

Dejavu Transformers
Dejavu Transformers
Déjà Vu Innovations: Are Transformers Evolving or Just Revolving?

TransformerFAM: Feedback Attention as Working Memory
Authors: Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, Pedro Moreno Mengibar
Paper: https://arxiv.org/abs/2404.09173
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Authors: Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
Paper: https://arxiv.org/abs/2404.07143
Two somewhat similar papers were released by Google, written by different sets of people but likely by one group, as many authors are shared across another related publication https://arxiv.org/abs/2403.19709.
Both papers discuss transformers capable of processing sequences of unlimited length.
TransformerFAM
The first paper introduces a transformer with Feedback Attention Memory (FAM) that applies an attention mechanism to its own latent representations through feedback. Each layer's representations are fed back into it for processing the next token. The authors believe this leads to the emergence of working memory within the transformer.
They describe this as Block Sliding Window Attention (BSWA), similar to Longformer (https://arxiv.org/abs/2004.05150), where each block includes virtual activations from FAM. The attention mechanism now focuses on the current block, several previous segments (memory), and the previous FAM (working memory, where potentially everything can accumulate indefinitely). Then, for the current block, a new FAM is computed through attention to its outputs and the previous FAM, effectively compressing and updating the memory. This conceptually resembles memory tokens (https://arxiv.org/abs/2006.11527, or rather a recurrent version here https://arxiv.org/abs/2207.06881) proposed by Mikhail Burtsev et al. long ago, but with a more sophisticated mechanism of calculation.

This is similar to many known concepts. Transformer-XL also had memory in the form of previous segments and could access activations from lower levels from the past. TransformerBSWA is almost the same, except unlike XL, it does not use a "stop gradient" on the memory segment. In TransformerFAM, we are essentially accessing activations from the same level.
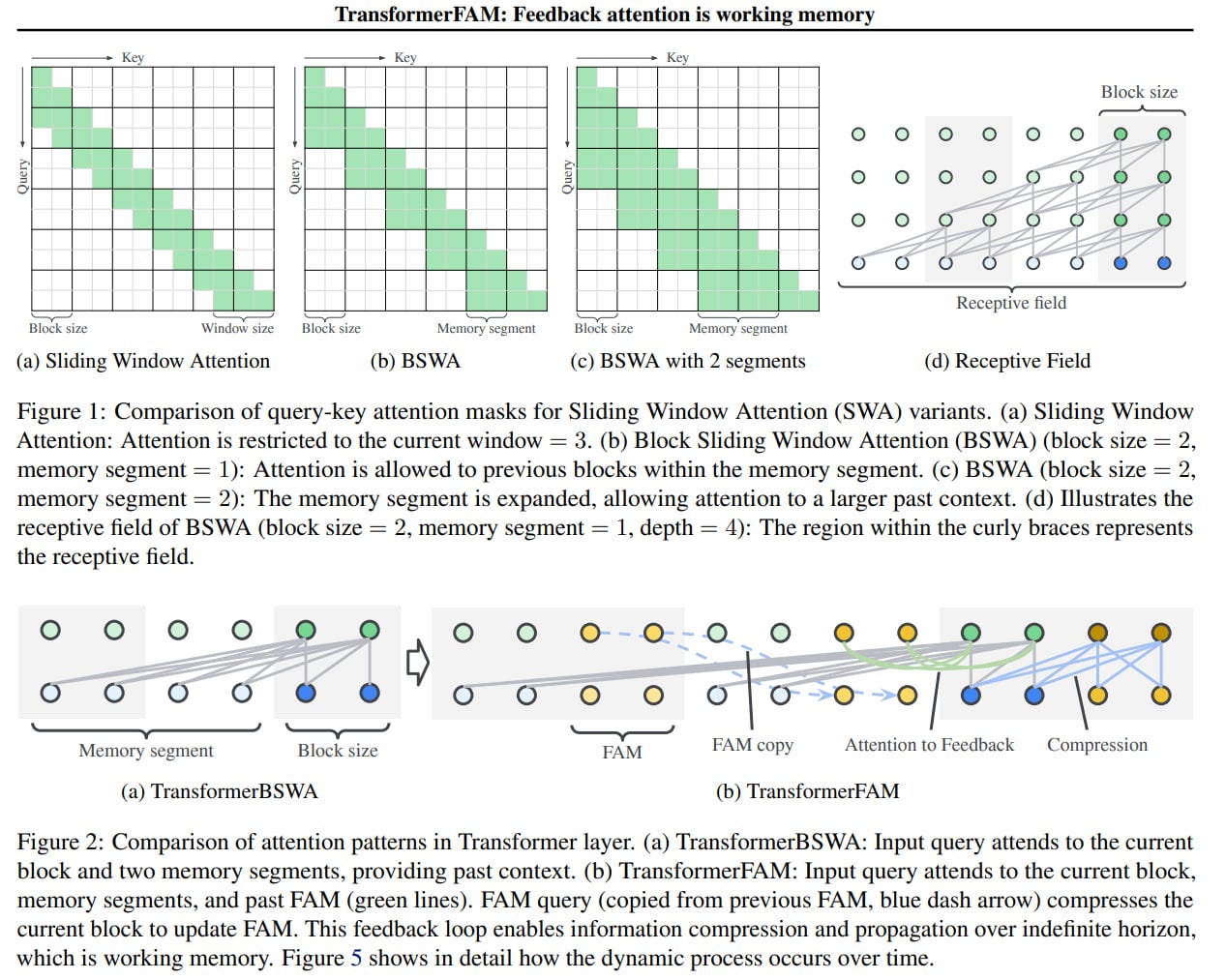
Implementation is achieved without adding new weights to transformer layers, operating on the concatenation of block inputs and FAM, as well as modifying the attention mask to implement FAM. At least, if I understood it correctly. They experimented with blocks of length 1024 + FAM of length 64. A tricky topic is how to initialize the initial FAM, which they did through prompt tuning.

