

Open-Endedness is Essential for Artificial Superhuman Intelligence
Open-Endedness is Essential for Artificial Superhuman Intelligence

Authors: Edward Hughes, Michael Dennis, Jack Parker-Holder, Feryal Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, Tim Rocktaschel
Paper: https://arxiv.org/abs/2406.04268
It’s great to see new papers on the not so mainstream topic of open-endedness. If you didn’t hear such term, here’s a great introduction by Kenneth O. Stanley, Joel Lehman and Lisa Soros, “Open-endedness: The last grand challenge you’ve never heard of”.
A bold statement: “In this position paper, we argue that the ingredients are now in place to achieve open-endedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI).”
The new definition
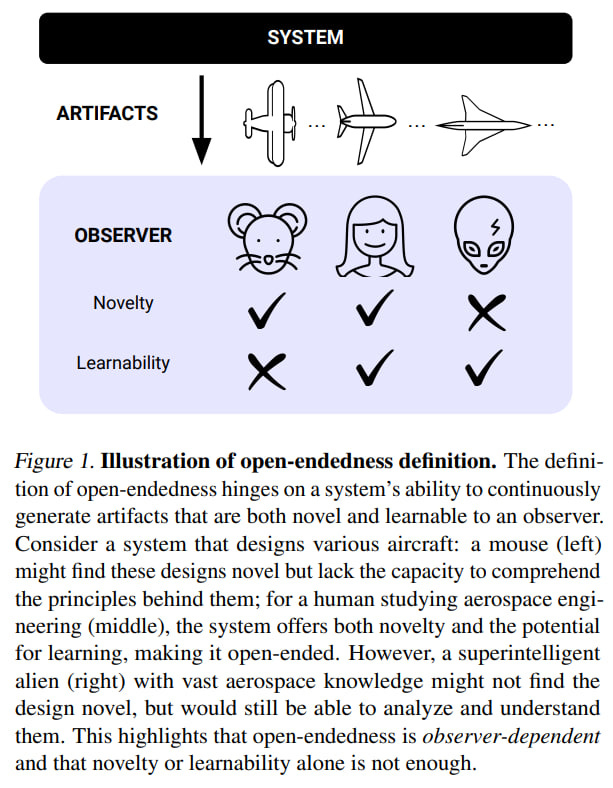
The authors approach this from the standpoint that it is important to quantify and formalize open-endedness. They introduce the concept of an observer and state that from their perspective, a system can be considered as open-ended if and only if the sequence of artifacts it produces is novel and learnable. The original formulation of the definition is: "From the perspective of an observer, a system is open-ended if and only if the sequence of artifacts it produces is both novel and learnable."
More formally, system S produces a sequence of artifacts X_t, where t is time. Observer O is a statistical model that evaluates the predictability of artifact X_T based on the history of previous artifacts X_{1:t}. The quality of the prediction is evaluated by a certain loss function ℓ(t, T).
Novelty is defined as the steadily increasing unpredictability of artifacts by the observer model at any fixed time t. That is, the expected loss for later artifacts is higher.
Learnability is present in the system when the loss for artifacts decreases as the observer is provided with a longer history.
Therefore, for the observer, the system is open-ended if it generates a sequence of novel and learnable artifacts. This can be described as “we’ll be surprised but we’ll be surprised in a way that makes sense in retrospect.”

In the classic example of a TV constantly showing random noise, which many types of agents can potentially get stuck on, this TV would be learnable (in the sense that the agent will learn the specific distribution) but over time, novelty would be lost. Epistemic uncertainty will fade, leaving only what is called aleatoric uncertainty (see here for different types of uncertainty) regarding irreducible randomness in the data, but even that will collapse due to expectation.
In the example of the same TV, but where programs are also externally switched to channels with different noise distributions, at each moment of channel switching the observer will have novelty, but since the history of observations now doesn’t help much (the loss will not decrease, new channels generate different noise), learnability is lost.
Interestingness is not explicitly mentioned in the description but is set through the choice of the loss function. Interesting parts of artifacts are those features that the observer has chosen as useful for learning.
