
ThoughtTerminator

This should be an April 1st paper, but no, it is real!

And I could not resist to ask another terminator to make a paper review. Honestly, a group of terminators. So, here’s an automated review:
This paper addresses the phenomenon of "overthinking" in large language models performing reasoning tasks. Overthinking is characterized by the generation of excessive, unnecessary tokens that do not improve task accuracy, coupled with poor calibration of token expenditure relative to problem difficulty, particularly on simpler questions. The research aims to quantify this inefficiency, evaluate model calibration across varying difficulty levels, and introduce a novel method to mitigate overthinking.
The authors make several contributions. They formalize observational metrics for overthinking based on the distribution of reasoning chain lengths. Specifically, they quantify problem difficulty D(q) as the expected inaccuracy rate across a set of models and define global overthinking Og(M) as the average difference between a model's typical token spend and the minimum observed spend across models, with a similar local measure Oenv(M).

The work empirically demonstrates a relationship between this definition of question difficulty and the optimal token spend.

Recognizing that existing benchmarks often focus on challenging tasks, the paper introduces the DUMB500 dataset (the name is really cool!), comprising 500 manually curated, straightforward questions across math, chat, code, and task domains, specifically designed to evaluate model behavior on easy problems.


The core contribution is THOUGHTTERMINATOR, a training-free, black-box decoding technique designed to reduce overthinking by dynamically managing token allocation based on estimated problem difficulty.
Methodologically, THOUGHTTERMINATOR operates during inference without requiring model retraining or gradient access. It functions within a "tool-use" paradigm, where the model might first estimate difficulty before invoking the process.

