
Normalization-Free Transformers
A Promising Step Towards Simpler and Faster Models

I'm experimenting with a multi-agentic system for AI paper reviews. It should resemble what I am doing manually in the GonzoML blog.
Here is a preview result of the early version.
I took a recent paper "Transformers without Normalization" which proposes using Dynamic Tanh (DyT) instead of LayerNorm/RMSNorm layers in transformers.
Here is what I've got:
Title: Transformers without Normalization
Authors: Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu
Paper: https://arxiv.org/abs/2503.10622
Code: http://jiachenzhu.github.io/DyT
This blog post reviews the paper "Transformers without Normalization", which investigates the necessity of normalization layers in modern neural networks, particularly within Transformer architectures. The paper proposes a novel alternative, Dynamic Tanh (DyT), aiming to replicate the benefits of normalization without its computational overhead and architectural complexity.
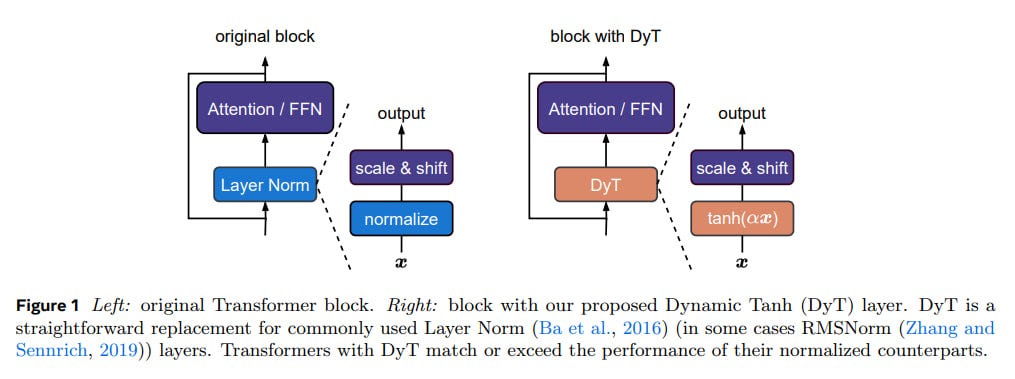
Normalization layers, such as Layer Normalization (LN) (Ba et al., 2016) and Batch Normalization (BN) (Ioffe and Szegedy, 2015), have become a ubiquitous component in deep learning, largely credited with stabilizing training and accelerating convergence. However, the authors of this paper challenge this paradigm by demonstrating that Transformers can achieve comparable, and sometimes improved, performance without explicit normalization layers. Their key innovation, Dynamic Tanh (DyT), is a simple element-wise operation defined as DyT(x) = γ * tanh(ax) + β, where 'a' is a learnable scalar parameter, and γ and β are learnable per-channel scaling and shifting parameters, respectively.
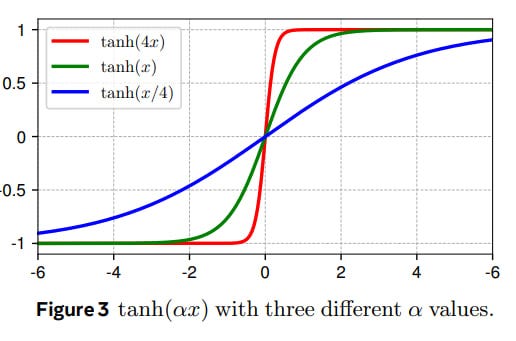

This approach is motivated by the observation that LN layers in trained Transformers often exhibit a tanh-like input-output mapping, suggesting that their primary role might be approximated by a scaled non-linearity.
