
[DeepMind SIMA] Scaling Instructable Agents Across Many Simulated Worlds

Authors: The SIMA Team
Paper: here
Post: https://deepmind.google/discover/blog/sima-generalist-ai-agent-for-3d-virtual-environments
DeepMind has developed a new agent, SIMA (Scalable, Instructable, Multiworld Agent), that learns to follow arbitrary language instructions and act in any virtual 3D environment using keyboard and mouse commands.
SIMA
The approach to the task was broad and general. The environments are rich, containing hundreds of objects and allowing numerous interactions. They are asynchronous, meaning the environment does not wait for the agent's action; life there moves on its own. There is no access to the internals of the environment; the agent perceives pixels from the screen and implements actions through the keyboard and mouse commands, like a human, with no APIs. The agent does not try to maximize score; it must follow arbitrary language instructions, not a set of predefined commands. Each game requires a GPU, so running hundreds or thousands of agents for an experiment is not feasible.

With such premises, learning is harder, but it's easier to expand the agent to new environments.
Unlike some early works like Atari or Starcraft 2, the focus here is specifically on 3D physical embodiment. This is either first-person or third-person with a over-the-shoulder pseudo-first-person view. It's important to have the possibility for rich and deep language interactions.
Commercial games (Goat Simulator 3, Hydroneer, No Man’s Sky, Satisfactory, Teardown, Valheim, Wobbly Life) and artificial research environments on Unity (Construction Lab, Playhouse, ProcTHOR, WorldLab) are used.

The training approach chosen is behavioral cloning, i.e., supervised learning on human actions (keyboard and mouse) based on input observations (screen pixels). The dataset also includes language instructions, dialogues, and various annotations and markers of success or failure. The article features a beautiful picture with hierarchical clustering of instructions by embeddings.

The dataset was collected in various ways. For example, recording a person's gameplay and then annotating it with text instructions. Or in a two-player game, one played and everything was recorded, while the other gave instructions.
No humans were harmed during the experiment. “The full details of our data collection protocols, including compensation rates, were reviewed and approved by an independent Human Behavioral Research Committee for ethics and privacy. All participants provided informed consent prior to completing tasks and were reimbursed for their time.“
There was some preprocessing with filtering out low-quality data, resizing everything to the agent's input size, weighting, and shuffling observations to prioritize the most effective ones. The focus was on instructions that could be completed in no more than 10 seconds.
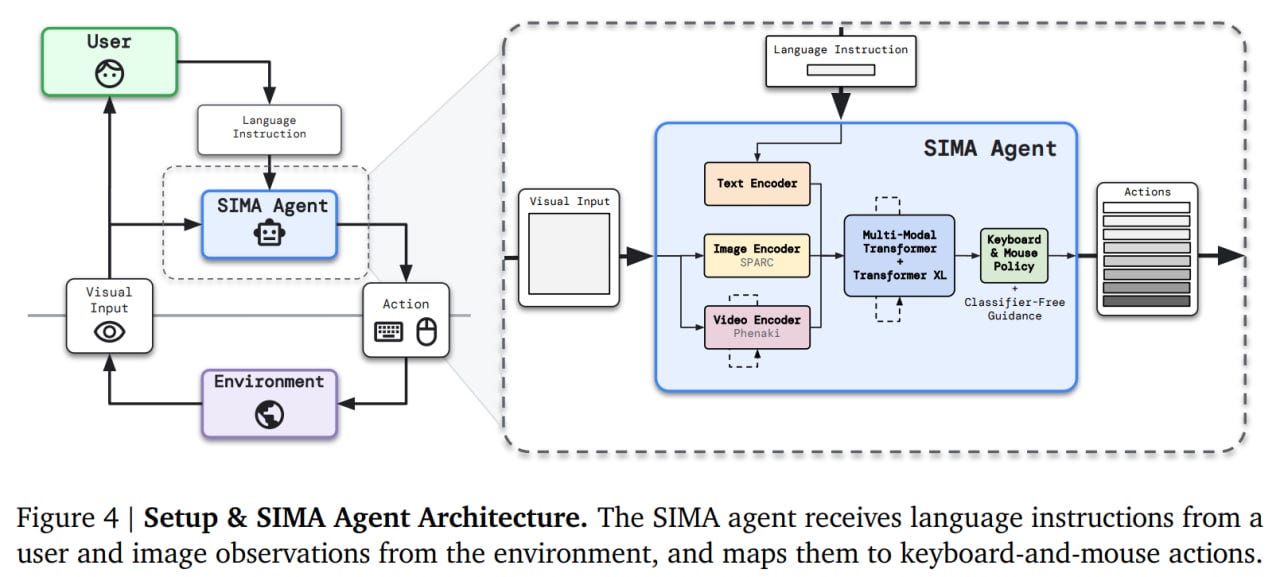
The agent uses pretrained models. These are the text-image SPARC (SPARse Fine-grained Contrastive Alignment, https://arxiv.org/abs/2401.09865), and the predictive video model Phenaki (https://arxiv.org/abs/2210.02399). Both are further fine-tuned, the first through behavioral cloning, the second through video prediction. It's unclear what the text encoder entails; it seems to be trained from scratch, which is odd — Google has many good language models that would be a sin not to use.
