


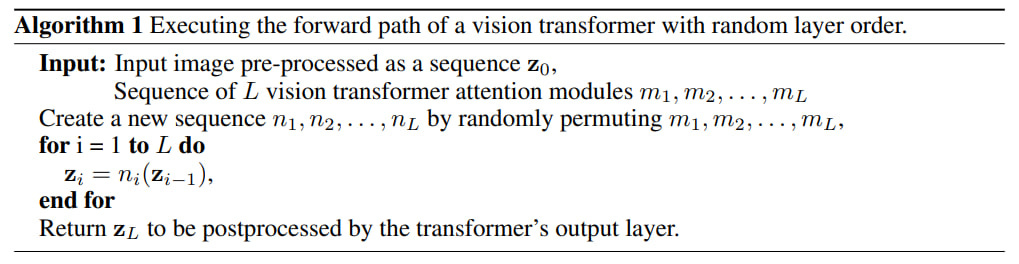
LayerShuffle
Enhancing Robustness in Vision Transformers by Randomizing Layer Execution Order

LayerShuffle: Enhancing Robustness in Vision Transformers by Randomizing Layer Execution Order
Authors: Matthias Freiberger, Peter Kun, Anders Sundnes Løvlie, Sebastian Risi
Paper: https://arxiv.org/abs/2407.04513
Recently, two intriguing papers on creative approaches to transformer layer computation have emerged. This ties in with my cherished topic of Adaptive Computation Time (ACT) and dynamic computation in general. I previously discussed transformers with ACT in this post, which is part of a series starting here.
Today, I'll highlight the first interesting paper on dropping transformer layers during inference. If a network can withstand such events, it opens up fascinating possibilities for computations in unstable distributed environments where some computations might fail or occur out of order. The ability to maintain functionality and quality under these conditions is quite intriguing.
Conceptually, this is akin to Dropout, where some neurons in a layer are dropped, but done at a higher level. In 2019, some of my favorite authors published a structured dropout variant called LayerDrop (https://arxiv.org/abs/1909.11556), which allowed for pruning parts of the transformer layers during inference, resulting in models with better quality than those trained from scratch or even obtained through distillation (!). It would be interesting to see a variant of this with Gemma 2, where a smaller model isn't distilled but dropped from a larger one.

LayerShuffle goes further, not just dropping layers during inference but shuffling them, changing the execution order. This is tested on Vision Transformers (ViT), though it seems the specific model doesn't matter. Several procedural variants are considered.

In the simplest case, LayerShuffle randomly changes the layer order for each batch during training. This prevents layers from overly relying on the output of a specific preceding layer.
In the second variant, LayerShuffle-position, each layer also receives an embedding of its current position (32 additional numbers concatenated with the input embedding).

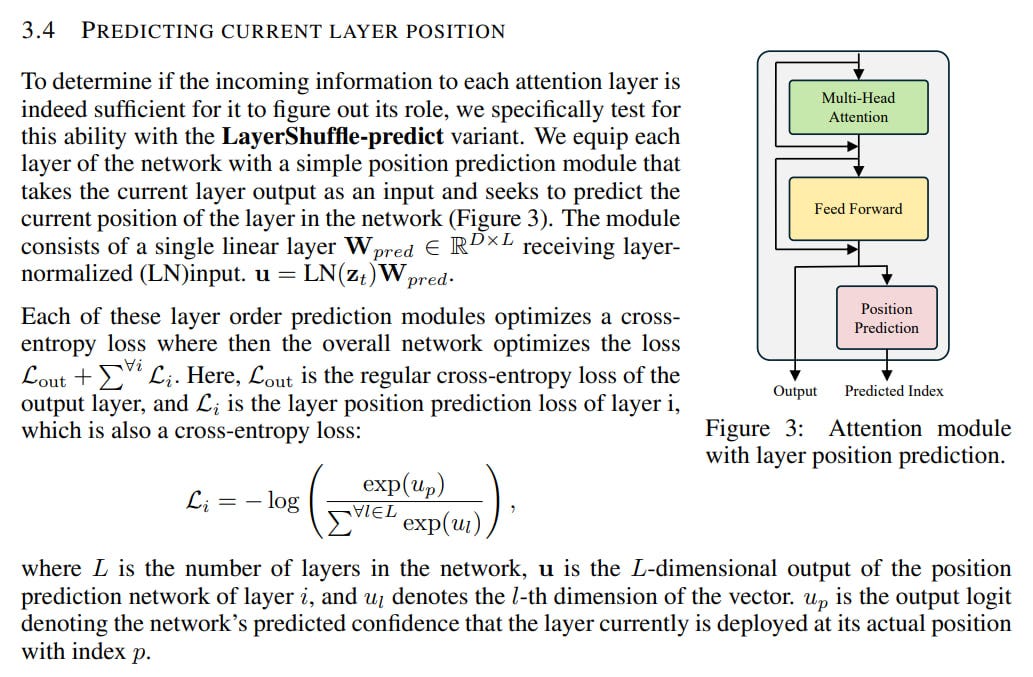
The third variant, LayerShuffle-predict, attempts to predict a layer’s current position from its output embedding using a cross-entropy loss (this is a bit odd since both minor and major position errors are penalized equally).
Tests were conducted on ImageNet2012 with a pre-trained ViT-B/16 from HuggingFace, further trained using the described procedures.
When switched to a random layer order mode, a standard transformer's quality drops from 82% to almost zero, while the LayerShuffle variant drops from about 75% to 63%. The LayerShuffle-position leads with a slight edge over the simple LayerShuffle.

This shows that a standard transformer is catastrophically unstable to changes in layer execution order, which was somewhat expected. Interestingly, the LayerShuffle-position variant with position embeddings doesn't significantly improve outcomes, suggesting that essential information is already present.
The effect of pruning during inference was also tested. The quality roughly matches LayerDrop with p=0.2, even though the model wasn't trained for layer dropping. If layers are both pruned and shuffled, LayerDrop quality drops to zero, while LayerShuffle remains stable, making it the more robust option.
A visualization of layer outputs using UMAP, without providing positional information to the algorithm, shows no obvious discontinuous separation of embeddings, but they do group by their real positions, especially those close to the beginning, and somewhat at the end.

An interesting idea emerges: if layers can be computed in a different order, what if we merge layers from different models trained with the presented procedure? In the extreme, each of the 12 ViT layers could come from a different trained model. The authors created 100 different merged models (from the 12! possible combinations). The original ViT-B/16 is useless in such a configuration, with extremely low quality. LayerShuffle merged models performed decently, though about 3% lower than the original LayerShuffle model. However, if all 12 trained models are ensembled, the quality is about 9% higher.

Dreaming about the future, when will it be possible to buy GPT-n layers from the market (maybe even as preprogrammed chips) and assemble your own model? Also, waiting for a distributed network with model pieces deployed on different devices, maybe with something like Kubernetes to manage this process...