There are other definitions of open-endedness (among recent ones, for example, “A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents” https://arxiv.org/abs/2311.00344, which also features an observer) as well as many other related ideas (covered in Appendix C).
The observer is a separate large and important topic. Traditionally, we have a large class of observers called "humans." But the current definition allows for other observers, for example, to cover non-anthropocentric open-ended systems (like biological evolution). This also allows for reasoning about open-ended systems that surpass humans (ASI). It also allows us to determine whether a system is open-ended relative to any observer.
Since the observer has a certain time horizon τ, limiting their observations of the system, different systems can be open-ended on different time scales. If a system remains open-ended on any time horizon (τ → ∞), we call it infinitely open-ended. Otherwise, it is finitely open-ended with a time horizon τ relative to observer O. For example, the Adaptive Agent (AdA from “Human-Timescale Adaptation in an Open-Ended Task Space” https://arxiv.org/abs/2301.07608) is finitely open-ended with a horizon of about 1 month (novelty plateaued after this training time due to the limited richness of tasks and the size of the agent's network).
The cognitive abilities of the observer also matter; they might simply lack memory and start to forget old observations (it’s good to be able to compress well!), so from their point of view, the system will stop being open-ended. This is easier to manage in narrower domains (in ours, it feels things are getting more complex…).
Examples
The paper examines several well-known agents from the perspective of a human observer.
The first archetypal example is AlphaGo, which is novel (finding new unexpected moves) and learnable (humans can learn new policies from it and improve their loss). It is open-ended (thanks to self-play?) and is also an example of narrow superhuman intelligence (according to the classification from “Levels of AGI for Operationalizing Progress on the Path to AGI” https://arxiv.org/abs/2311.02462).
Another example is the previously mentioned AdA, which solved tasks in 3D environments XLand2 and constantly demonstrated new abilities (zero-shot/few-shot abilities in environments where it had not trained). It relies on algorithms for unsupervised environment design (UED) with an automatic curriculum and environment selection in the zone of proximal development according to Vygotsky. However, in AdA's training, a plateau was noted, so if an order of magnitude more compute is poured in, AdA will likely cease to be open-ended. To fix this, richer environments and more complex agents are needed to support the co-evolution of the environment and the agent in UED.
The third example is POET (“Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions” https://arxiv.org/abs/1901.01753). Here, a population of agents is trained, each associated with an evolving environment, periodically transferring agents to new environments. These artifacts in the form of agent-environment pairs are open-ended relative to a human observer who models the emerging features of the environment and the agent's capabilities. There is both novelty (due to mutations in the Quality Diversity algorithm generating new unexpected environments) and learnability (because the mutations are small and the history of past environments provides clues to the properties of the current one). As in AdA, the main limitation on open-endedness is the parameterization of environments—the agent reaches a plateau when all landscapes are solved.
The final example is modern foundation models. It is a negative one because they are trained on fixed datasets, and the observer will eventually learn all epistemic uncertainty. They may appear open-ended to a human over a sufficiently broad domain due to human memory limitations, but if the focus is narrowed, the problems become noticeable.
BUT! According to the authors, adding open-endedness to foundation models paves the way to ASI, and the fact that models are conditioned by context breaks the logic of the impossibility of being open-ended—the context, in principle, allows recombining concepts in an open-ended way.
Ways to Open-Ended Foundation Models
According to the authors, the trend of improving foundation models through scaling and training on passive data will soon plateau and is insufficient by itself to achieve ASI (not insufficient in the sense of impossible, but in the sense of unlikely, because open-endedness by its nature is an experiential process).
Only a few steps remain to achieve open-endedness in foundation models, and the fastest path to ASI will be inspired by the scientific method (with its hypotheses, falsifications through experiments, and codification of results into new knowledge) and compiling a dataset online through a combination of foundation models and open-ended algorithms.
Among promising directions, the following stand out (and the authors also refer to other paths from other authors, among which Assembly theory is noted):
Reinforcement Learning: One of the interesting recent examples of how an RL-like self-improvement can be wrapped over an LLM is “Voyager: An Open-Ended Embodied Agent with Large Language Models” (https://arxiv.org/abs/2305.16291). Other examples show how LLMs can guide agents, providing rewards or compiling a task curriculum.
