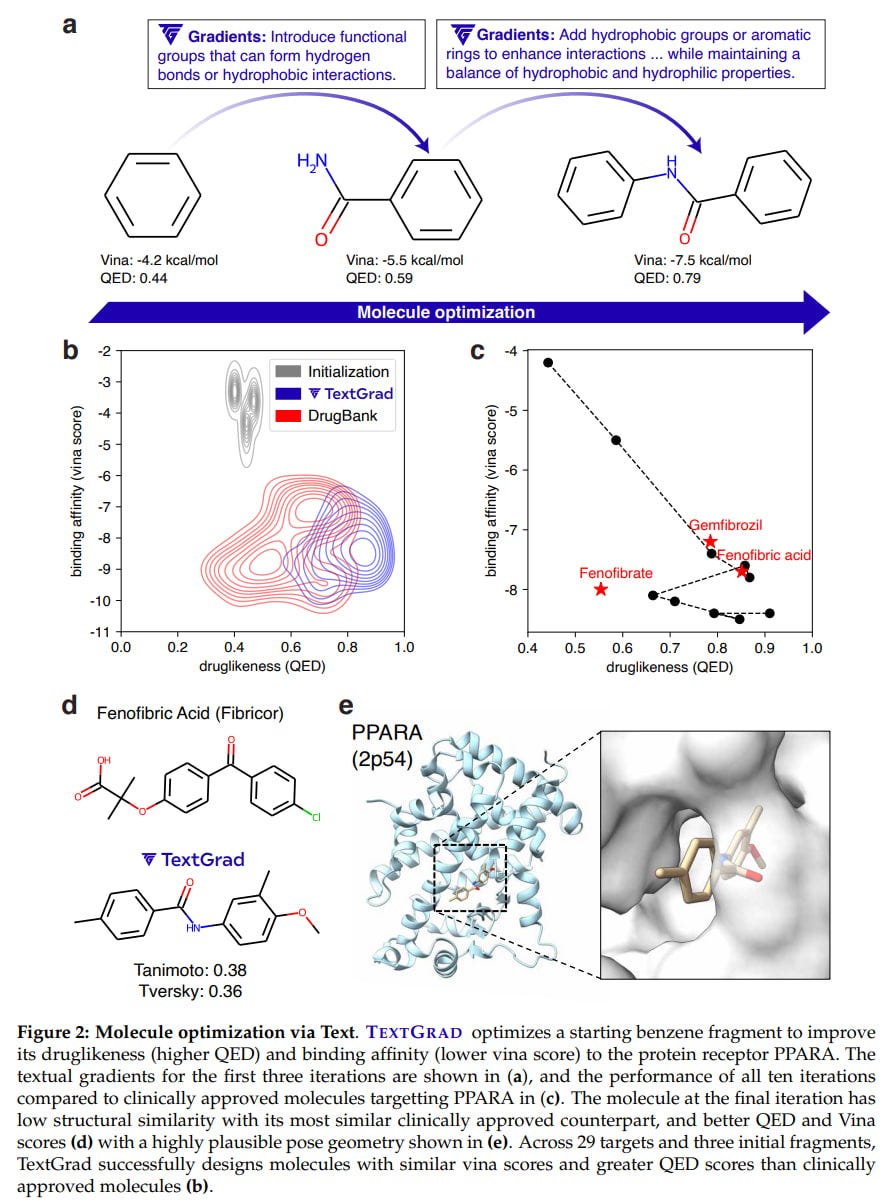
Result: TextGrad significantly improved results at each step, and the final molecules were quite commendable. As a benefit, cheminformatics tools can be used, and the pproach also produces explainable solutions.