For experiments, they used Flan-PaLM models (1B, 8B, 24B), to which they added BSWA or FAM and fine-tuned using LoRA. They also compared it with Transformer-XL, but it was indistinguishable from BSWA in results.
They tested on the retrieval task PassKey, comparing FAM with various numbers of memory blocks (M1-M12), and FAM outperformed all. They also tested it on a slew of long-context demanding tasks used in evaluating Gemini. Here, FAM consistently beats BSWA, significantly in some cases and not so much in others.

So, it kind of works. But there are many questions.
First, something similar existed three years ago (Angela Fan, Edouard Grave, et al., https://arxiv.org/abs/2002.09402), but the authors relate this work (as well as Recurrent memory transformer, RMT, Mikhail Burtsev et al.) to the category where the top layer is linked to the bottom one, and there is no connection between intermediate neurons.

In the case of RMT, this is probably correct, but for Angela Fan's work, this is not quite true, as it aggregates representations of all levels:

So, in the current work, it's basically the same but without aggregation across all levels, only within the same level. Angela Fan's work is described inconsistently in two places (and both descriptions are incorrect):
"The first approach is linking the topmost layer to the bottommost (Fan et al., 2020; Bulatov et al., 2022). However, this cannot model feedback between interneurons, and this has only one global working memory."
"There have been attempts to incorporate feedback mechanisms into the Transformer, but most of them involve feeding the output activations from the top layer to the bottom (Bulatov et al., 2022; Chevalier et al., 2023) or to intermediate layers (Fan et al., 2020)."
This also resembles another older work by Edward Gref about Continuous Cache (https://arxiv.org/abs/1612.04426), then applied to RNN.
Another similar concept is DeepMind's Compressive Transformer (https://arxiv.org/abs/1911.05507), where memory accumulated within each layer:

Overall, this looks like a variation on a theme, and it's unclear why these works were given so little space or described as being quite different.
Second, it's nice that they compared it with BSWA, but it would be really interesting to compare it with all the aforementioned works. I bet it's no better because even relative to BSWA the difference isn't always noticeable. They could have tested Compressive Transformer, made within Google as well. About it, they said:
"There were papers that compressed information blockwise (Rae et al., 2019; Guo et al., 2019; Gupta & Berant, 2020; Mohtashami & Jaggi, 2023; Mu et al., 2023). However, in those papers, the information was not propagated infinitely"
I honestly don't understand why the information in the Compressive Transformer is propagated less infinitely than here. In details, the proposed mechanism certainly differs, but I wouldn't be surprised if mathematically it comes down to the same, there doesn't seem to be a conceptual difference. If someone smarter sees a difference, please highlight it.
Infini-attention
The second paper "Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention" (https://arxiv.org/abs/2404.07143) does something very similar. It explicitly adds compressive memory to the attention mechanism.

Regarding Compressive Transformer, the paper states:
"However, the previous segment-level compression methods, including Compressive Transformers (Rae et al., 2019) still discard the memory entries of old segments in order to free up space for the new ones, limiting their context window to the most recent segments. This is in contrast to our Infini-attention that computes incremental memory updates to a fixed amount of memory parameters in a recurrent fashion."

However, the original work on Compressive Transformer explicitly stated:
"The TransformerXL discards past activations when they become sufficiently old (controlled by the size of the memory). The key principle of the Compressive Transformer is to compress these old memories, instead of discarding them, and store them in an additional compressed memory."

There is no comparison with it, even on its native dataset PG19.

I didn't get the gimmick. It feels like we're now retelling old works with minor changes. These are like déjà vu transformers, for God's sake. Enlighten me if I'm missing something important in these works.