
The convolution empire strikes back
ConvNets Match Vision Transformers at Scale

Authors: Samuel L. Smith, Andrew Brock, Leonard Berrada, Soham De
Paper: https://arxiv.org/abs/2310.16764
The empire strikes back for the second time (I’d say the first time was ConvNeXt).
There's a common perception that convolutional networks (ConvNets) perform well on small to medium-sized datasets, but when it comes to extremely large datasets, they fall short of transformers, particularly Vision Transformers (ViT) - more on this here. The latest research from DeepMind challenges this notion.
It has been believed that the scalability of transformers surpasses that of ConvNets, but there's scant evidence to back this up. Furthermore, many studies that delve into ViT compare them with relatively weak convolutional baselines, sometimes training with enormous computational budgets exceeding 500k TPU-v3 core hours. This equates to approximately $250k based on current on-demand prices. Such a budget is significantly beyond what's typically allocated for training convolutional networks.
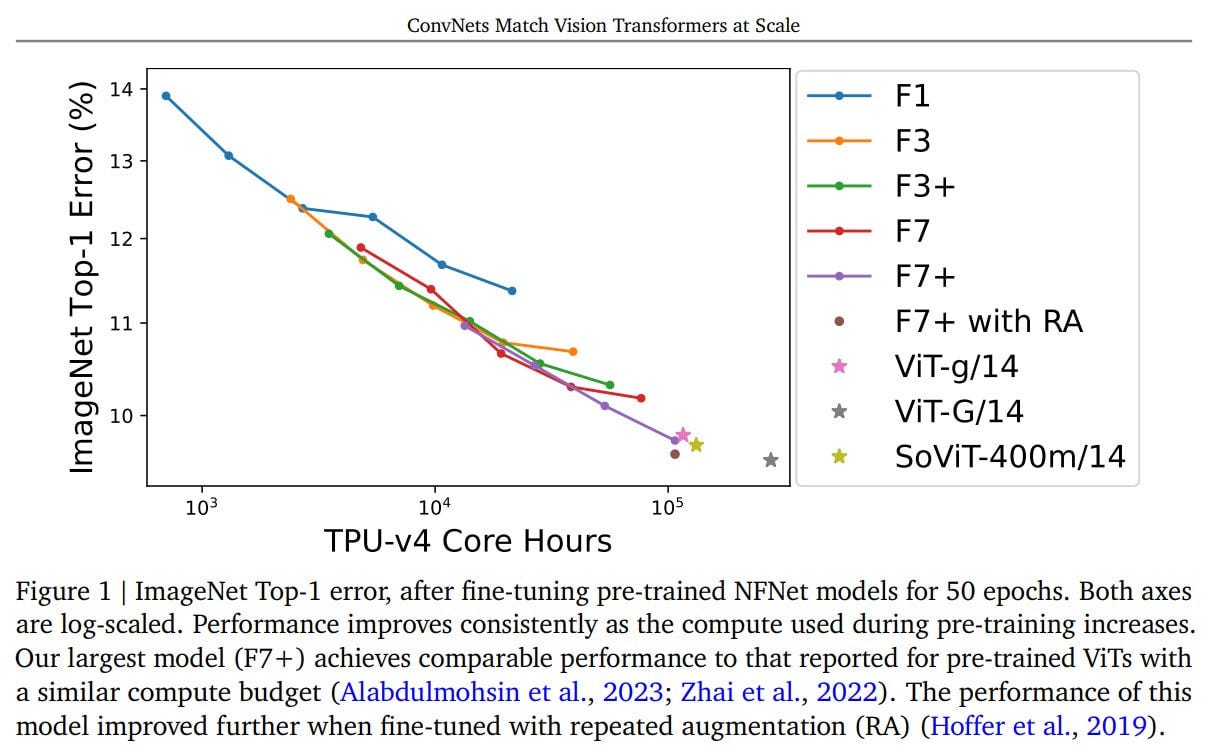
In this study, the authors utilize the NFNet (Normalizer-Free ResNets) family. They progressively increase the width and depth of these networks. This is a purely convolutional architecture and the latest of its kind to achieve state-of-the-art (SoTA) results on ImageNet.

Without major modifications (except for simple hyperparameter tuning), these architectures are pre-trained on the expansive JFT-4B dataset (with 4 billion labeled images across 30k classes) with computational budgets ranging from 0.4k to 110k TPU-v4 core compute hours. It's noteworthy that the TPU-v4 has about twice the computational power as the v3, but with the same memory capacity.
Subsequently, the pre-trained networks are fine-tuned on ImageNet using Sharpness-Aware Minimization (SAM). The results show performance on par with ViT models that have comparable budgets. All models consistently improve as computational power is added. The largest model, NFNet-F7+, is pre-trained over 8 epochs (110k TPU-v4 hrs), fine-tuned (1.6k TPU-v4 hrs), and achieves 90.3% top-1 accuracy (90.4% with 4x augmentation).
An interesting observation during the training process is the clear linear trend of the validation loss curve. This is consistent with the log-log scaling law between validation loss and the amount of computation during pre-training. This mirrors the same scaling laws observed for transformers in language modeling tasks. The authors identified an optimal scaling regime wherein the model size and training epochs increase at the same rate. They also pinpointed optimal learning rates.

Another intriguing finding is that models with the lowest validation loss don't always yield the best performance post fine-tuning. A similar phenomenon has been observed with transformers. For fine-tuning, slightly larger models and slightly smaller epoch budgets consistently outperform others. Occasionally, a slightly higher learning rate can also be beneficial.
The takeaway? The bitter lesson! Computational power and data remain the key driving factors.
However, it's important to note that models have their own inductive biases. The authors acknowledge that in certain situations, ViT might be a more suitable choice, possibly due to its ability to employ uniform components across different modalities.