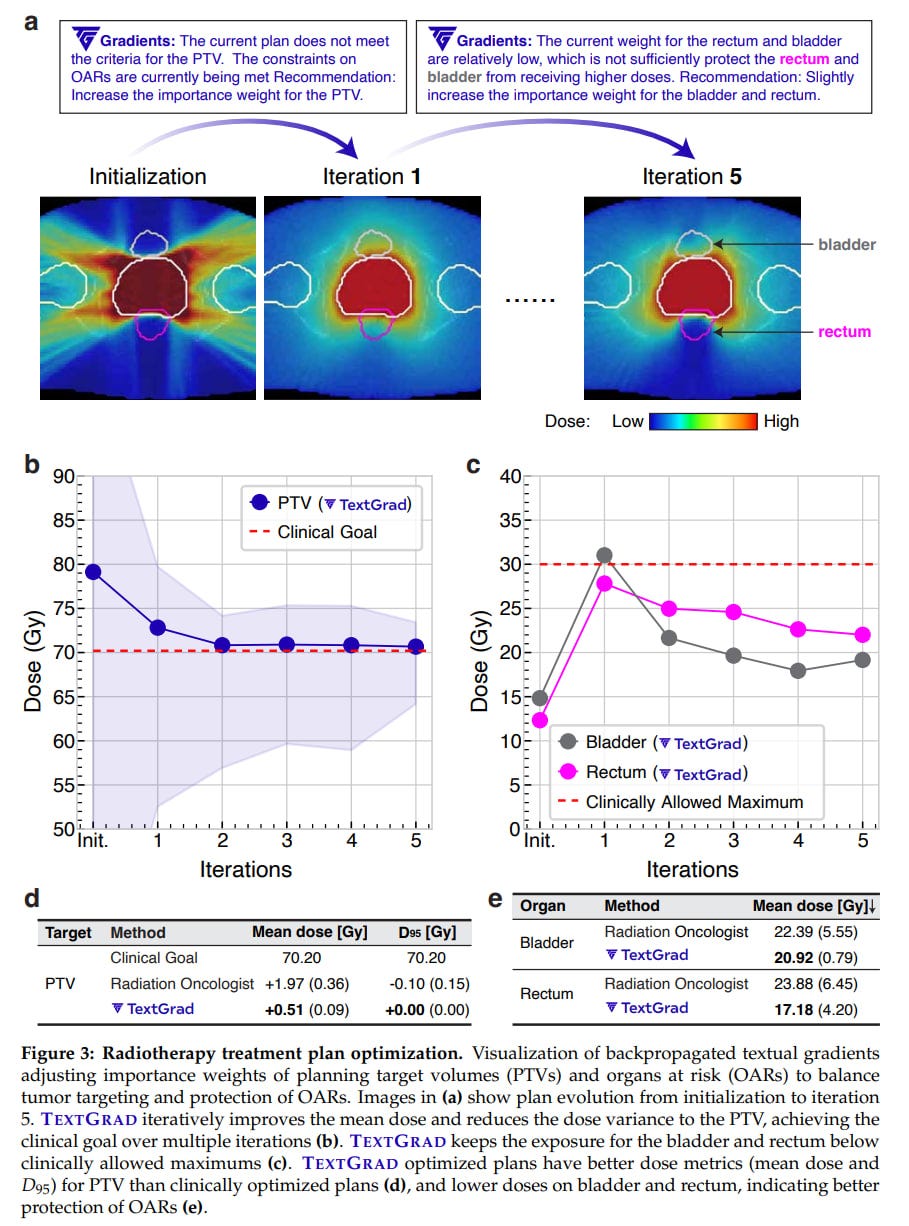
Radiotherapy plan optimization: A task with two nested cycles, optimizing the outer hyperparameters for the inner one. Hyperparameters θ were set by a string.