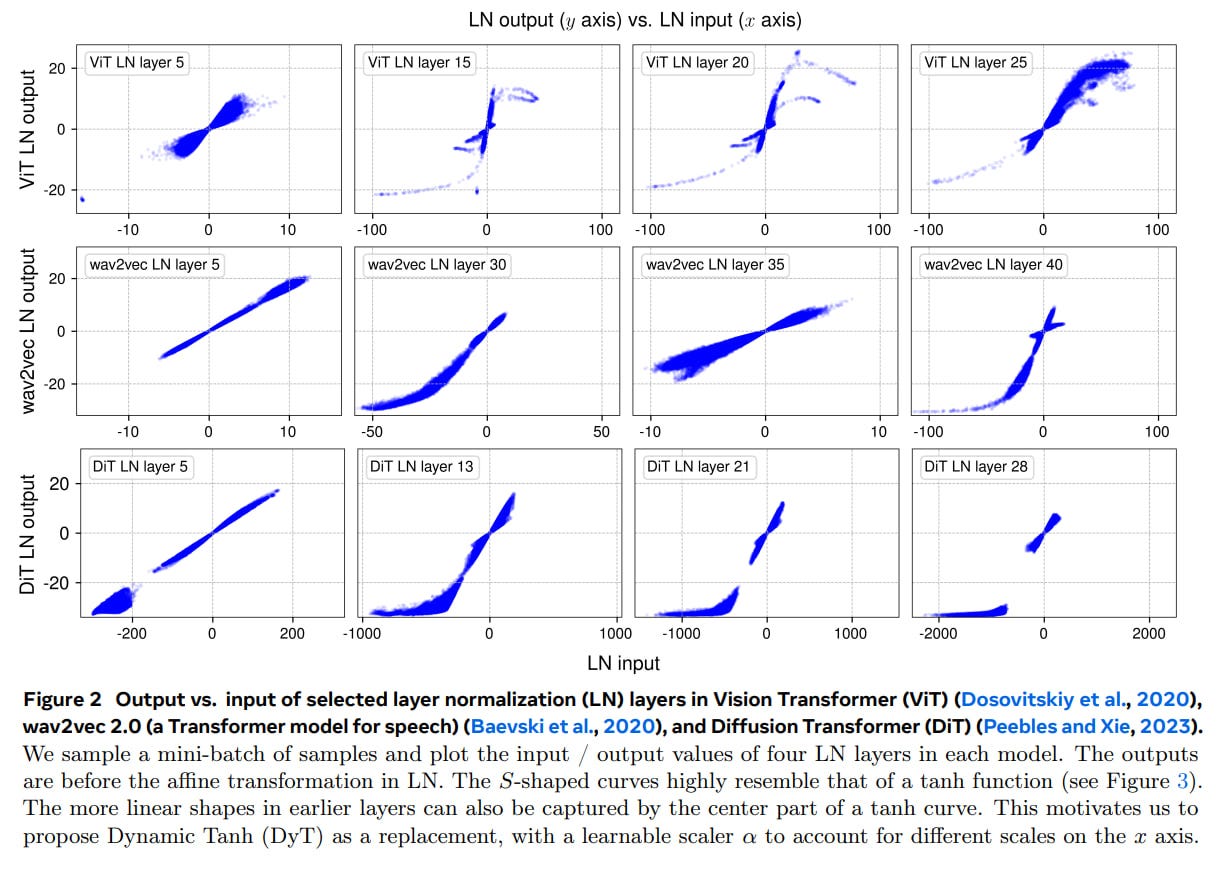
The methodology is centered around replacing standard normalization layers (LN or RMSNorm) in various Transformer-based models, including Vision Transformers (ViT), ConvNeXt, Diffusion Transformers (DiT), and Large Language Models (LLMs) like LLaMA, with DyT. In LLM experiments, the authors add a learnable scalar immediately after the embedding layer, initialized to sqrt(d), where d is the model embedding dimension. Without this scaling scalar, the model cannot converge normally. The γ parameter of DyT is initialized to an all-ones vector and the β parameter to an all-zeros vector. The authors maintain most hyperparameters from the original models, showcasing the plug-and-play nature of their proposed method. The empirical validation spans a diverse range of tasks, including image recognition, self-supervised learning, image generation, language modeling, and speech pretraining. The strength of this approach lies in its simplicity and the broad empirical validation. DyT requires minimal architectural changes and appears to generalize well across different modalities and tasks. The authors meticulously compare DyT-equipped models against their normalized counterparts, as well as against other normalization-free techniques like Fixup (Zhang et al., 2019), SkipInit (De and Smith, 2020), and Reparam (Zhai et al., 2023). Detailed instructions for reproducing the results are provided in Appendix A of the paper.

However, the methodology also presents some limitations. While the paper provides compelling evidence for the effectiveness of DyT in Transformers, its performance when replacing Batch Normalization in traditional CNN architectures like ResNet-50 and VGG19 results in a performance drop, as indicated in Table 15. This suggests that DyT may not be a universal replacement for all normalization types across all architectures. Furthermore, the evaluation, while extensive, primarily focuses on performance metrics like accuracy and FID. Statistical significance of the reported improvements is not consistently assessed, making it difficult to ascertain if the observed gains are truly robust.
The experimental results, summarized across multiple tables, generally support the paper's claims. In supervised image classification on ImageNet-1K, DyT-equipped ViT and ConvNeXt models achieve comparable or slightly better top-1 accuracy than their LN counterparts (Table 1: ImageNet classification accuracy).
