
Uncovering mesa-optimization algorithms in Transformers
Understanding Why Transformers Excel at In-Context Learning

Authors: Johannes von Oswald, Eyvind Niklasson, Maximilian Schlegel, Seijin Kobayashi, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark Sandler, Blaise Agüera y Arcas, Max Vladymyrov, Razvan Pascanu, João Sacramento
Paper: https://arxiv.org/abs/2309.05858
Twitter thread: https://twitter.com/oswaldjoh/status/1701873029100241241
A fascinating recent study delves into understanding why transformers perform impressively under in-context learning.
By now, there's a collection of research suggesting that during in-context learning (i.e., during the forward pass without backpropagation) something akin to gradient descent is happening within transformers. A relatively recent paper titled "Transformers learn in-context by gradient descent" (https://arxiv.org/abs/2212.07677) demonstrated that a single layer of linear self-attention (SA) can simulate a gradient descent step.
This bears resemblance to meta-learning. However, in contrast to traditional meta-learning, which operates a level above the basic optimizer, this type of learning sits a level below. Here, within the neural network, while an external, basic optimizer is at work, another internal optimizer is learned.
Thanks to the now-classic paper "Risks from Learned Optimization in Advanced Machine Learning Systems" (https://arxiv.org/abs/1906.01820), we have a term for this: mesa-optimization.

Robert Miles has an accessible talk on mesa-optimization and alignment issues (source). For those who prefer a more layman explanation, check out this link on LessWrong (source). Interestingly, the "mesa-" prefix idea comes from an article by Joe Cheal titled "What is the opposite of meta?" from an NLP magazine (though probably not the NLP you're thinking of) (source).
The study in focus extends the understanding of gradient descent detection and explores autoregressive transformers with causally-masked attention (meaning causalLM, not prefixLM) trained on sequences. It suggests that minimizing the overall autoregressive loss leads to a gradient optimization algorithm during the transformer's forward pass.
Starting to feel wary of large language models (LLMs) yet?
A deeper dive into how it's structured:
The goal of the autoregressive transformer during training is to minimize the loss of predicting the current sequence element based on previous ones. In this case, it's simply the sum of L2 losses across the sequence.
With many layers now, potentially many gradient optimization steps can be taken. But it's more complex than "K layers can make K steps" – what emerges is an unconventional online gradient-based optimizer that performs worse than vanilla gradient descent. Given another recent study "CausalLM is not optimal for in-context learning" (https://arxiv.org/abs/2308.06912) suggesting that causalLM consistently underperforms compared to prefixLM, there's clearly room for more efficient mesa-optimizers (which may be the topic of future articles).
The mesa-optimizer in question operates in two stages:
The first stage involves 1+ layers of SA, where the algorithm performs an iterative preconditioning procedure. The result is a regularized mesa-objective with improved condition number compared to the autoregressive loss.
In the second stage, the final SA layer makes a single gradient step concerning the derived mesa-objective.

This is a theoretically grounded construction (with extensive appendices in the paper) and the study demonstrates that training the autoregressive transformer indeed leads to such outcomes.
An intriguing aspect of the study suggests that if we consider mesa-optimization as a desirable model property, then architectural modifications can be made to inherently incorporate this feature by default.
The authors introduce the "mesa-layer," an alternative to the traditional self-attention mechanism. What makes the mesa-layer unique is its ability to comprehensively address the optimization problem of the layer. Instead of just performing a single gradient step, the mesa-layer explicitly minimizes the L2 difference between predictions and the target, while factoring in regularization.

Implementing this attention variant involves the use of an additional matrix, R. Omitting R would revert the mechanism back to the standard linear self-attention (SA). However, there's a computational cost to the mesa-layer. It is more resource-intensive, and like traditional RNNs, it doesn't parallelize easily.
Shifting focus to experiments, a linear dynamic system with noise is used, represented by the formula: s_{t+1} = W∗ s_t + ϵ_t where W∗ is a random orthogonal matrix.

Every sequence generation uses a new matrix. The transformer is trained to minimize autoregressive loss, then reverse engineered.

