
Do Code Agents Actually Understand the Code They're Working With?

I’ve been thinking about a gap between what code agents do and what they understand. They write functions, fix localized bugs, pass benchmarks — but ask them to modify something that touches six modules in a real codebase and things fall apart. Why?
The spark: Theory of Space
Earlier this year I read Theory of Space [published an auto-review here] by Zhang et al. — a paper that tests whether multimodal models can build “cognitive maps” when exploring partially observable environments (think: grid worlds where you can only see what’s nearby). They found two striking things: models are much worse when they have to actively explore vs. receiving everything at once (the Active-Passive Gap), and they can’t update their beliefs when the environment changes (Belief Inertia).
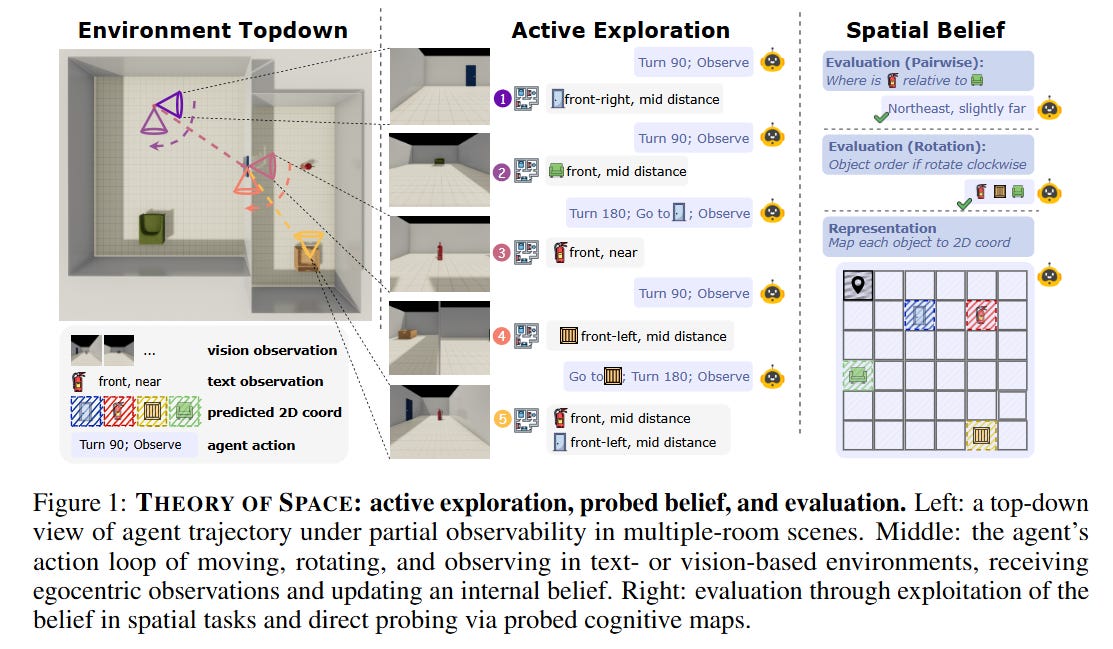
Reading that, I had a thought that felt almost obvious: we have exactly the same problem in code.
When a developer navigates a large codebase, they build a mental model — which modules depend on which, what the data flow looks like, where the architectural boundaries are. They update that model as they read more files. Code agents don’t seem to do this well, and nobody is measuring whether they do it at all.
Every existing code benchmark tests output — does the patch compile? Does the test pass? None of them test the agent's evolving architectural belief. So I built one.
From spatial maps to code maps
So I started building a benchmark that transplants the Theory of Space framework to software engineering. The idea: place an agent in a codebase it’s never seen, give it a budget of actions (open files, search, inspect symbols), and periodically ask it to externalize its architectural belief as structured JSON. This gives you a time-series of understanding, not just a final snapshot.