Inside, there's a multimodal transformer and the good old Transformer-XL (https://arxiv.org/abs/1901.02860), which attends to past memory states and builds a state representation. This state representation is then sent to a policy network, producing keyboard and mouse actions for a sequence of 8 actions.
The agent is trained on behavioral cloning, but there is also an additional (auxiliary) objective in the form of predicting goal achievement.
Classifier-Free Guidance (CFG, https://arxiv.org/abs/2207.12598) is also used to improve text-conditioning. The policy is calculated "with" and "without" language conditioning, and then the policy logits are shifted towards the obtained difference:
𝜋𝐶𝐹𝐺 = 𝜋 (image, language) + 𝜆 (𝜋 (image, language) − 𝜋 (image, ·)) .
Training details: architectures, dataset sizes, hyperparameters, training time — nothing is known. Probably some development of the multimodal transformer from the work “Imitating Interactive Intelligence” (https://arxiv.org/abs/2012.05672) with LSTM replaced by Transformer-XL?
Evaluation
Evaluating the resulting agent is not easy. The success criterion is often unavailable, especially in commercial games, and they are not designed for reproducible benchmarks. Or the agent may perform an action not because of the text instruction, but because that's how the environment is structured — ideally, the task should allow for multiple actions. Somewhere, OCR is needed to read game messages. And so on, there are many difficulties.