The method comprises three stages:
1) Scheduling: Estimating an optimal token budget ("deadline") for the input question based on its predicted difficulty. This difficulty estimate can come from various sources, including zero-shot prompting of another model (e.g., gpt-4o) or a separately trained predictor (e.g., a finetuned Llama-3-8B-Instruct). The predicted difficulty is converted into a token budget by referencing the average length of minimal successful answers observed for that difficulty level in a training set.
2) Running: The model generates tokens autoregressively. Periodically (e.g., every min(250, deadline/2) tokens), an "interrupt message" (e.g., "I have used {elapsed} tokens...") is inserted, reminding the model of its token usage and remaining budget. At each interrupt, a regex check is performed for the expected final answer format to allow for early stopping.
3) Terminating: If the deadline is reached before a formatted answer is detected, a termination prompt (e.g., "Time is up. Answer NOW") is issued, and constrained decoding is used with the same regex to extract a final answer from the generated text.
The novelty of this approach lies in its training-free nature and its focus on difficulty calibration for token budget control, distinguishing it from costly retraining methods or prior training-free techniques that might rely on specific probe phrases or white-box access. Its strength lies in its potential applicability to various black-box models. However, the method's effectiveness hinges on the accurate estimation of problem difficulty during the scheduling phase, which remains a challenge and may introduce dependencies on external models or require training a separate predictor. The formulation of interrupt and termination messages might also require careful prompt engineering. Furthermore, the metrics used for difficulty and overthinking are inherently model-dependent, although multi-model estimates are proposed.
Experimental results across datasets like MATH500, GPQA, ZebraLogic, and the new DUMB500 show that THOUGHTTERMINATOR significantly reduces token expenditure and computed overthinking scores compared to standard decoding baselines. For instance, local (Oenv) and global (Og) overthinking scores decreased substantially (82-98% and 76-91% respectively for evaluated reasoning models). Crucially, this efficiency gain was achieved while generally maintaining or even slightly improving task accuracy (Pass@10).
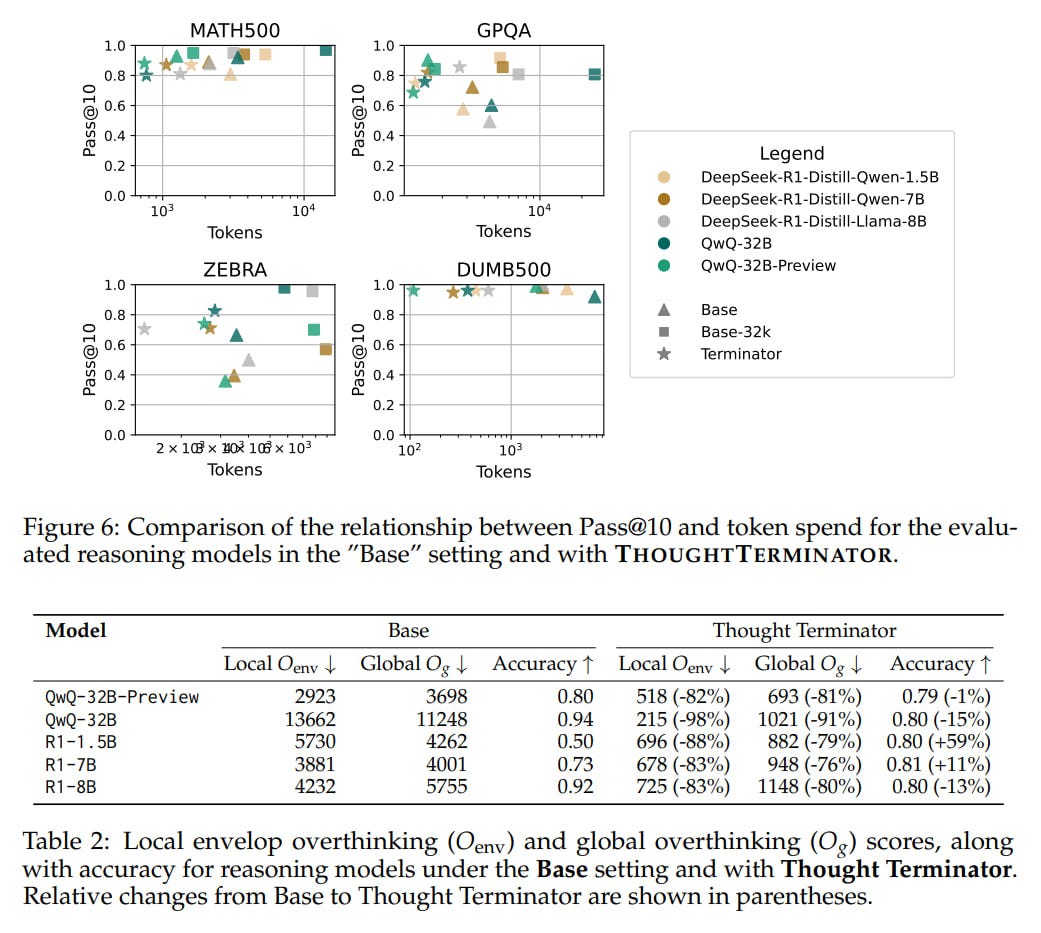
The calibration aspect is highlighted by results showing that using a trained difficulty predictor to set the token deadline achieves near-optimal Pass@10 performance with significant computational savings compared to fixed or poorly estimated deadlines. Ablation studies suggest the intermediate interrupt messages provide a benefit over simply terminating generation at the deadline. While the reported gains are substantial, the paper does not provide statistical significance tests (e.g., p-values or confidence intervals) for the results, making it difficult to gauge the robustness of these point estimates. The evaluation on the CHAT and TASK subsets of DUMB500 relies on LM-based judging, which carries potential biases.
The research holds potential significance for improving the computational efficiency of deploying large reasoning models, a critical factor as models scale. By providing a quantitative framework for overthinking and a practical, training-free mitigation strategy, this work offers a valuable tool for practitioners seeking to reduce inference costs without sacrificing performance. The introduction of DUMB500 also addresses a gap in evaluating model behavior on simpler tasks, where overthinking can be particularly pronounced.
However, the work has limitations. As mentioned, the reliance on accurate difficulty estimation is a key dependency. The DUMB500 dataset, while novel, is relatively small (500 examples) and its generalizability could be explored further. The lack of publicly released code or the DUMB500 dataset currently hinders reproducibility and broader adoption. Future work could explore more robust and model-agnostic difficulty estimation techniques, investigate adaptive strategies for scheduling interrupts, and expand the DUMB500 dataset. Releasing the implementation and dataset would significantly benefit the community.
Overall, this paper presents a valuable contribution to the study of inference efficiency in reasoning models. It clearly defines and measures the problem of overthinking, introduces a dedicated benchmark for simple tasks, and proposes THOUGHTTERMINATOR as a promising, practical technique for mitigation. While limitations exist, particularly around difficulty estimation and the lack of reported statistical significance or public artifacts, the demonstrated improvements in token efficiency warrant attention and further investigation.