
GFlowNets
Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation

Authors: Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, Yoshua Bengio
Paper: https://arxiv.org/abs/2106.04399
Code: https://github.com/GFNOrg/gflownet
Blog Post: https://yoshuabengio.org/2022/03/05/generative-flow-networks/
Short summary by a co-author: https://folinoid.com/w/gflownet/
I have long wanted to write about GFlowNets, or Generative Flow Networks, a work co-authored by Yoshua Bengio, which he speaks very highly of and considers an important new direction in research. According to Bengio, among other cool things, this work paves the way for implementing system 2 inductive biases.
This post is mainly about the foundational work from NeurIPS 2021. As of now, there have been developments, such as “GFlowNet Foundations” (https://arxiv.org/abs/2111.09266), “Multi-Objective GFlowNets” (https://arxiv.org/abs/2210.12765), “A theory of continuous generative flow networks” (https://arxiv.org/abs/2301.12594) and much more, especially in the applied part with applications in various fields, particularly for biology, e.g., “Biological Sequence Design with GFlowNets“ (https://arxiv.org/abs/2203.04115).
Generative Flow Networks
GFlowNets (GFN) are generative networks, as the name suggests, in which the generative process is represented by a flow network. The original work focused on generating molecular graphs, but in general, GFN is suitable for sampling various combinatorial objects.
The goal is not to get a single sequence of actions with the maximum reward, but to sample from a distribution of trajectories, whose probability is proportional to the reward. In other words, to transform a given reward function into a generative policy, sampling with a probability proportional to the reward. This can be useful in tasks where there are many modes and exploration is an important part (such as in drug discovery). In one of the subsequent works, GFNs are referred to as diversity-seeking reinforcement learning algorithms.

GFlowNet works with a network whose nodes represent states, and the outgoing edges correspond to deterministic transitions resulting from chosen actions. The flow in this network gives the probability of an action in the current state. GFlowNet is specifically a network, not a tree -- different paths can lead to the same states.

An MDP (Markov Decision Process) on the network, where all leaves are terminal states with a reward, is represented as a flow network described by a directed acyclic graph (DAG). Episodic RL is used, where the reward is obtained only at the end of the episode, and throughout the process, it is zero. The network has one source (s0 in the image) and as many sinks as there are leaves (say, x3 or x16 in the image), the outgoing flow is equal to the reward in the leaf, and the incoming flow is the sum of all outgoing flows. The overall flow through the network at each node must satisfy the condition that the incoming flow into the node equals the outgoing flow from it. Regarding policy, the probability of an action a from state s, π(a|s), is equal to the ratio of the flow from state s along the edge a, F(s, a), to the total flow from state s, F(s).

For real tasks, it's unrealistic to explicitly set up the network (for example, for molecules, it might require 1016 nodes), so we approximate the flow through each node with a neural network (e.g., a graph network or a transformer), similar to the transition from RL to DRL (Deep RL). The network receives a description of the state, and the output is a set of scalars corresponding to the next states.
The objective (or loss) for a trajectory τ is inspired by the Bellman equations for temporal-difference (TD) algorithms, and is a sum in which the flows along the edges of the trajectory from the current states are positive, and the terminal rewards of the next states and flows from them are negative.

To combat different scales of flows (large at input nodes, small at output nodes), flow matching objective uses logarithms of flows. Minimizing this objective yields the correct flows with the properties we need, allowing us to sample from the policy.

There are also other objectives from later works, such as detailed balance (https://arxiv.org/abs/2111.09266) and trajectory balance (https://arxiv.org/abs/2201.13259).
If I understand correctly, with this loss, a gradient descent step is carried out (generally SGD, specifically here Adam) with four trajectories in a mini-batch. Training of GFlowNet proceeds by bootstrapping -- we sample trajectories (can be with the current policy, then it's on-policy training, or with other policies and even other means for exploring the space, including lifting data from databases, then it's all off-policy), get rewards for them, calculate the loss and update the current policy (by gradient descent).

In the case of molecules, the task was to generate a set of small molecules with high reward (which was determined through a proxy model). The graph describing the molecule is a sequence of additive edits, where at each step, the agent chooses one of 72 predefined blocks to add, as well as the atom to which it will be added. There is an additional action to stop editing.
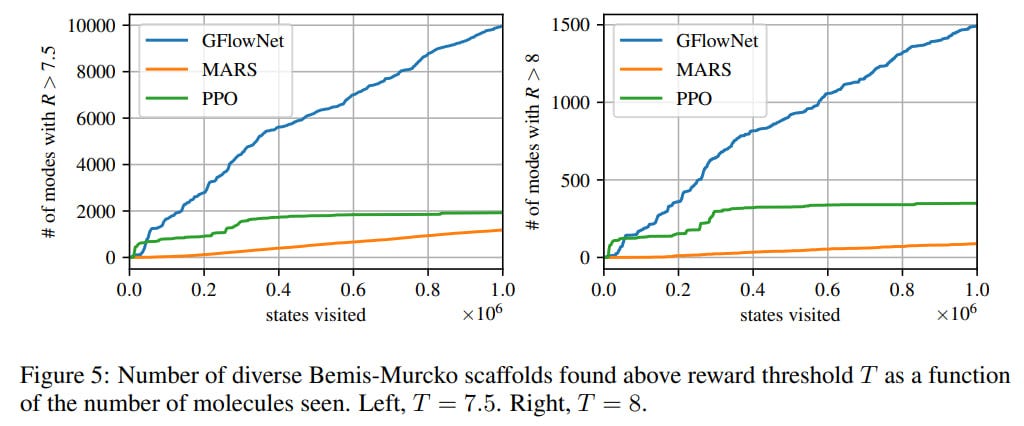
This sequence of edits gives a DAG MDP. For the proxy, a Message Passing Neural Network (MPNN, https://arxiv.org/abs/1704.01212) with GRU inside was used, to which the atom graph was fed; for the flow predictor — MPNN with a block graph. GFN worked well and found more diverse candidates than baselines with MCMC (MARS) and RL (PPO).
Resources
Related links:
In November 2023, a GFlowNet Workshop took place at Mila, and video materials are available here:
There is a comprehensive GFlowNet tutorial and a Colab.
A collection of resources on the topic is here.
In addition to the code for the article, there are libraries for working with GFlowNets, such as gflownet from Recursion and partly the same authors; and torchgfn.
In principle, it seems that GFlowNets could be an interesting option for training LLMs. There is at least one fresh work on this topic: “Amortizing intractable inference in large language models” (https://arxiv.org/abs/2310.04363), in which they do an LLM fine-tuning.
So, GFlowNets is now an actively developed topic. Stay tuned!