There's also an important issue with latency. Since the agent and the world are asynchronous, this must be taken into account both in training (predicting actions with a time shift) and in not creating additional delays during evaluation.
In the end, they evaluated 1) relative to ground truth (for research environments where this can be obtained), 2) through success detection using OCR, or 3) by a human (slow and expensive).
The results are interesting.
First, SIMA manages to achieve goals in various environments. Not with a 100% result, but quite decently. Some environments are easier than others.

They also clustered by types of actions, here too the performance varies quite significantly.

Ablations were conducted. In addition to the standard SIMA, there was also a zero-shot mode with training on one less environment and evaluating on it. There was a variant without pretrained encoders (ResNet instead of SPARC/Phenaki), a variant without language inputs, and a variant with training only on that specific environment (specialist agent). Almost all agents were trained for 1.2M steps.
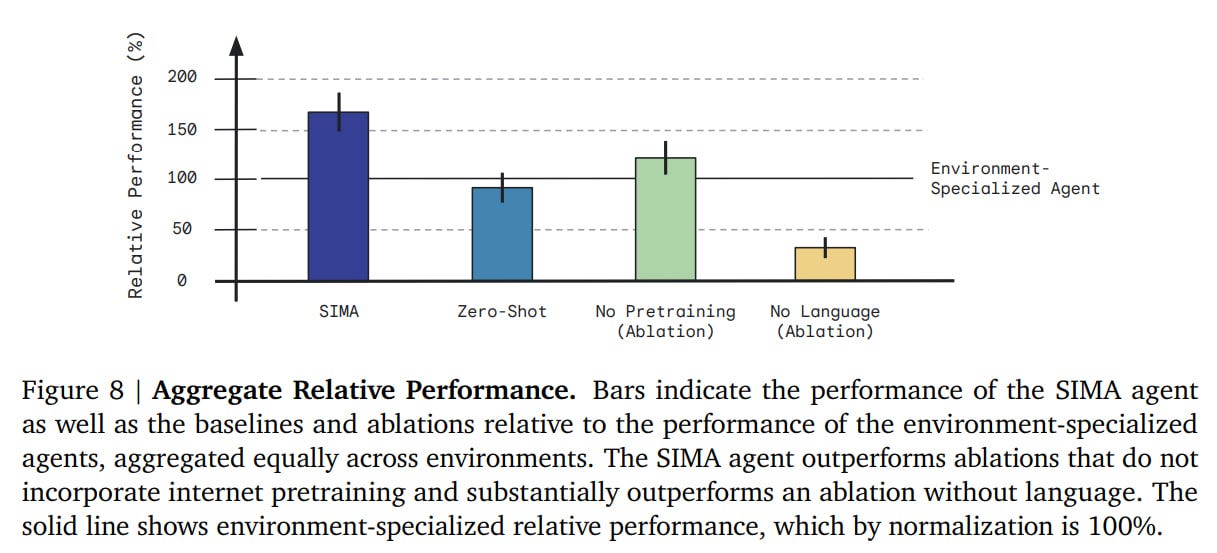
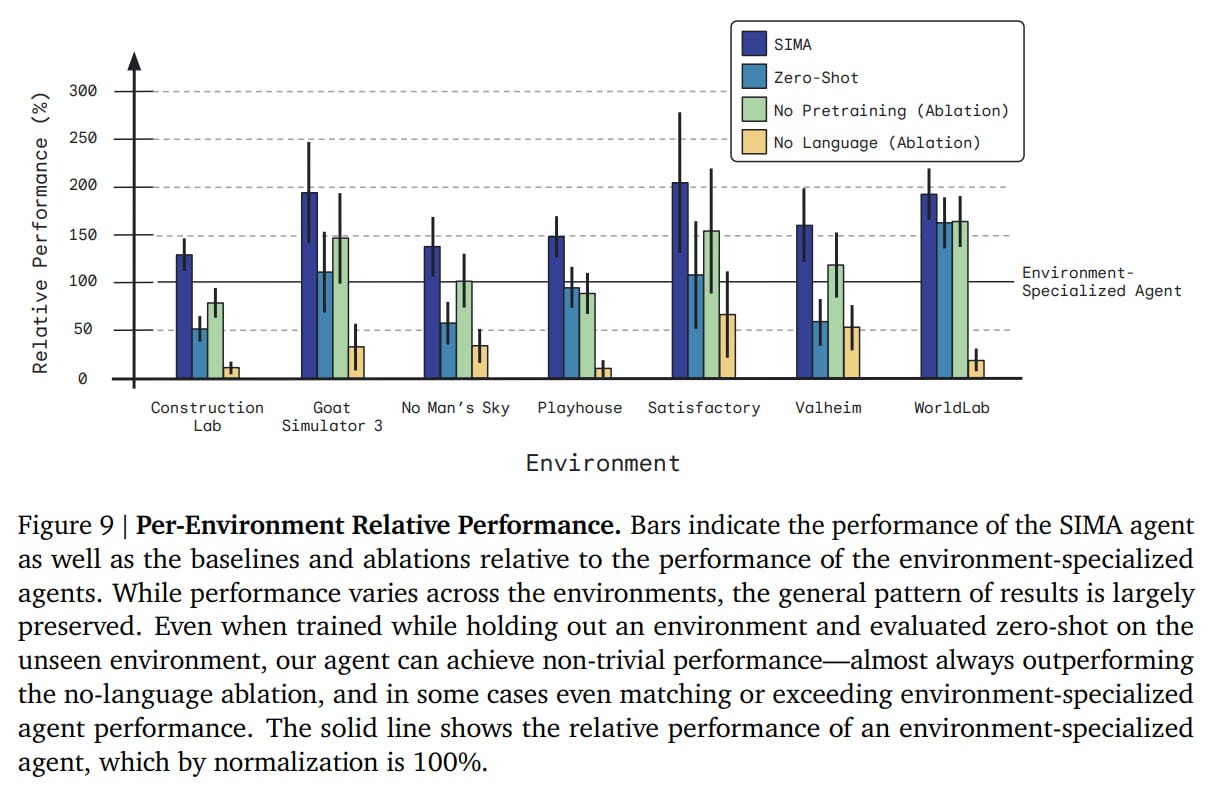
The specialist was beaten everywhere, which is cool. Other baselines were also significantly beaten. Zero-shot lags behind significantly, but still has a decent result, not far from the specialist. Without CFG it's worse, but without language, it's significantly worse.
