
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
Like llama.cpp but 11x faster

Authors: Yixin Song, Zeyu Mi, Haotong Xie, Haibo Chen
Paper: https://arxiv.org/abs/2312.12456
Code: https://github.com/SJTU-IPADS/PowerInfer
This is a fascinating engineering project from the Institute of Parallel and Distributed Systems in Shanghai Jiao Tong University, aimed at optimizing the inference of Large Language Models (LLM) to run on consumer-grade GPUs. The authors have released their hybrid GPU-CPU inference engine called PowerInfer, which is over 11 times faster than llama.cpp on an RTX 4090 (24G) with the Falcon(ReLU)-40B-FP16 model. It also only shows an 18% slower token generation speed on RTX 4090 compared to the ten times more expensive A100 GPU.

Sounds good. Why and how does it work?
When neurons are hot
The work is based on two key observations.
First, the neuron activations in LLMs exhibit locality and follow a power-law distribution. There are a small number of hot neurons that are frequently activated across different inputs, and a majority of cold neurons that are rarely activated for specific inputs.
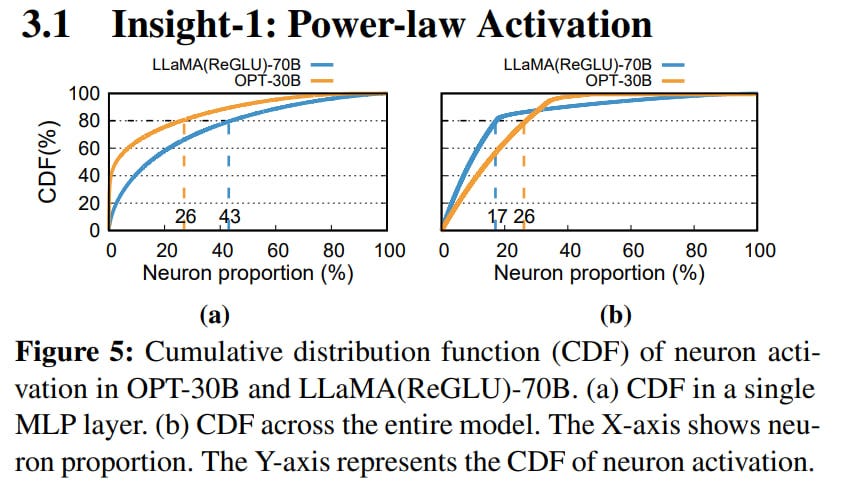
The second important observation is that transferring required weights from the CPU to the GPU and computing results there can be slower than computing them directly on the CPU, especially if only a subset of the weight matrix (which can be efficiently calculated using modern vector extensions in processor instruction sets) is needed.

Consequently, hot neurons (rows/columns of corresponding weight matrices) are sent to the GPU for quick access, while cold ones are computed on the CPU as needed. This significantly reduces the GPU memory requirements and minimizes data transfer over the PCIe bus.
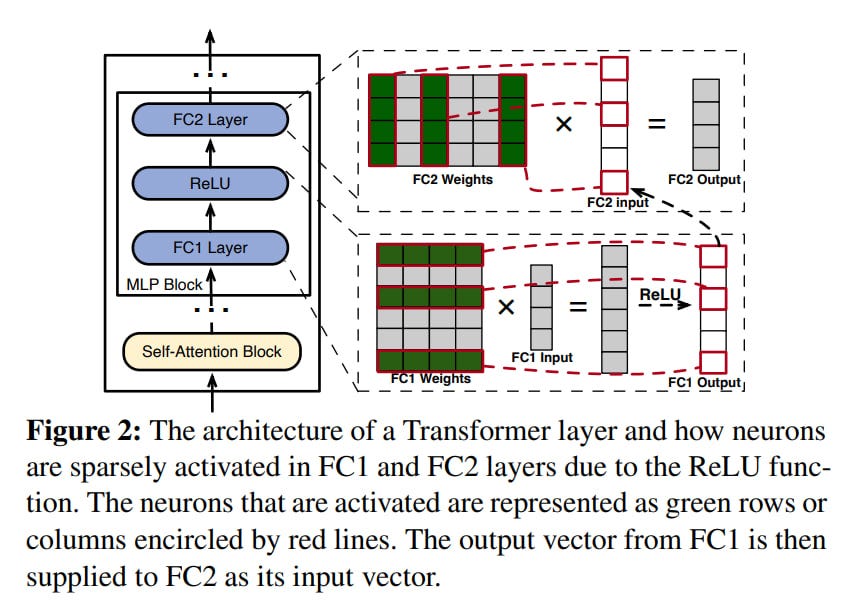
Enter PowerInfer
Technically, PowerInfer consists of two parts: the inference engine and an offline component.