The basic setup:
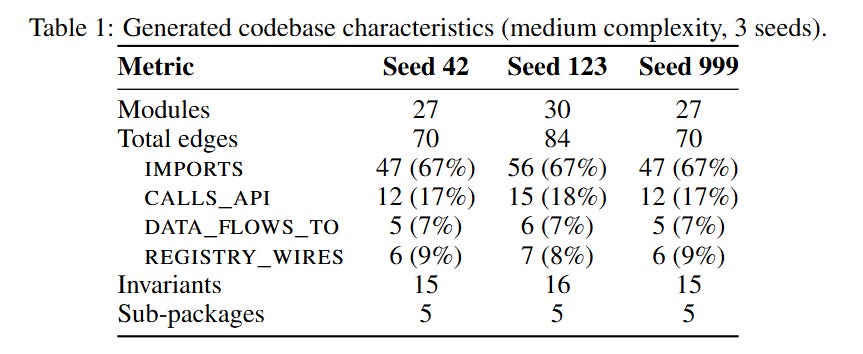
Procedurally generated codebases with known ground truth — you need to know the “true architecture” to score the agent’s beliefs
Partial observability — the agent opens files one at a time under a budget of 20 actions, so exploration strategy matters
Periodic probing — every 3 actions, the agent outputs its current belief as JSON: which modules exist, how they connect, what constraints hold
Four types of dependency edges — from trivial (Python imports, visible via AST) to hard (config-driven dynamic wiring where no import statement exists)
But as I dug in, I realized code has dimensions that spatial environments don’t (or at least they are not so pivotal there). Software architecture isn’t just a graph of connections — it embodies design intent. A forbidden dependency enforces a service boundary. A validation chain ensures data integrity. These are checkable constraints you can plant in the codebase and measure whether agents discover them. So I added Architectural Constraint Discovery as a new evaluation dimension — something you can’t even define in a grid world (well, you can sometimes… — “no loitering”, “stop” signs, rules and tacit knowledge, etc).
What I’ve found (preliminary, but interesting)
I ran the benchmark on four rule-based baselines and six frontier LLMs from three providers. The results were more surprising than I expected.
