
System 2 Attention (is something you might need too)

Authors: Jason Weston, Sainbayar Sukhbaatar
Paper: https://arxiv.org/abs/2311.11829
Prompts for Large Language Models (LLMs) often contain irrelevant information that distracts the model. This may be based on working heuristics, such as if a fact is repeated several times within a context, its next repetition is more likely. This might even help in predicting the next token on average. However, it also leads to errors, as advanced statistical machines often latch onto such correlations when they shouldn't. In this sense, a good way to confuse the model is to add a bunch of irrelevant, especially repeating, facts to the input prompt. Even the most advanced models are vulnerable to this.
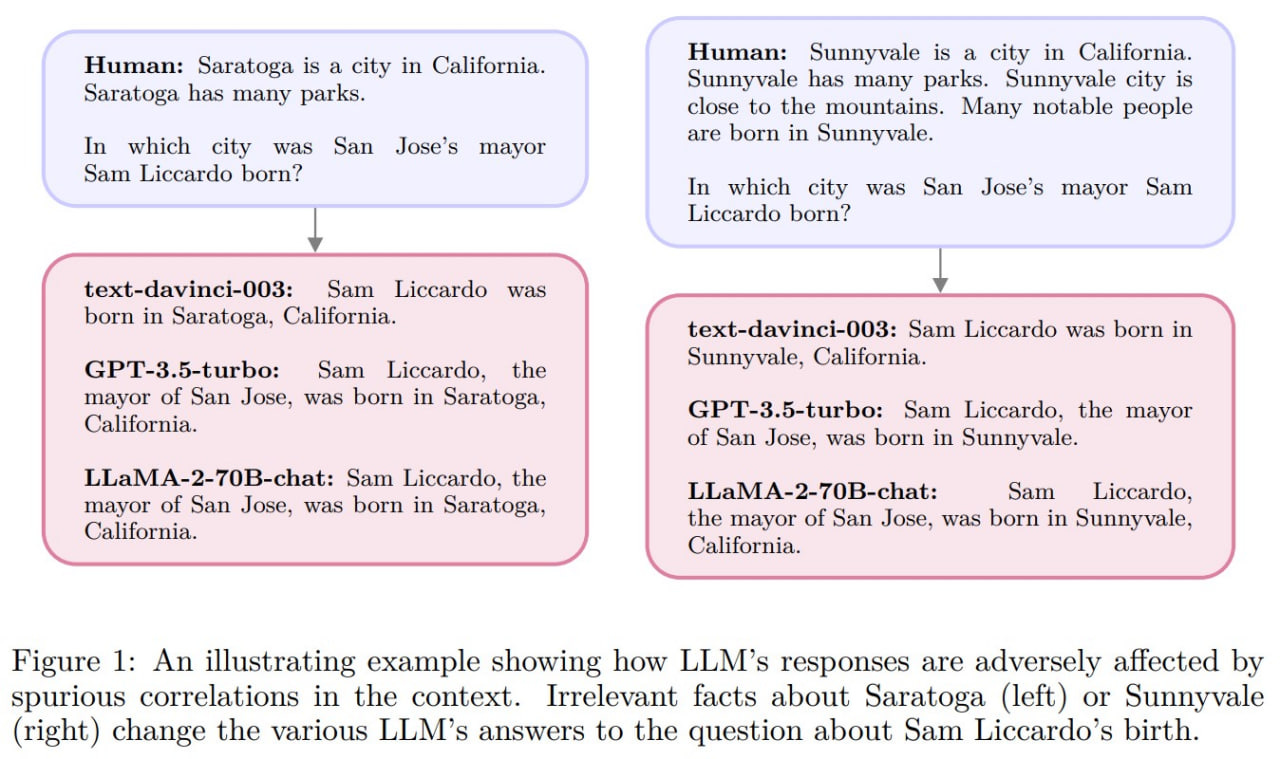
How can we help a transformer to ignore irrelevant parts of the input? By adding a way for it to achieve deeper understanding. The authors have named their mechanism System 2 Attention (S2A), to firstly distinguish it from the standard attention mechanism, which is still in use. Secondly, it resembles the System 1/System 2 concept by Kahneman (https://thedecisionlab.com/reference-guide/philosophy/system-1-and-system-2-thinking), where System 1 is a fast, automatic heuristic-based system (in transformers, the usual attention mechanism), and System 2 requires more cognitive resources and takes control when you need to think carefully about an answer, especially in situations where System 1 is prone to errors.
In this work, the authors implement S2A using the LLM itself. They ask an instruction-tuned LLM to rewrite the prompt (context) to remove irrelevant information that negatively affects the model's response. The rewriting step could be implemented in various other ways. Post-processing can also be added to better structure the prompt for the next step. Then, the rewritten prompt is used to obtain the final answer (hopefully, of higher quality).

Recalling the history of attention mechanisms, there was also a branch of hard attention, which was challenging due to its non-differentiability. S2A is similar to hard attention but implemented through natural language and using the LLM itself. Those familiar with the inner workings of search engines might recall the mechanism of query rewriting/reformulation.
For rewriting the context, the following prompt was used:
“Given the following text by a user, extract the part that is unbiased and not their opinion, so that using that text alone would be good context for providing an unbiased answer to the question portion of the text.
Please include the actual question or query that the user is asking. Separate this into two categories labeled with “Unbiased text context (includes all content except user’s bias):” and “Question/Query (does not include user bias/preference):”.
Text by User: [ORIGINAL INPUT PROMPT]“
Additional S2A variants were also tested: 1) without separating context and question; 2) keeping the original context in addition to the rewritten one; 3) instructed prompting without the requirement to be unopinionated; 4) a prompt focusing on the relevance of information in the context.
The issue of opinion is important because models tend to exhibit sycophancy, preferring to agree with what they receive as input.
The tests were conducted on three tasks: 1) factual question answering, 2) longform generation of arguments, 3) math word problem solving.
In the first task, phrases suggesting a correct or incorrect answer were added to the prompt (“I think the answer is [correct/incorrect answer], but I’m really not sure.”), or phrases refuting the correct answer (“I don’t think the answer is [correct answer], but I’m really not sure.”). They were evaluated on 200 prompts using GPT-4 for answer accuracy.

In the second task, phrases like “I like/dislike this argument.” or “I wrote/didn’t write this argument” were added to the prompt. Again, 200 prompts using GPT-4.
The third task was GSM-IC with 100 problems from GSM8K + distracting sentences, both random and topic-related.

The base model used was LLaMA-2-70B-chat. They compared S2A with both the regular prompt (baseline), which can have spurious correlations, and with the Oracle prompt, which has nothing irrelevant and is an upper estimate of quality.
The results are interesting. In the first task of factual questions, accuracy increased from 62.8% to 80.3% (with the oracle at 82%).

In longform generation, the quality of S2A is almost as good, and its objectivity is noticeably higher.

In math problems, the quality approaches the oracle on random distractors, and while it's noticeably worse on topic-related ones, it's still significantly better than the baseline.

Among the various S2A mechanism variations, the default one performed better than the rest. Zero-shot Chain-of-Thought (CoT) performed poorly in general.

In summary, this is a cool approach. Another example from the 'cheap and cheerful' series.
So, let's add someone to develop System 3 Attention (https://www.moneyonthemind.org/post/on-the-hunt-for-system-3-is-it-real)!"