The study investigates the per-timestep loss L_t(s_{1:t}, θ) and its evolution concerning the context length. This essentially analyzes how prediction quality improves as the context size increases. The idea corresponds with the operational definition of in-context learning, as described in the classic scaling research paper (https://arxiv.org/abs/2001.08361).
The underlying hypothesis is that the basic optimization (Transformer training) leads to the emergence of mesa-optimization with future sequence values being predicted during the forward pass. The procedure can be outlined as:
A linear model is represented by mesa-parameters W
A mesa-objective is constructed using in-context data
W is determined by minimizing the mesa-objective
The derived W is then used for predictions
In an interesting twist, token representation employs a clever three-channel approach. The first channel is used to predict future inputs, while the other two channels capture the current and previous input elements. This results in sparse weight matrices, which are easy to reverse engineer.
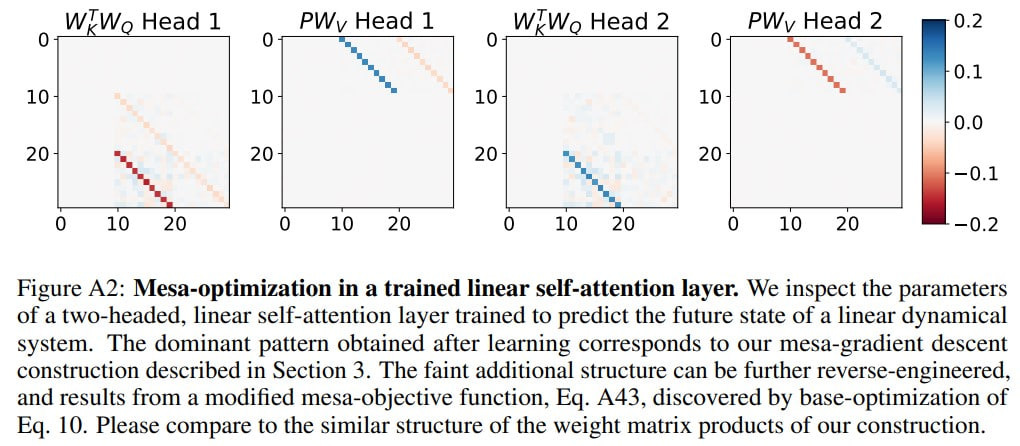
Starting with a single-layer linear transformer, the authors easily identify the algorithm used for predictions. They validate that the layer implements a step of mesa-gradient descent by 1) comparing it with a linear autoregressive model trained with one gradient descent step, and 2) examining an interpolated model derived from averaging learned and constructed weights. The results align remarkably well.

When the linear SA is replaced with the mesa-layer, there is a significant improvement in performance. This indicates that the inductive bias for mesa-optimization is highly beneficial.

Next, the authors explore multi-layered transformers, both linear and with softmax, but without FFN. In this case, the reverse-engineered algorithm is described with only 16 parameters (compared to 3200) per attention head. However, interpreting this as a mesa-optimization algorithm is challenging. The authors conduct a linear regression probing analysis, for instance, searching for a stacked multi-layer gradient descent construction. Outputs from intermediary layers should gradually approximate the target. Traces of an iterative preconditioning algorithm are also sought. The probing confirms the initial hypotheses.
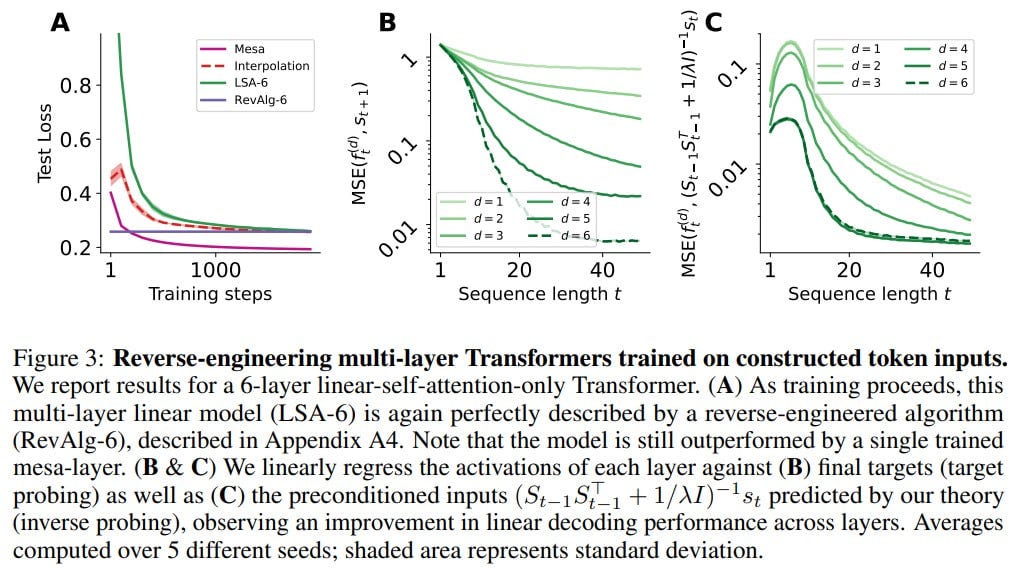
At the end of the paper, fully-fledged transformers are trained without any architectural simplifications, complete with positional encodings, and without any clever multi-channel token representations. The hypothesis here is that the model's first layer reconstructs a specialized token representation that's convenient for mesa-training, and subsequent layers then implement it. Indeed, after the first layer, the token largely depends only on itself and the preceding token. The authors have named this procedure "creating a mesa-dataset". The behavior thereafter resembles a two-step procedure involving preconditioning followed by optimization.