#1. The Active-Passive Gap direction is model-dependent. In spatial reasoning, models consistently do worse in active mode. In code, it depends on the model. GPT-5.3-Codex actually performs better through active exploration than when given the full codebase at once (APG = −0.22) — likely because 27-30 files dumped simultaneously creates information overload, while sequential exploration allows focused processing. Gemini 2.5 Flash shows the opposite pattern (APG = +0.23). Active exploration is itself a capability that some models have and others don’t (or maybe there are other effects in place).
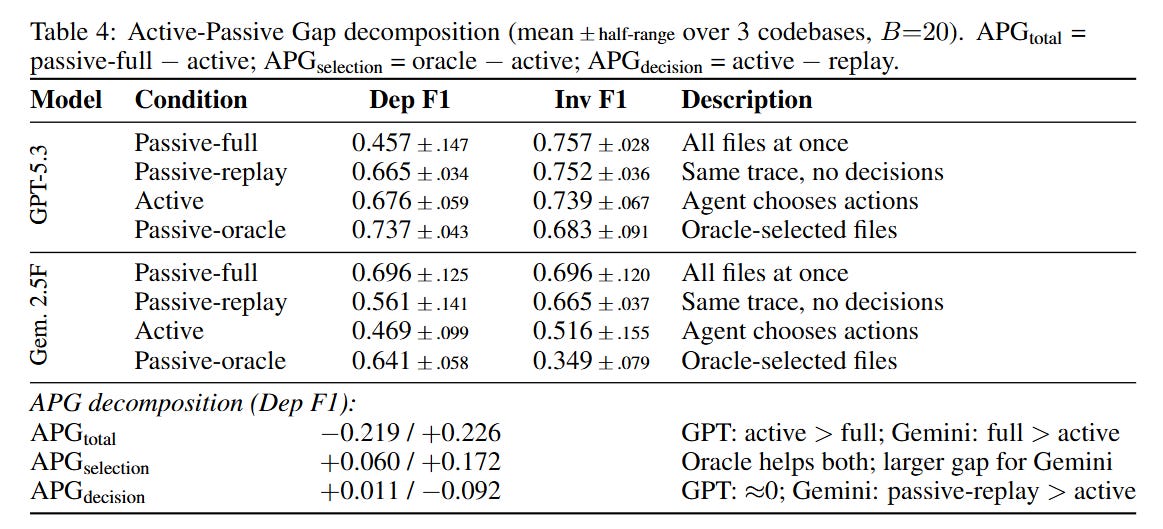
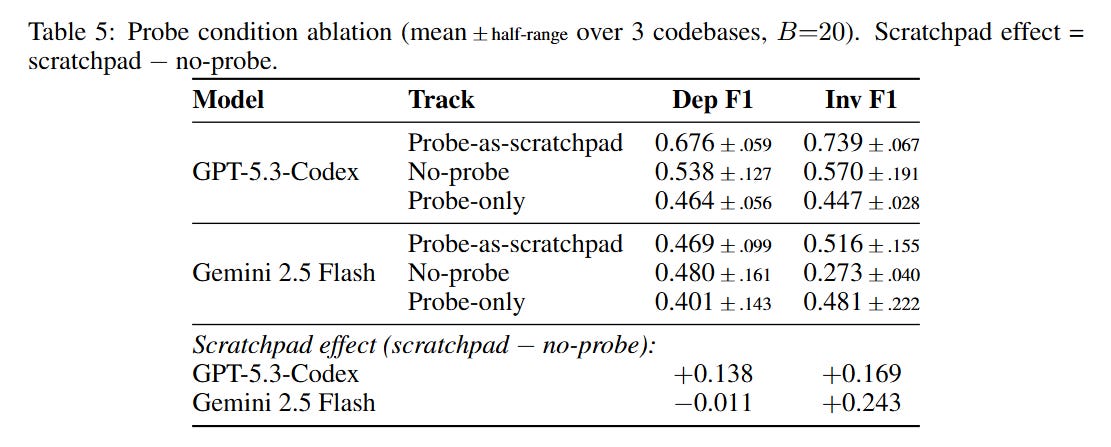
#2. Self-scaffolding through belief externalization is model-dependent. Retaining the structured belief map in context (scratchpad mode) boosts GPT’s F1 by 14 points — it uses its own previous maps as working memory. But Gemini gets no dependency-level benefit from the same mechanism. The scratchpad helps Gemini only for invariant discovery, not structural mapping. Different models leverage the same external state through different cognitive channels.
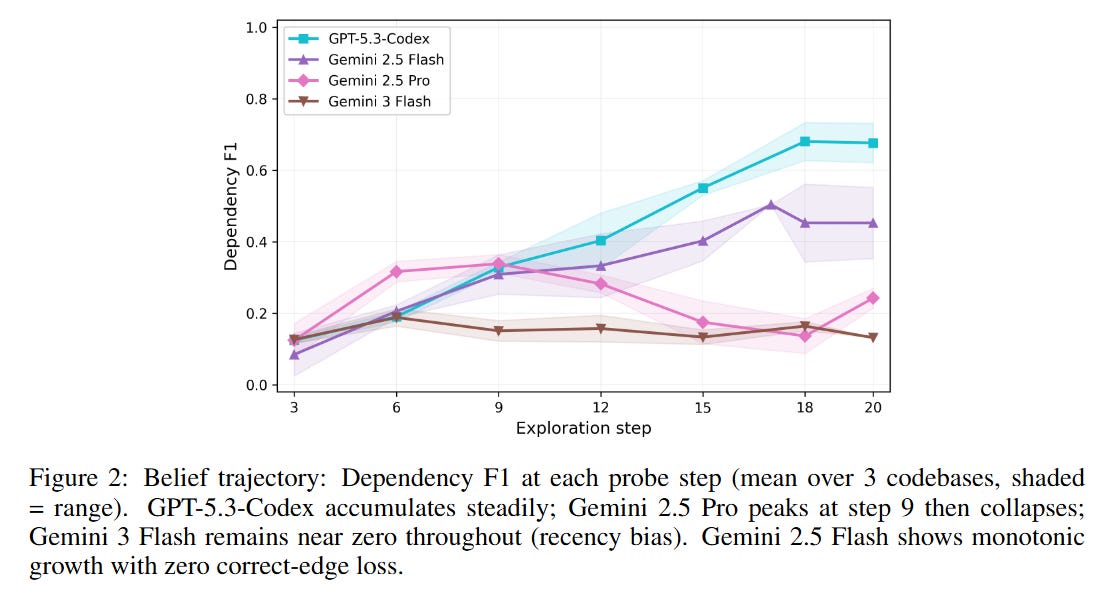
#3. Belief state maintenance varies dramatically — and not by model size. Gemini 2.5 Flash (the smaller model) maintains perfectly stable beliefs across all probes — zero correct edges lost. Its larger sibling, Gemini 2.5 Pro, builds a reasonable map early on, then catastrophically collapses, losing 12 correct edges in a single probe step. Gemini 3 Flash shows pure recency bias — each probe reports only the last 3-5 components it examined, as if the model treats each probe as “summarize the architecture from scratch” rather than “update your running belief.”