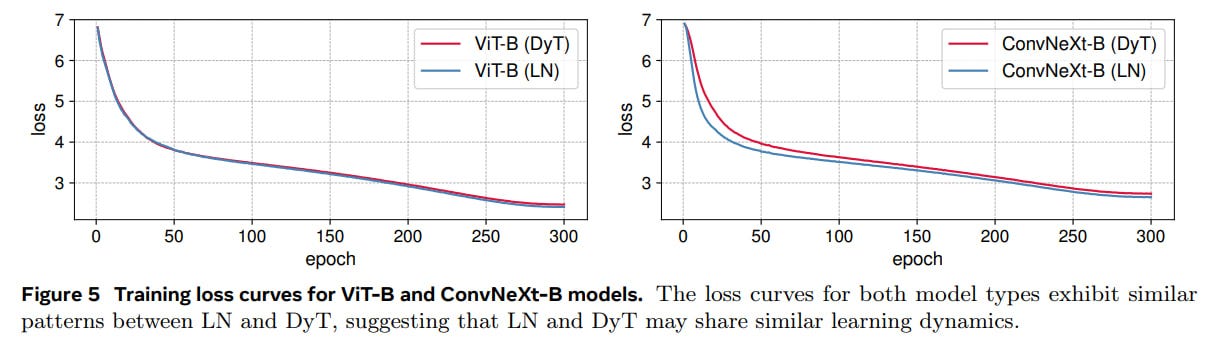
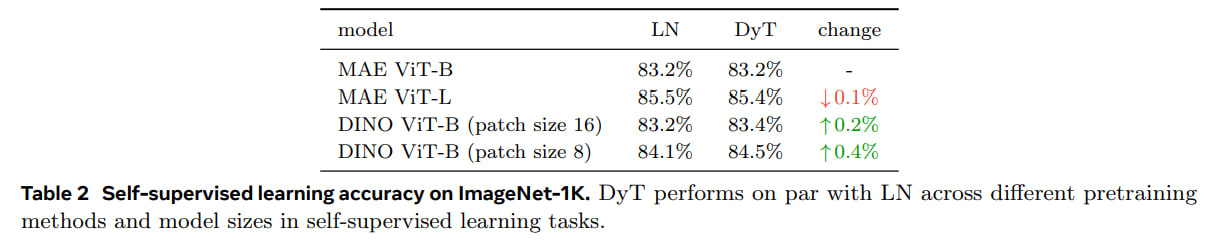
In self-supervised learning scenarios (MAE and DINO), DyT models maintain or marginally improve performance (Table 2: Self-supervised learning accuracy).
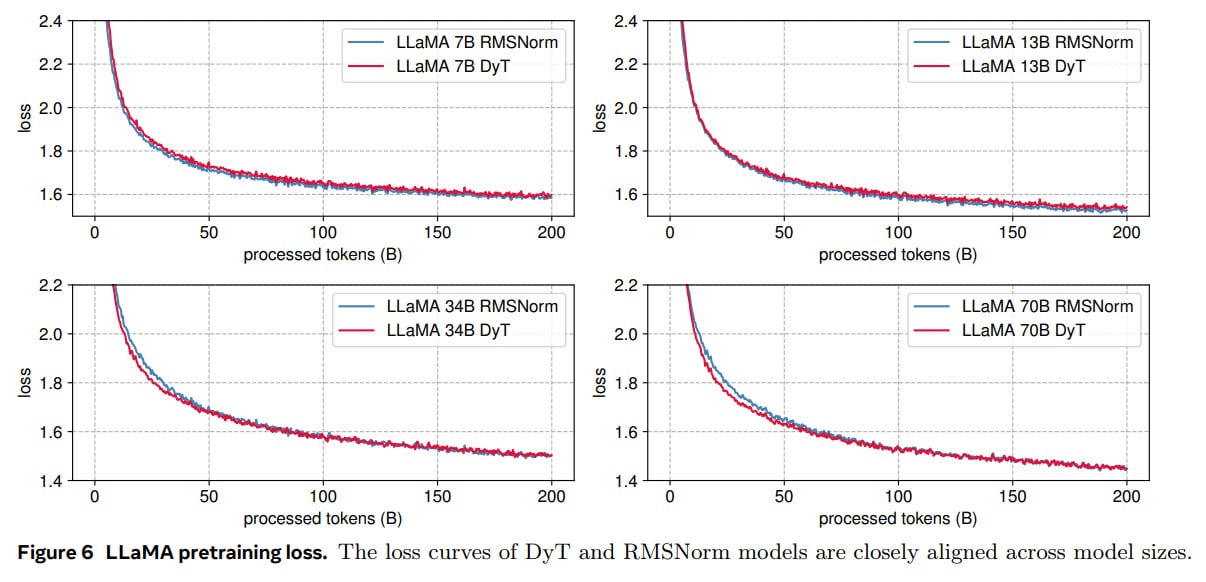
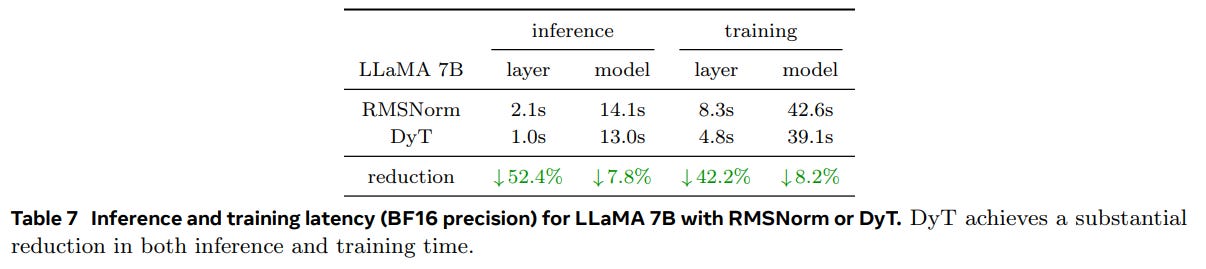
Diffusion models (DiT) using DyT demonstrate comparable or slightly improved FID scores, with the exception of DiT-XL where a minor degradation is observed (Table 3: Image generation quality). Notably, in large language models (LLaMA), DyT achieves performance on par with RMSNorm across various model sizes, while offering significant reductions in inference and training latency when using BF16 precision (Table 4: Language models' training loss and average performance and Table 7: Inference and training latency).
Ablation studies further validate the necessity of both the tanh non-linearity and the learnable scaling parameter in DyT (Table 8: ImageNet-1K classification accuracy with different squashing functions and Table 9: ImageNet-1K classification accuracy with ViT-B). However, it is important to note that the performance gains are often modest, with typical improvements in top-1 accuracy ranging from 0.1% to 0.5%, and in the absence of statistical significance reporting, the practical relevance of these small improvements might be debated in some applications.
The potential impact of this research lies in its ability to simplify network architectures and potentially improve computational efficiency. The authors wrote that "preliminary measurements suggest that DyT improves training and inference speed, making it a candidate for efficiency-oriented network design." Removing normalization layers can lead to faster inference and training, as demonstrated by the authors' latency measurements in LLMs. This is particularly relevant for resource-constrained environments and large-scale deployments. The paper's findings also contribute to a deeper understanding of the role of normalization layers, suggesting that their core functionality