Loss for treatment plan P looked like this:
L = LLM(P(θ), g), where g represents clinical goals.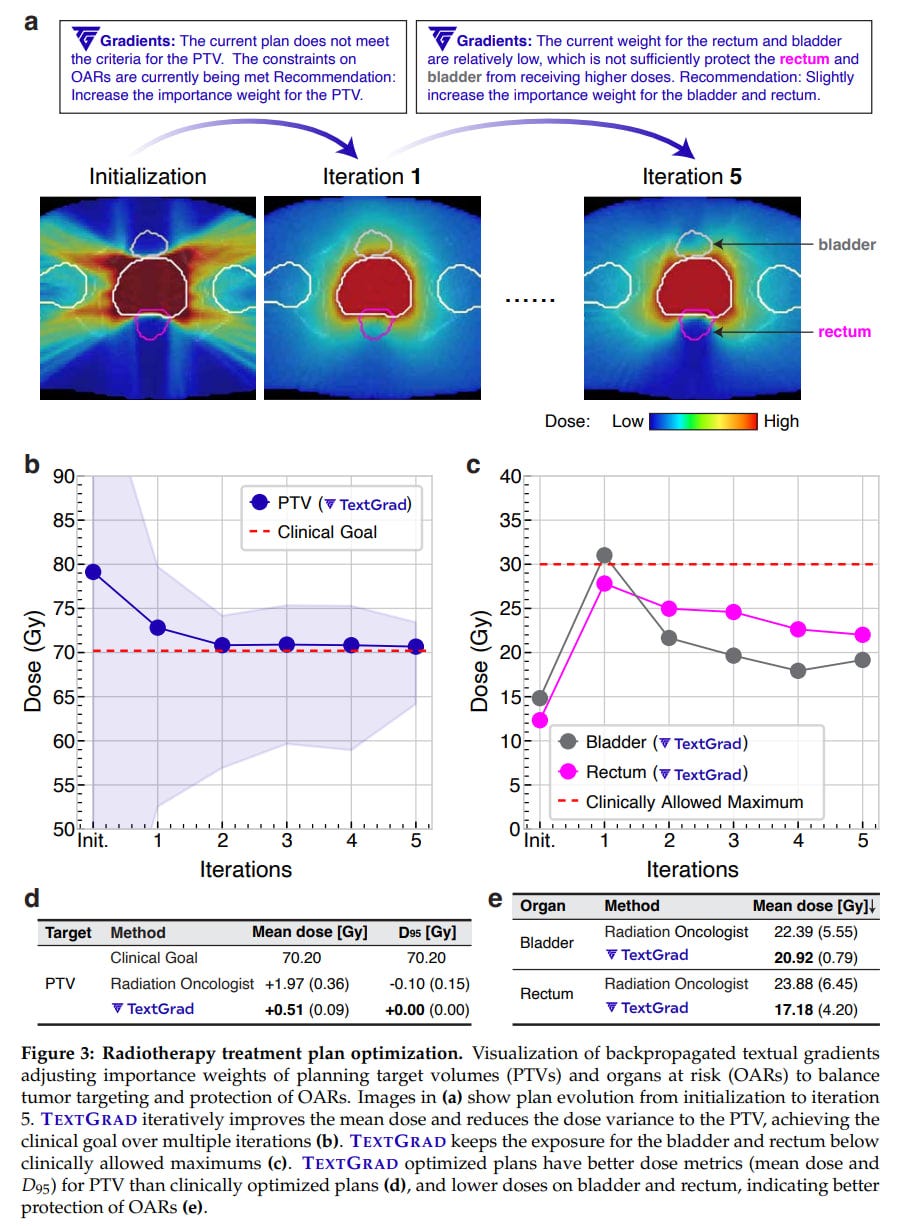
The result seems meaningful as well.




This is an interesting approach, appearing quite universal and applicable. The authors have packaged this into a library (https://github.com/zou-group/textgrad) with an API similar to PyTorch. Loss computation, gradient calculation, and optimizer steps are indistinguishable from PyTorch.

I anticipate a big and exciting future 🙂 It would be interesting to see feedback in other modalities, such as images or sound, which could be quite funny. More seriously, further framework extensions for tools and RAG seem very promising.