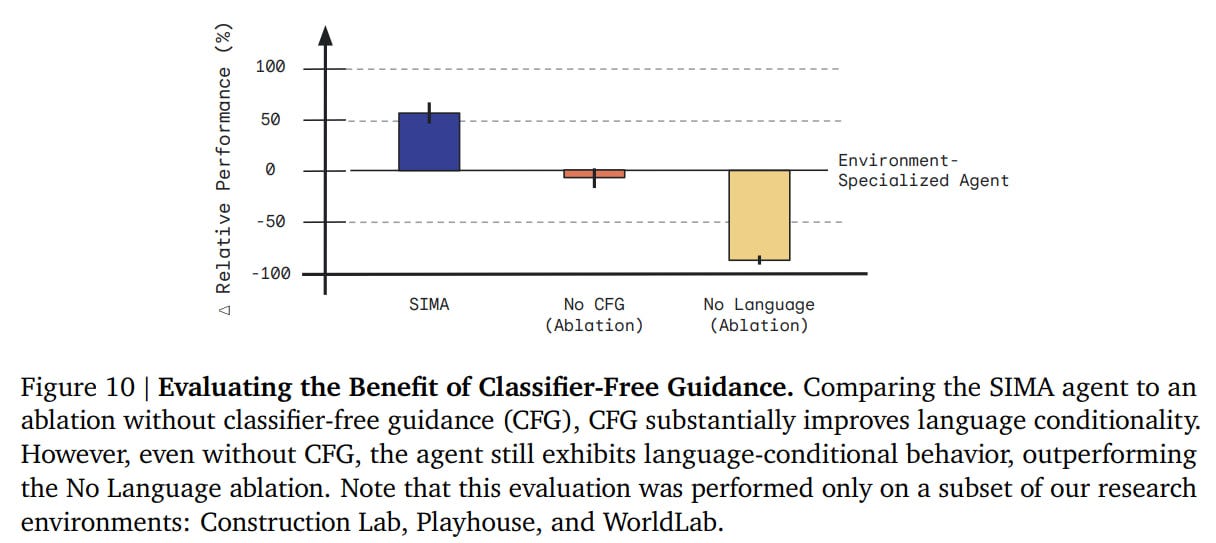
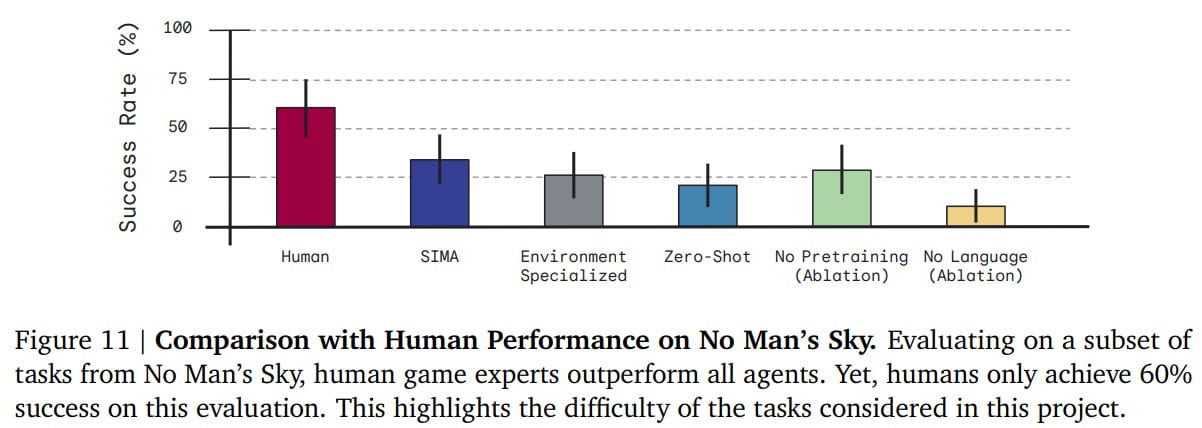
There was also a separate comparison on other tasks from No Man’s Sky. Humans have about a 60% success rate on these tasks, SIMA 34%, which is noticeably higher than the baselines.
In general, there's still work to be done, but the result is interesting and promising. There's clearly knowledge transfer between environments, and zero-shot is quite decent.
SIMA is still a work in progress, the results are preliminary. In the future, they promise to scale to a larger number of environments and tasks, improve stability and controllability of agents, use fresh cool pretrained models, and work more on evaluations. SIMA should be an interesting model for researching the grounding of abstract language model capabilities in embodied environments. We look forward to developments.
P.S. You can support the project here patreon.com/GonzoML