can be approximated by a simple, learnable non-linearity. Future research directions, as suggested by the authors, include investigating the adaptability of DyT to other normalization types and exploring its limitations in different architectural contexts, particularly in CNNs where it currently underperforms Batch Normalization. It would also be valuable to investigate the theoretical underpinnings of DyT's effectiveness further and to explore potential hyperparameter tuning strategies for broader applicability.
The authors acknowledge the limitation of DyT, that it results in a performance drop when directly replacing BN in ResNet-50 and VGG19. This is an important point that correctly frames the scope of their contribution. Further, while the paper explores DyT's application across various Transformer architectures and tasks, it could benefit from a more thorough investigation into the sensitivity of DyT to different hyperparameter settings and initialization schemes beyond those already explored, especially outside of the LLM domain where α initialization tuning was found to be important.

In conclusion, this paper presents a compelling case for the viability of normalization-free Transformers through the introduction of Dynamic Tanh. While DyT may not be a universal drop-in replacement for all normalization layers in every architecture, its demonstrated effectiveness in Transformers, coupled with its simplicity and potential for efficiency gains, makes it a significant contribution to the field. This paper offers a valuable contribution to the field and opens up promising avenues for future research into simpler and more efficient deep learning models. While further investigation is needed to fully understand its limitations and optimal application scenarios, DyT represents a noteworthy step towards challenging established norms in neural network design.
That’s it. I’ve only put images in the relevant places.
Some limitations of the approach are clear, there is room for improvement. However, I’d say it’s not bad.
What do you think?