
🪆Matryoshka Representation Learning

Authors: Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, Ali Farhadi
Paper: https://arxiv.org/abs/2205.13147
Code: https://github.com/RAIVNLab/MRL
The problem of fixed-size embeddings
It's a paper from NeurIPS 2022 I've long been wanting to tackle. It sat among thousands of open tabs (where plenty of interesting reads await their turn), until I stumbled upon the fresh "Matryoshka Diffusion Models" (https://arxiv.org/abs/2310.15111). However, as fascinating as diffusion models are, it's the concept of representations that's truly intriguing.

The core idea challenges the efficacy of fixed-size representations (embeddings). For certain tasks, they may be excessively large, leading to high computational costs during inference, which is the key phase in a model's lifecycle. For others, they may be too small, compromising quality when it's too late or costly to retrain. Typically, pinpointing a subspace within the embeddings is difficult, as gradient training tends to spread information across the entire vector. The alternatives are either training separate embeddings of varying sizes (which is unwieldy) or compressing them post-training.
The fixed-size embeddings were also a problem in encoder-decoder models before invention of the attention mechanism.
This raises the question: Can we devise a flexible representation that adapts to various tasks with differing computational demands? The answer is a resounding yes!
🪆Matryoshka saves the world
The authors introduce the 🪆Matryoshka Representation Learning (MRL) approach, which allows for such adaptable representations. The idea is straightforward: within a fixed-size embedding (d), nested subspaces of sizes d/2, d/4, d/8, and so on, are identified, each serving as an effective embedding for its respective size.

The challenge lies in modifying the training process so that the first m dimensions of a vector of size d contain general representations transferable across different tasks.
The study is conducted on supervised multi-class classification using ResNet50, which embeds into a vector of size d = 2048, and the ImageNet-1K dataset with a thousand classes. A set of nested dimensions M = {8, 16, ..., 1024, 2048} is utilized.

The final classification loss for MRL is a sum of individual cross-entropy softmax losses across all dimensions, with each loss weighted by an importance coefficient Cm, which were all set to one in the study.