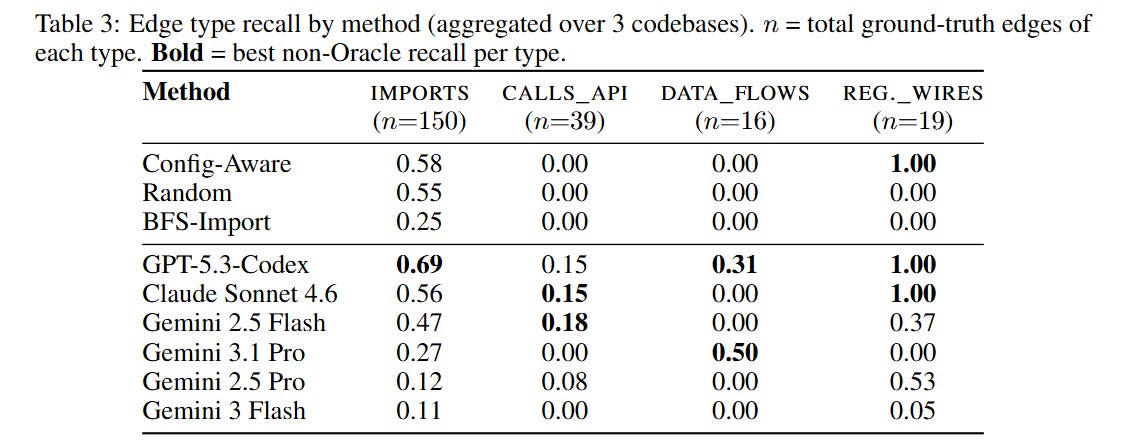
#4. LLMs discover edge types that baselines can’t. Rule-based strategies (follow imports, read config files) find at most two of the four edge types. LLM agents collectively find all four, including DATA_FLOWS_TO edges that require multi-hop reasoning through the orchestration code. That said, the two strongest LLMs only beat baselines by 9-10 F1 points, and weaker LLMs score below simple heuristics.
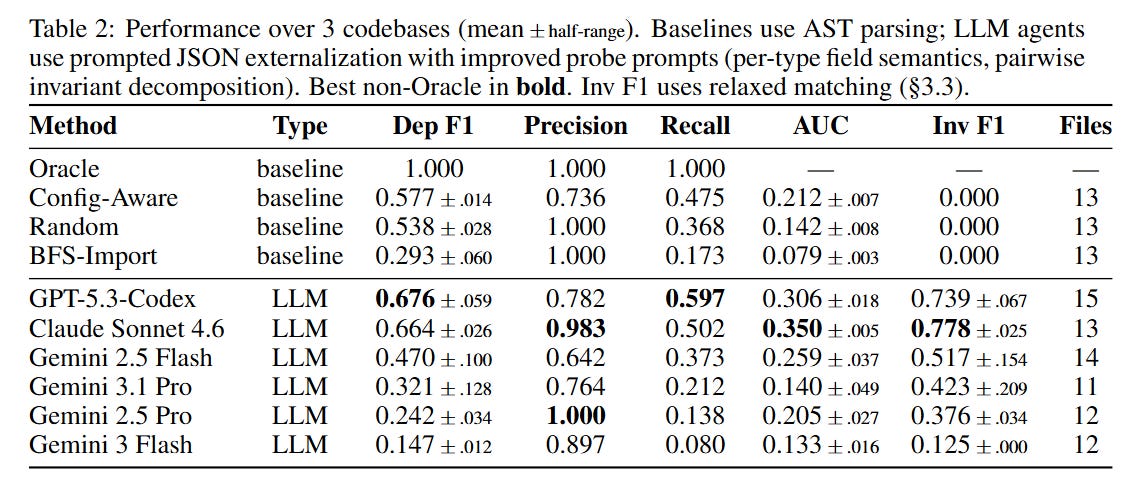
#5. Agents can discover architectural constraints — but only if you ask precisely enough. We plant 15-16 constraints per codebase (forbidden dependencies, interface-only access rules, validation chains) and test whether agents find them. With our initial prompt, every model scored zero. After adding per-type field definitions and worked examples, the top models jumped to invariant F1 of 0.78 (Claude) and 0.74 (GPT). Baselines score zero regardless — they can't reason about cross-cutting constraints at all. This was one of our most instructive findings: what looked like a model capability gap turned out to be a prompt specification gap. It's a warning for anyone building belief-probing benchmarks.
