
The Super Weight in Large Language Models
How a Single 'Super Weight' Can Break Your Billion-Parameter Model

Authors: Mengxia Yu, De Wang, Qi Shan, Colorado Reed, Alvin Wan
Paper: https://arxiv.org/abs/2411.07191
Code: https://github.com/mengxiayu/LLMSuperWeight
A fascinating study reveals that zeroing out a single weight inside an LLM can catastrophically degrade its performance. The authors call these critical parameters "super weights" and propose a method to find them in just one forward pass.
Trained LLMs contain a group of outlier weights with large magnitudes, comprising about 0.01% of all model weights - still hundreds of thousands in billion-parameter models. This was known before. The current work shows that within this group, there exists a single weight (the super weight, SW) - not necessarily the largest - whose importance exceeds the combined importance of thousands of other outliers. This weight is essential for quality; without it, LLMs cannot generate coherent text. Perplexity increases by several orders of magnitude, and zero-shot task accuracy drops to random when you zero it out.

Previously (https://arxiv.org/abs/2402.17762), researchers discovered super-activations critical for model quality. These appear in various layers, have constant magnitude, and are consistently found in the same position regardless of input. The current work finds that the activation channel aligns with that of the super weight, with the activation first appearing immediately after the super weight. Pruning this super weight significantly reduces the activation, suggesting the activation is caused by it rather than merely correlated. These activations are called super activations (SA).

Previous work explained super activations through bias terms but didn't explain their origin or consistent positioning. Now, the authors empirically found that before the down projection (down_proj), the Hadamard product of gate and up projections (gate_proj, up_proj) creates a relatively large activation. The super weight further amplifies this to create the super activation.
Recall that the MLP block in LLaMA looks like this:
out = down_proj( act_fn(gate_proj(input)) x up_proj(input) )
SW can be found by analyzing spikes in down_proj input and output distributions. This requires only one forward pass with a single prompt.

The authors found super weights in Llama (7B,13B,30B), Llama 2 (7B,13B), Mistral-7B, OLMo (1B,7B), and Phi-3.

Experiments zeroing SW, including restoring SA to original values, tested SW's influence on other activations. This recovers 42% of the loss, indicating SW's impact on quality extends beyond just SA.

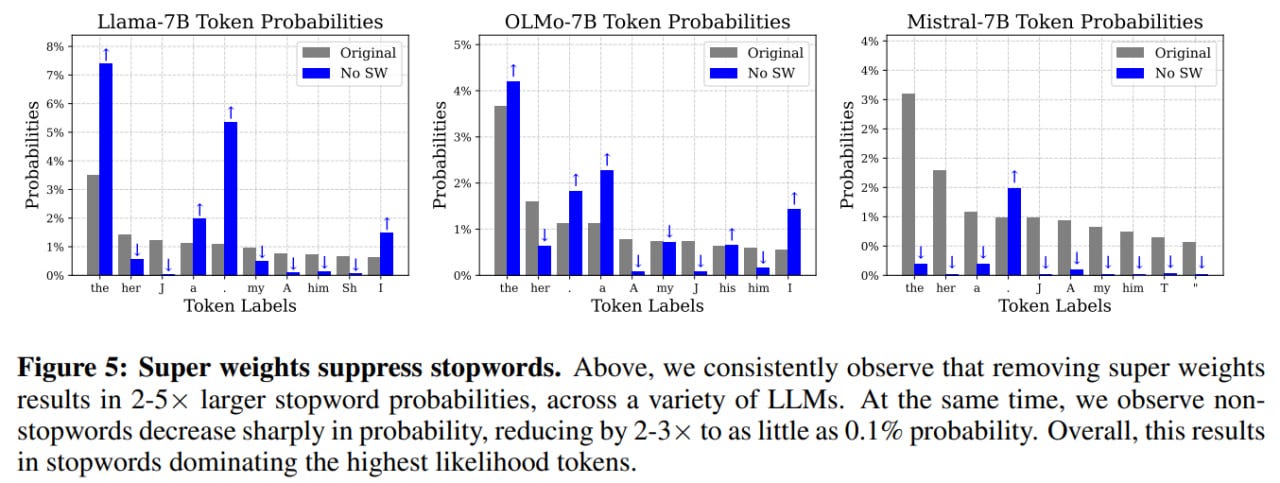
Analysis of 500 different prompts from the Lambada validation set shows that removing SW greatly increases stop-word probabilities (while decreasing regular word probabilities). For "the" it's 2×, for "." -- 5×, and for "," -- 10×. Thus, SW appears to suppress stop-words and enable meaningful text generation.

Another interesting experiment scales super weights with coefficients from 0 to 3 (where 1 is original operation) and shows that increasing SW slightly improves model quality - a surprising result.

This knowledge enables a special quantization method: Super-outlier aware quantization. Standard quantization mechanisms may be insufficient since outliers distort distribution, affecting step size and increasing quantization errors. Here, super outliers include both SW and SA. The proposed methods restore SW and SA after quantization with clipping and median value replacements.


This outperforms default methods - the key finding is that super weights must be protected. The paper includes detailed experimental analysis for those interested in diving deeper. The new method also loses less quality as block size increases.

Overall, an intriguing result. This somewhat echoes the lottery ticket hypothesis (https://arxiv.org/abs/1803.03635), where a highly sparse subnetwork was found within a large network that could achieve the original network's quality (or better) when trained. An interesting question remains: are super-weights part of the lottery ticket? I bet, yes.
How many super-weights do you think the human brain has?
Very interesting. I find it quite counter-intuitive.