Moreover, linear classifiers can share weights, meaning the weights of the classifier for a smaller embedding are a subset of those for a larger embedding. This strategy helps conserve memory in cases of vast embedding spaces and is known as Efficient Matryoshka Representation Learning (MRL-E).
Evaluation
The approach was tested on a variety of tasks.
For representation learning, the following tasks were selected:
(a) Supervised learning for images: ResNet50 on ImageNet-1K and ViT-B/16 on JFT-300M.
(b) Contrastive learning for images and language: ALIGN with a ViT-B/16 vision encoder and a BERT encoder on the ALIGN dataset (https://arxiv.org/abs/2102.05918).
(c) Masked language modeling: BERT on English Wikipedia and BooksCorpus.
Optimal hyperparameters were not sought; instead, those from independently trained baselines were used.
ResNet has an embedding size of 2048, while ViT and BERT have 768. The corresponding dimensionality ladders are: M = {8, 16, 32, 64, 128, 256, 512, 1024, 2048} and M = {12, 24, 48, 96, 192, 384, 768}.
For comparison, the folowing baselines were taken: low-dimensional fixed-size representations (FF), dimensionality reduction with SVD, sub-net method (slimmable networks) and randomly selected features of the highest capacity FF model.
Quality is assessed on ImageNet through linear classification/probe (LP) and 1-nearest neighbor (1-NN). MRL excels, with small embedding size quality even slightly higher than for a fixed embedding of the same size. And it performs much better than both randomly selected features and SVD.
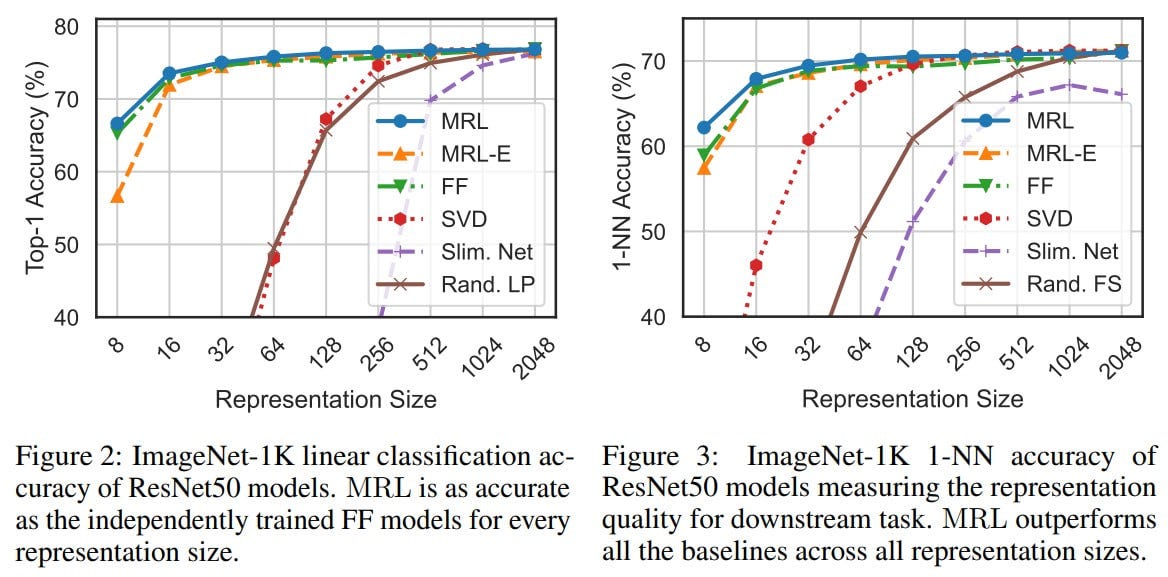
For ViT and JFT-300M, the experiments are costly as it is a web-scale dataset, so here only the largest FF model was trained. And here MRL also demonstrates its effectiveness. Additionally, the obtained embeddings can be interpolated if an intermediate size is needed -- the accuracy of such representations lies exactly on the curve where one would expect.
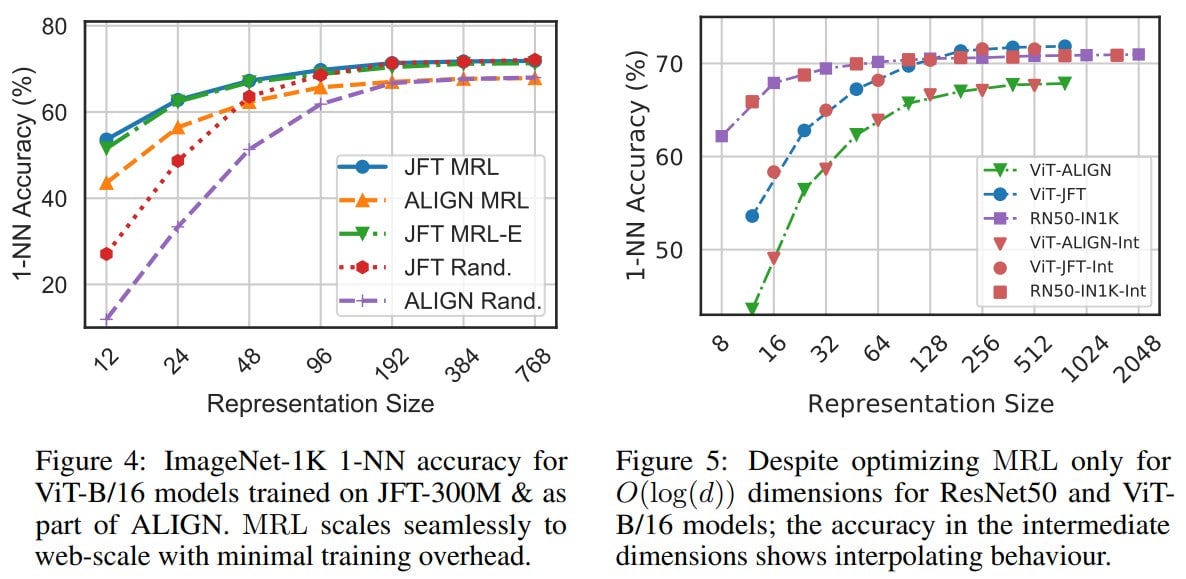
Such features allow for cost-effective adaptive classification with cascading models like the Viola-Jones type. We start with the smallest embedding, get a prediction, and if the confidence is below the trained threshold, we add the next largest embedding. The result is the quality of a fixed-size embedding with a representation 14 times smaller.