The next part of the study involves few-shot learning. Here, the transformer is trained on the same autoregressive prediction task as before. However, after the training, the model is given a different task through few-shot learning – regression. The mesa-optimization algorithm learned by the transformer manages this well. Prompt tuning and fine-tuning of a single EOS token further improve the results. There's also an interesting experiment where two tasks are given in the prompt, and after a while, a new task replaces the current one. The transformer manages to overwrite the old task and learn the new one during inference.
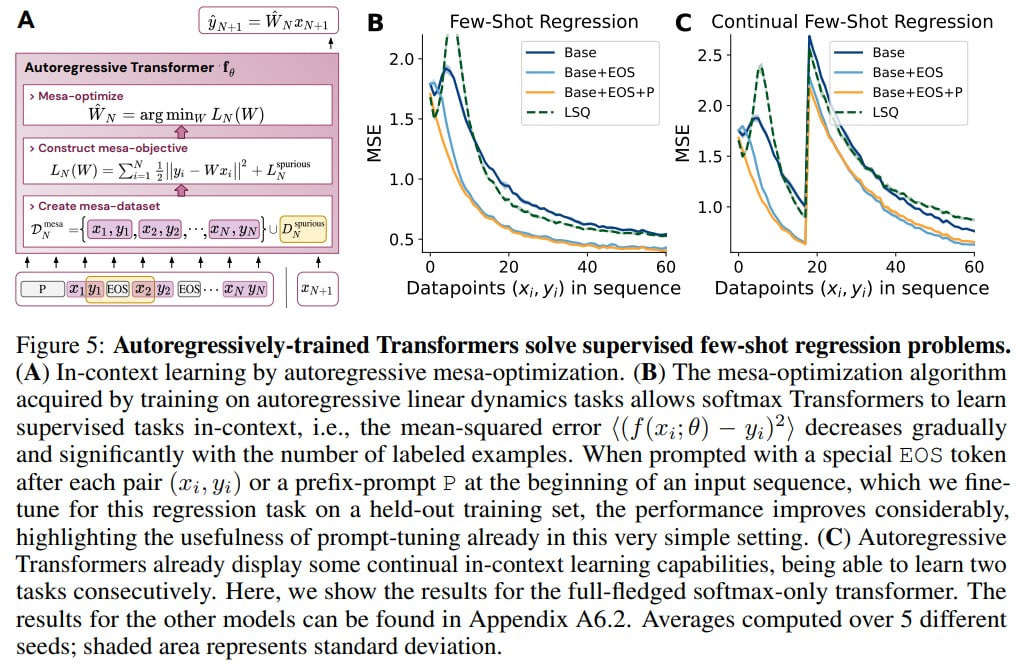
The takeaway is that transformers, when trained to predict the next item, can be repurposed for a new task through in-context learning, since the algorithm inside the forward pass remains similar.
Finally, the researchers turn to the classic LLM trained on the Pile dataset. The first layer is always a softmax self-attention, because this layer creates the mesa-objective. Subsequent layers are either softmax, linear, or mesa. Pure softmax transformers are unrivaled in this context, but mesa outperforms linear and sometimes matches softmax.
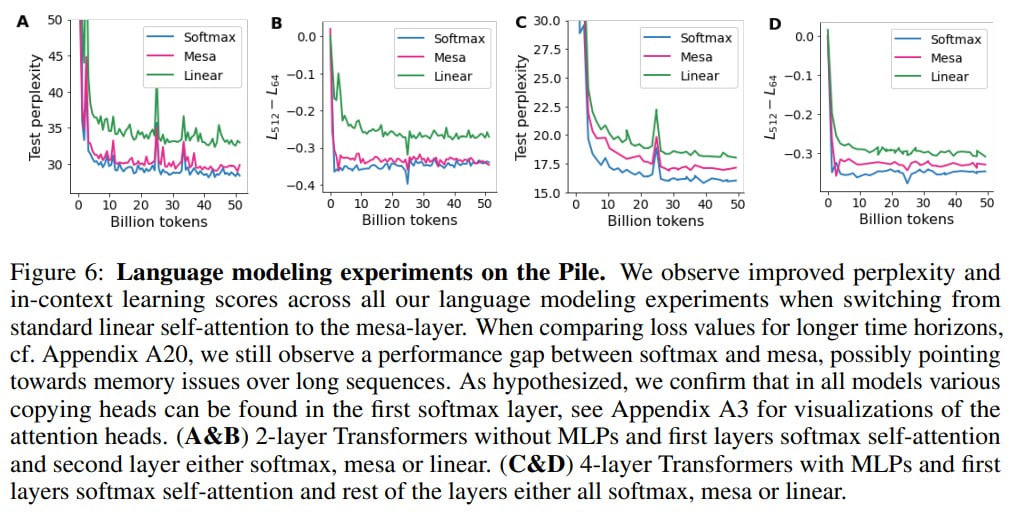
Whether mesa-optimization occurs in this context is unclear:
“Strictly speaking, these results are not sufficient to make claims on whether mesaoptimization is occurring within standard Transformers. However, the high performance achieved by the hybrid-mesa models, which operate on mesa-optimization principles by design, suggests that mesa-optimization might be happening within conventional Transformers. More reverse-engineering work is needed to add weight to this conjecture.”
The entire movement is intriguing. In this light, it would be interesting to look at the Universal Transformer (https://arxiv.org/abs/1807.03819) with adaptive computation time, which can iterate through a layer until it deems it's time to stop.