
🤘ACDC (not that one)
Towards Automated Circuit Discovery for Mechanistic Interpretability

Title: Towards Automated Circuit Discovery for Mechanistic Interpretability
Authors: Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, Adrià Garriga-Alonso
Paper: https://arxiv.org/abs/2304.14997
Code: https://github.com/ArthurConmy/Automatic-Circuit-Discovery
A fascinating paper from NeurIPS 2023 introduces methods for automating circuit discovery in neural networks, including an algorithm called Automatic Circuit DisCovery (ACDC) 🤘.

Let's dive into what this means for AI interpretability.
Mech interp workflow
In mechanistic interpretability (mech interp), researchers typically follow a three-step workflow:
1) First, you identify specific model behavior you want to study, gather prompts that demonstrate this behavior, and choose appropriate metrics. While we call this a dataset, it's important to note that no training happens here — it's purely for analysis. The clearer you define the target behavior, the easier it becomes to work with it.
2) Next, you select the granularity level for your investigation. This could be tokens, attention heads, specific Q,K,V activations, individual neurons, or interactions between them. The result is a directed acyclic graph (DAG) of interconnected nodes.
3) Finally, you search for edges in this graph that form the circuit you're interested in. Edges are verified through recursive activation patching: you corrupt some activation (by overwriting it with zero, the dataset mean, or better yet, a value from another example to stay within the expected range), perform a forward pass, and compare the model's output using your chosen metric. This helps eliminate parts that don't affect the behavior. You start from the output activation and work your way deeper.
The current work fully automates the third step.
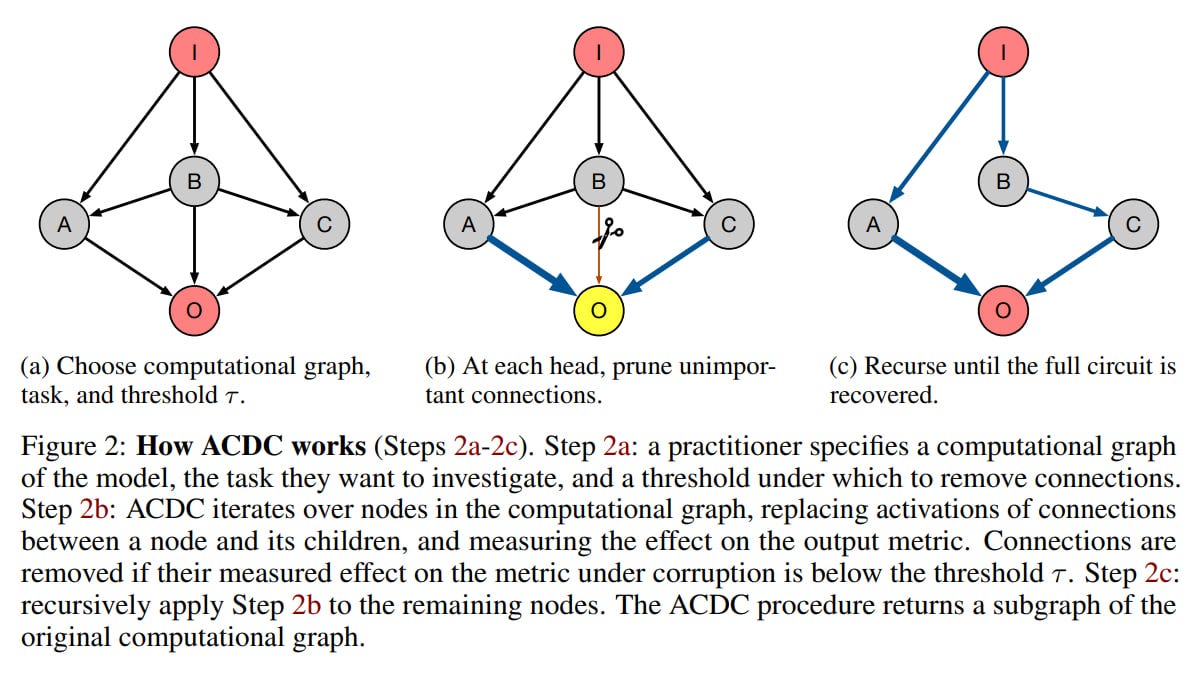
ACDC
The setup requires a set of prompts demonstrating your chosen task and a set of negative prompts without this behavior. Activations from negative examples are used for activation patching.

ACDC iterates from outputs to inputs in the computation graph, starting with the output node (nodes are topologically sorted in reverse order). At each node, the algorithm tries to remove as many incoming edges as possible while maintaining model performance on the chosen metric. Performance degradation is evaluated using KL-divergence, and an edge is removed if the change is below a specified threshold τ>0. The procedure outputs a sparse graph that still performs well on the chosen task. You could think of this as task-specific pruning, which might be interesting for other applications too.
The practical results are intriguing. For the GPT-2 small (124M parameters) on the Indirect Object Identification (IOI) task, the discovered subgraph contains 1,041 edges. Note that edges here represent attention heads (split into Q, K, V) and MLP components, not individual weights. The paper mentions that the model has 32,923 edges in total.

Alternatives to ACDC exist, including Subnetwork Probing (SP) and Head Importance Score for Pruning (HISP).
Evaluation
The researchers evaluated their method against two key questions:
Q1. Does the method identify subgraphs corresponding to the underlying algorithmic behavior of the neural network?
Q2. Does the method avoid including components not involved in the studied behavior?
These questions map to high true-positive rate (TPR) for Q1 and low false-positive rate (FPR) for Q2, which can be evaluated using ROC curves.

The authors used previously discovered canonical circuits as ground truth and treated it as a binary classification problem for each graph edge.

They tested various values of the τ hyperparameter for ACDC and hyperparameters of other methods (SP and HISP). While ACDC's ROC AUC looks good, it's not entirely stable and fails in certain settings.

All methods show sensitivity to corrupted distributions. Some tasks require specialized approaches with specific distributions and metrics, suggesting room for improvement.

One fundamental issue is that these methods optimize for a single metric and systematically miss internal model components, particularly "negative" components that hurt performance. For instance, in the IOI task, they missed Negative Name Mover Heads and Previous Token Heads. Lowering the threshold finds these components but also discovers many others not identified in the original work.

Another challenge with TPR/FPR evaluations lies in the quality of reference circuits, which likely include unnecessary components.
In conclusion, while not a perfect automatic solution — it doesn't find everything and requires task-specific tuning — it's still a helpful tool. Beyond IOI, the paper demonstrates discovered graphs for tasks like Greater-Than, Docstring, tracr, Induction, and Gendered pronoun completion.


They also discuss challenges in finding OR gates, as ACDC typically discovers only one of the two inputs.

Working with these circuits is quite a challenge, indeed...