A separate topic is retrieval. The goal is to find images from the same class as the query using embeddings. Evaluated by mean Average Precision@10. Embeddings are normalized and retrieved through L2 proximity. MRL outperforms baselines and is even better than individual FF embeddings. MRL-E performs slightly worse.

Combined with adaptive retrieval (AR), it's possible to save a lot of space by not storing full representations. In AR, a shortlist (K=200) of candidates is first obtained through a low-dimensional representation (Ds = 16), then the list is reranked through a higher-dimensional one (Dr = 2048) -- this is much cheaper computationally than searching for neighbors with the full embedding. AR with the above parameters is as accurate as full embedding search (d = 2048), but theoretically 128 times more efficient and 14 times faster in practice.
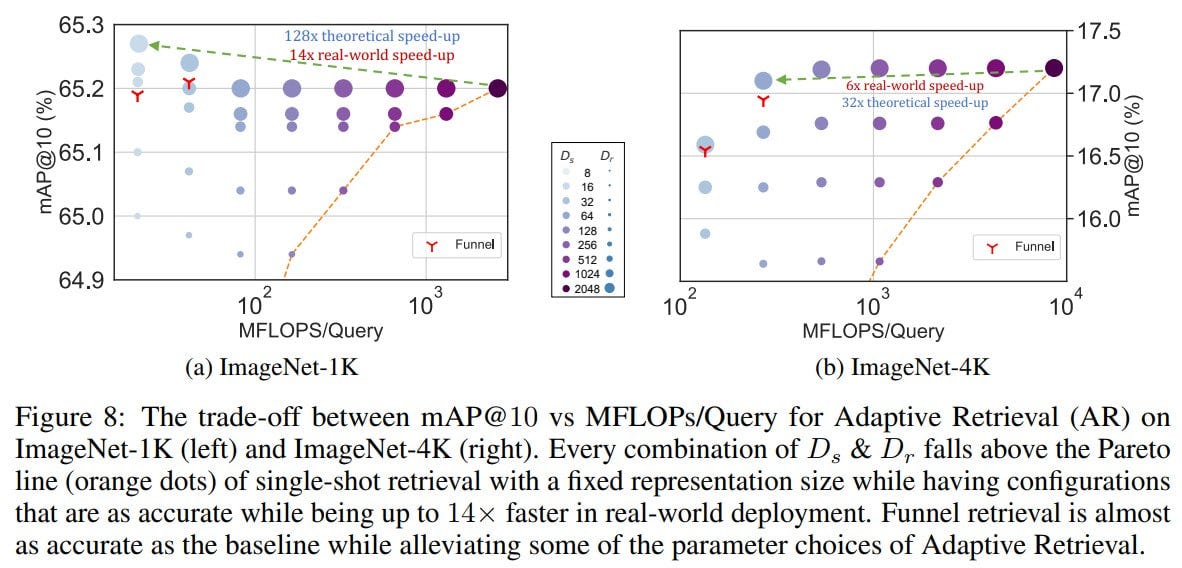
Determining the optimal values for Ds and Dr can be challenging, so the authors suggest the Funnel Retrieval approach, which uses a cascade of sequentially increasing embeddings. We start with the smallest, then rerank the list obtained at each stage with a broader embedding, halving the list and doubling the dimensionality each time.
Curious if any vector databases already support this? At the very least, there's the following work on adaptive approximate nearest neighbour search using matryoshkas -- a study that appeared at both ICLR 2023 (https://iclr.cc/virtual/2023/13999) and NeurIPS 2023 (AdANNS, https://arxiv.org/abs/2305.19435) — is that even allowed?
On out-of-domain datasets, the robustness of MRL representations is no worse than standard ones. For retrieval tasks, it's even slightly better. It also performs well in few-shot learning through nearest class mean. There's even improvement in on novel classes in the tail of the distribution.
In general, as the size of the embedding increases, so does the classification quality. However, there are a number of cases where classification is better with a smaller embedding size.

If you evaluate the quality on a super-class (when there is a hierarchy in the labeling), there's not such a significant drop in the small size of the representation. This means that these embeddings also capture some hierarchy.

Matryoshka Representations can also be obtained by partially fine-tuning already trained models.
In summary, it’s a cool and an almost free way to improve representations. It would be interesting to train an embedding model like text-embedding-ada or those made by Cohere in such a setup. And in general, there's a lot of room for improvement -- from individual losses and optimizing their weightings, to special structures for search.