The offline component includes a profiler for detecting hot neurons and a solver (based on Integer Linear Programming, ILP) for assessing the impact of a neuron on the inference result and creating a neuron placement policy. This is implemented in 400 lines of Python + HuggingFace Transformers. Hot/cold neurons are identified during this offline phase, and during inference, they are loaded onto the GPU/CPU respectively.
The inference engine, built on the base of llama.cpp, adds 4200 lines of C++/CUDA code. It runs separate CPU threads for GPU and CPU executors, which manage these concurrent computations, and the result merging happens on the GPU (where more frequently activated neurons reside). PowerInfer uses adaptive predictors to forecast which neurons will be active for current input data, and only these neurons (already separated into hot and cold) are computed. A neuron identified as hot in the offline phase and loaded on the GPU may still not be activated if the predictor decides it's not needed. This could be considered adaptive sparsity.

For each transformer layer, there are two predictors, one for MHSA and one for MLP. They also reside in GPU memory, so there's competition for this resource, making it important to keep the predictors as small as possible. A predictor is an MLP with a single hidden layer. The paper includes a clever iterative procedure for adjusting the hidden layer size of the predictor based on the skewness of activation distribution.

It seems that the predictors, both for hot/cold and for the online step, are independently trained on typical corpora like C4 or Wikipedia, and their training code is not yet published. However, it's planned to be released.
The more general-purpose sparse linear algebra libraries like cuSPARSE, Sputnik, SparTA, or FlashLLM are not perfectly tailored for such a case. The JIT compiler PIT does not support GPU-CPU hybridization. So, custom neuron-aware sparse operators were implemented.

The Speedup!
As a result, significant acceleration, up to ten times compared to llama.cpp, is achieved for various models.


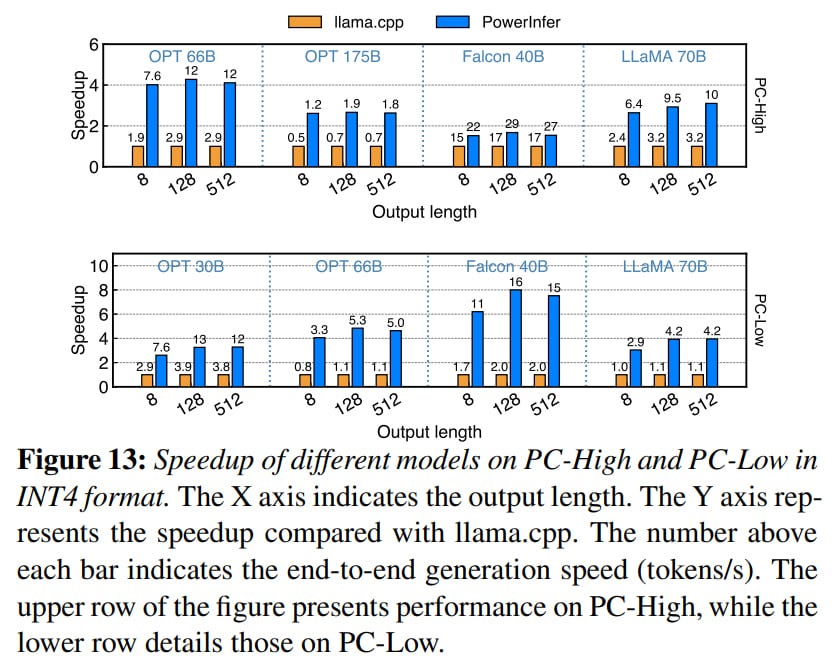
The induced sparsity minimally affects the model's quality. Occasionally there is a slight decrease, but sometimes there is also an increase in quality, which is interesting in itself (if it's not just statistical fluctuation).

PowerInfer is compatible with various LLM families, including OPT (7B-175B), LLaMA (7B-70B), and Falcon40B. Mistral-7B is coming soon.
I love this type of engineering! And I am confident that this and other similar solutions will give rise to a whole branch of new works and advanced inference engines. While this may not be particularly interesting to Nvidia (as they need to sell expensive A100/H100), the open-source community movement will create its own universe of solutions for more affordable hardware. And here, more than one startup should emerge.