Where this needs to go
The current benchmark is deliberately narrow: one architectural pattern (Pipeline), one language (Python), three codebases, single runs per model. It’s a v0.1 — enough to show the framework works and produces interesting signal, but far from a comprehensive evaluation.
What I’d like to see in future versions:
More architectural patterns — event-driven, microservices, plugin systems, hexagonal architecture. Different patterns create different edge type distributions and different challenges.
More languages — TypeScript and Go at minimum. The harness is language-agnostic; the generator needs new templates.
Larger and more complex codebases — our current medium tier (25-40 files) is where the signal is, but real codebases are 10-100x larger.
The REVISE phase — presenting evidence of architectural changes and testing whether agents can update their beliefs. The framework supports it; we haven’t run the experiments yet.
Manually curated real-world codebases — procedural generation gives controlled ground truth but may miss the messiness of organic code. A hybrid approach (generated + curated) would be stronger.
Documentation as a discovery channel — real codebases have READMEs, Architecture Decision Records (ADRs), architecture docs that are often stale. Testing whether agents read docs vs. dive into code, and how they handle contradictions between docs and reality.
The paper and the code
I’ve published this as a paper on arxiv: Theory of Code Space: Do Code Agents Understand Software Architecture?
It’s explicitly labeled as work in progress. The LLM results are preliminary — single run per model-codebase pair, single prompt design, one pattern. The goal of this phase is to build and debug the benchmark, not to produce definitive model rankings. The results will change with different prompts and setups — our own prompt ablation showed that a single prompt change moved one model’s F1 by +0.14 while barely affecting another (+0.01).
The complete toolkit is open-source: github.com/che-shr-cat/tocs
It includes the codebase generator, partial observability harness, evaluation pipeline, and scoring metrics. You can run it on any model that supports tool-use or multi-turn conversation.
An invitation
I’d love contributions from the community:
Run additional models. Open-weight models (Llama, Qwen, DeepSeek) would be especially interesting. The more models we test, the better we understand what drives the capability differences.
Contribute codebase patterns. The generator is template-based — adding a new architectural pattern means writing a new template. If you understand event-driven or microservice architectures well enough to formalize them, I’d love a PR.
Help improve scoring. Our current strict matching penalizes models that report correct relationships at the wrong granularity. More forgiving scoring (partial credit, normalized matching) would give a fairer picture.
Run repeated experiments. Everything I’ve reported is single-run. Repeated runs with variance estimation would make the findings much more robust.
If you’re interested in collaborating — especially if you’re at a company building code agents or developer tools — reach out. The benchmark is most useful when tested against the agents that will actually be deployed in production.
The broader question this work probes: do our code agents have any real understanding of the systems they modify, or are they just very good at local pattern matching? The answer, based on preliminary evidence, is “it depends on the model, and it’s more nuanced than expected.” That seems worth investigating further.
Paper: arxiv.org/abs/2603.00601 Code: github.com/che-shr-cat/tocs