Self-Improvement: Actively engaging in tasks that expand the agent's knowledge and abilities, for example, through the use of tools (“Toolformer: Language Models Can Teach Themselves to Use Tools“ https://arxiv.org/abs/2302.04761) or communication with other agents. There are many examples where models can be used for feedback instead of people (e.g., Constitutional AI https://arxiv.org/abs/2212.08073), suggesting the path of using models to generate their own samples and update in an open-ended mode.
Task Generation aka “The Problem Problem” (“Autocurricula and the Emergence of Innovation from Social Interaction: A Manifesto for Multi-Agent Intelligence Research” https://arxiv.org/abs/1903.00742) on how to generate many interesting environments useful for agent training. Alternatively, train world models in which the results of actions can be simulated. They can be combined with multimodal reward models to generate an open-ended curriculum.
Evolutionary Algorithms: LLMs can act as selection and mutation operators, starting with the design of prompts (already working better than humans in some cases). An interesting topic is the evolution in code spaces (see Eureka or FunSearch). The open question is how to transition from code for special domains to more general ones.
In all these sections, and indeed throughout the work, there are numerous references on the topic, deserving close study by themselves. The paper also contains many interesting thoughts along the way that I have not attempted to convey in this overview.
Responsible ASI
A separate chapter addresses the risks and responsibilities in the context of ASI.
Open-ended systems by design can and will lead to new possibilities, including dual-use capabilities. This is particularly dangerous if the system itself can perform actions in the environment. Exploration can be very aggressive, and here are all the problems of AI agency including goal misgeneralization (“Goal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals“ https://arxiv.org/abs/2210.01790) and specification gaming.
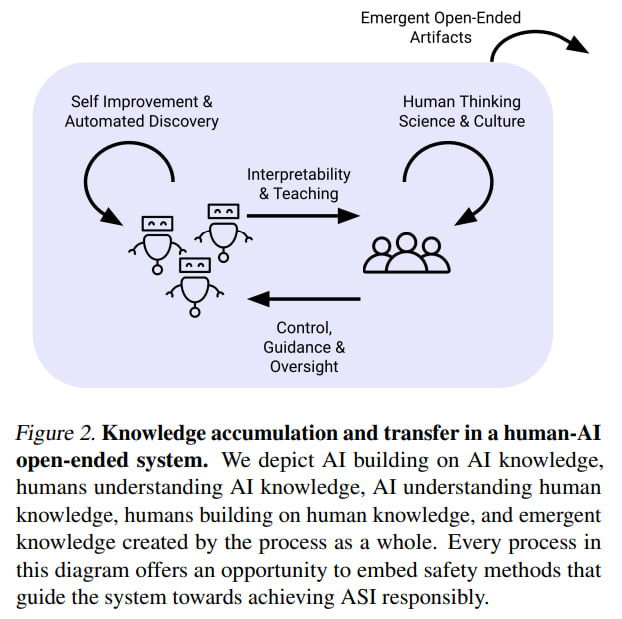
The artifacts produced by the system may become incomprehensible to humans, and in this sense, the system will cease to be open-ended for humans according to the current definition because it will cease to be learnable. To remain useful for humans, they must be understandable. There is a lot of scope for work on interpretability and explainability.
A separate question is whether humans can direct open-ended systems since such systems may not have well-defined objectives and be unpredictable. Some variants of human-in-the-loop or open-endedness from human feedback are possible. Besides being directed, the system should draw human attention to unexpected and potentially important artifacts. But this is a big question—how to combine directability and open-endedness.
A major non-technical question is how society adapts to open-ended models. Mechanisms need to be put in place to avoid various tipping points, so there isn’t another situation like The Flash Crash.
Additionally, even if individual components of a human-AI open-ended system are safe, the entire system can lead to unforeseen problems.
In general, there are many questions, but the future can be quite interesting. We may not be very far from it.